第一章 什么是git,为什么需要它?
什么是git?
git是一个版本控制的软件。
那什么叫版本控制呢?
版本控制是一种记录若干文件内容变化,以便将来查阅特定版本的修改情况。
通常版本控制管理的是源代码文本文件,实际上可以对任何类型文件进行版本控制(比如图形文件)。
优点:
有了版本控制,我们可以将某个文件回溯到之前的状态,甚至将整个项目都回退到过去某个时间点的状态。
我们可以比较文件的变化细节,找出谁最后修改了什么地方,从而造成整个项目出现怪异问题。
我们可以找出谁在何时报告了某个功能的缺陷。
就算搞砸了整个项目,把文件删的删,改的改,我们也可以轻松恢复到原先的样子,而无需额外增加什么工作量。
没有版本控制之前的开发状况
要充分体会版本控制软件的重要性,可以考察一下在没有版本控制之前的开发状况。
假设某位开发者A独立完成一个项目,在整个开发流程中,总是会增添新功能,扩展原功能,修复若干BUG等等。
为了不造成混乱,开发者A通常会将不同时期的项目,命名为版本1.0,2.0,3.0等等,然后用硬盘分别保存。
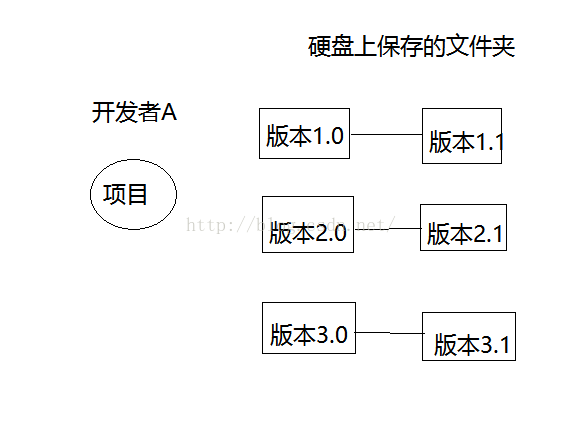
开发项目所要思考的细节是如此之多,类似于写代码注释一样,当源码文件逐渐增多后,我们也必须记录下文件改变的情况。
如果不记录,我们很难记得半个月之前,到底对项目进行了什么样的改变。
比如用readeME.txt或者用纸笔在本子上记录:
①某年某月某日,扩展了原模块input功能,添加了3个xxxx.c源码文件,放在D盘xx文件夹下。
②某年某月某日,增加了新模块table功能,增加了5个xxx.c源码文件,放在E盘xx文件夹下。
③某年某月某日,修复了模块search两个bug,备份其xxx.c源码文件,放在D盘xx文件夹下。
…………
…………
当项目比较简单时,这种工作还能应付,当项目稍微复杂一些时,就非常容易混乱。
如果项目遇到瓶颈或者重大bug,我们随时可能回溯到上一个安全运行,并通过测试的状态。
以前的记录就派上了大用场,通过记录我们就能找出哪一个备份,是安全运行,并通过测试的状态。
因为备份越来越多,又不敢随意删除任何文件(也许以后还会用到),整个项目规模膨胀,管理难度也越来越高。
别急,这还仅仅是一个开发者的情况,现代软件开发几乎都是团队协作模式。
假设有5个开发者,以上描述的情况会更加复杂,比如成员A修补了某个模块的bug,他必须保证其他4人的电脑上也同步修补该bug;
修补了bug是好事么?不一定,也许修补的这个bug会连锁影响到其他被扩展,被新增的模块上。
5名开发者之间互相沟通协作,他们各自的电脑必然充满了许多细节差异的备份。
当团队规模扩展到几十人层次时,某个文件或某个模块到底属于哪个小版本,经过了多少人的修改,到底使用哪一个备份,可能只有神仙才能搞清楚。
因此人们迫切需要一种机制,能解决以上的混乱情况,这就是版本控制软件诞生的背景。