测试minpy 调用gpu 加速numpy的矩阵相乘. 小矩阵相乘 1到100万个元 多次
这篇文章的测试不准确,可能是minpy和numpy同时用出的问题,现在最新的测试在下面这篇文章中
https://blog.csdn.net/DarrenXf/article/details/86305215
因为觉得这是整个测试过程,就没有删除这篇文章.
测试minpy 调用gpu加速numpy的矩阵相乘.小矩阵相乘,前面的文章中已经看到行数超过1000的方阵,基本上gpu就能起到加速效果.我们现在想知道的是具体的minpy 和numpy 性能的拐点.以此帮助我们决定使用cpu还是gpu. 具体结果测试应该是根据机器所不同的,我们这里的结果只是我们测试机的的结果.上一篇测试的时候只是测试了运行一次的时间,矩阵比较小时,
测试到的运行时间误差比较大,制作的图表应该说不是很准确. 并没有能看到我们期望的明显的规律.
这次还是用方阵,行数1-1000,元素数1-100万,这次图表的表示上用了元素数.
下面代码
main.py
#!/usr/bin/python
# -*- coding: utf-8 -*-
#####################################
# File name : main.py
# Create date : 2019-01-05 17:11
# Modified date : 2019-01-10 13:17
# Author : DARREN
# Describe : not set
# Email : [email protected]
#####################################
from __future__ import division
from __future__ import print_function
import os
import time
import numpy as np
import numpy.random as random
import minpy.numpy as mnp
import matplotlib.pyplot as plt
def create_path(path):
if not os.path.isdir(path):
os.makedirs(path)
def get_file_full_name(path, name):
create_path(path)
if path[-1] == "/":
full_name = path + name
else:
full_name = path + "/" + name
return full_name
def create_file(path, name, open_type='w'):
file_name = get_file_full_name(path, name)
return open(file_name, open_type)
def _plot_record(record,full_path):
_plot_a_key(record, full_path, "numpy", "minpy",)
_plot_key(record,full_path, "acceleration")
def _get_full_path(repeats, data_type, size_begin, size_end):
if not os.path.exists("./output"):
os.makedirs("./output")
path_str = "./output/%s_%s_%s_%s" % (repeats, data_type, size_begin, size_end)
return path_str
def _plot_a_key(record, full_path, name1, name2):
numpy_lt = []
minpy_lt = []
steps = []
for key in record:
steps.append([key])
steps.sort()
for i in range(len(steps)):
step_dic = record[steps[i][0]]
numpy_value = step_dic[name1]
numpy_lt.append(numpy_value)
minpy_value = step_dic[name2]
minpy_lt.append(minpy_value)
numpy_lt = np.array(numpy_lt)
minpy_lt = np.array(minpy_lt)
steps = np.array(steps)
steps = steps*steps
minpy_line, = plt.plot(steps, minpy_lt)
numpy_line, = plt.plot(steps, numpy_lt)
plt.legend(handles=[numpy_line,minpy_line],labels=['use numpy','use minpy'],loc='best')
full_path_name = "%s/%s_%s.jpg" % (full_path,name1, name2)
# plt.show()
plt.savefig(full_path_name)
plt.close()
def _plot_key(record, full_path, name):
acceleration_lt= []
steps = []
for key in record:
steps.append([key])
steps.sort()
for i in range(len(steps)):
step_dic = record[steps[i][0]]
acceleration_value = step_dic[name]
acceleration_lt.append(acceleration_value)
acceleration_lt = np.array(acceleration_lt)
steps = np.array(steps)
steps = steps*steps
acceleration_line, = plt.plot(steps, acceleration_lt)
plt.legend(handles=[acceleration_line],labels=['acceleartion'],loc='best')
full_path_name = "%s/%s.jpg" % (full_path,name)
# plt.show()
plt.savefig(full_path_name)
plt.close()
def test_numpy(A,B,i):
s = time.time()
np.dot(A,B)
e = time.time()
take_time = e - s
return take_time
def test_minpy(A,B,i):
s = time.time()
mnp.dot(A,B)
e = time.time()
take_time = e - s
return take_time
def _write_status(file_obj, A, B, i, numpy_take_time, minpy_take_time):
acceleration = numpy_take_time / minpy_take_time
shape_str = "%s : %s matmul %s" % (A.dtype, A.shape, B.shape)
numpy_str = "i:%s use numpy:%s" % (i, numpy_take_time)
minpy_str = "i:%s use minpy:%s" % (i, minpy_take_time)
acceleration_str = "acceleration:%s" % acceleration
file_obj.write("%s\n" % shape_str)
file_obj.write("%s\n" % numpy_str)
file_obj.write("%s\n" % minpy_str)
file_obj.write("%s\n" % acceleration_str)
print(shape_str)
print(numpy_str)
print(minpy_str)
print(acceleration_str)
def _record_status(record, i, numpy_take_time, minpy_take_time):
dic = {}
dic["numpy"] = numpy_take_time
dic["minpy"] = minpy_take_time
dic["acceleration"] = numpy_take_time / minpy_take_time
record[i] = dic
def averagenum(num):
nsum = 0.0
for i in range(len(num)):
nsum += num[i]
return nsum / len(num)
def test_numpy_and_minpy(repeats,data_type, size_begin, size_end):
random.seed(0)
record = {}
full_path = _get_full_path(repeats, data_type, size_begin, size_end)
file_obj = create_file(full_path, "output")
for i in range(size_begin, size_end):
A = random.randn(i, i)
B = random.randn(i, i)
if data_type == "float32":
A = np.array(A,dtype=np.float32)
B = np.array(B,dtype=np.float32)
numpy_time_lt = []
minpy_time_lt = []
for j in range(repeats):
numpy_take_time = test_numpy(A,B,i)
minpy_take_time = test_minpy(A,B,i)
numpy_time_lt.append(numpy_take_time)
minpy_time_lt.append(minpy_take_time)
avg_numpy_take_time = averagenum(numpy_time_lt)
avg_minpy_take_time = averagenum(minpy_time_lt)
_write_status(file_obj,A,B,i,avg_numpy_take_time, avg_minpy_take_time)
_record_status(record, i, avg_numpy_take_time, avg_minpy_take_time)
file_obj.close()
_plot_record(record,full_path)
if __name__ == '__main__':
repeats = 500
data_type = "float32"
for i in range(1,10):
size_begin = 100*i
size_end = 100*(i+1)
test_numpy_and_minpy(repeats, data_type, size_begin, size_end)
size_begin = 1
size_end = 1000
test_numpy_and_minpy(repeats, data_type, size_begin, size_end)
data_type = "float64"
for i in range(1,10):
size_begin = 100*i
size_end = 100*(i+1)
test_numpy_and_minpy(repeats, data_type, size_begin, size_end)
size_begin = 1
size_end = 1000
test_numpy_and_minpy(repeats, data_type, size_begin, size_end)
下面是我机器中的cpu和gpu型号
31.4 GiB
Intel® Core™ i7-8700K CPU @ 3.70GHz × 12
GeForce GTX 1080 Ti/PCIe/SSE2
64-bit
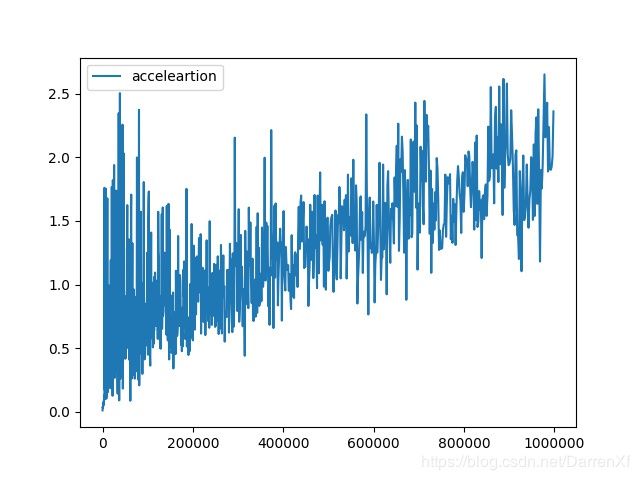
先看下整体输出效果
500_float64_1_1000
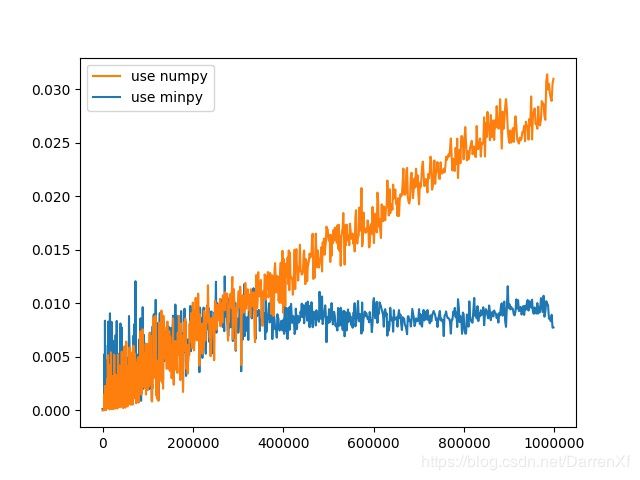
这个图可以看出来,numpy耗费的时间随着元素数量呈线性增长.而minpy基本上没有怎么变.可能minpy的时间主要花在矩阵的复制,赋值上面.计算上并没有使用太多时间.拐点出现在35万元素左右.大概的结论就是如果超过35万元素的float64矩阵运算用minpy能起到加速效果.当然这里只是针对我的机器.
然后是加速效果
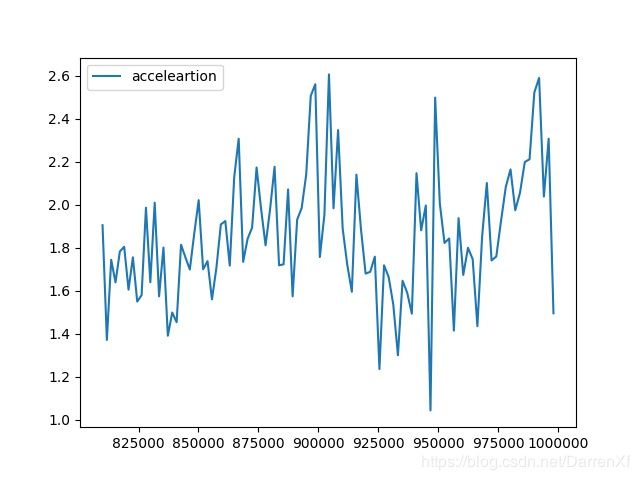
看这张图也是能得到上面的结论.而且还能看到加速的效果随着元素的增多也在呈线性增长.可以预计元素数目越多加速效果越好,也应该有拐点,我们这里没有能测试到.
500_float32_1_1000
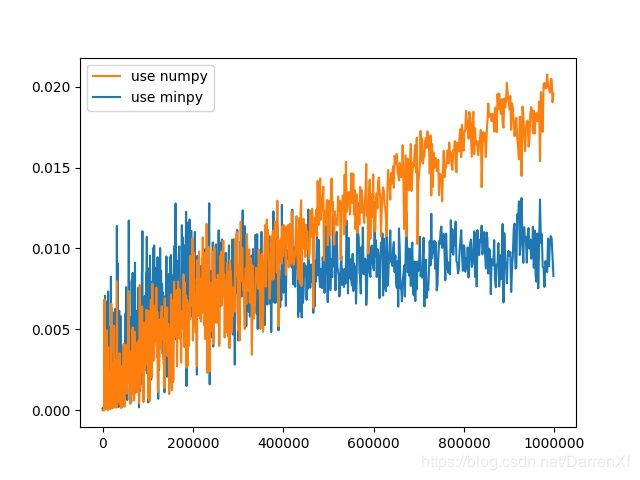
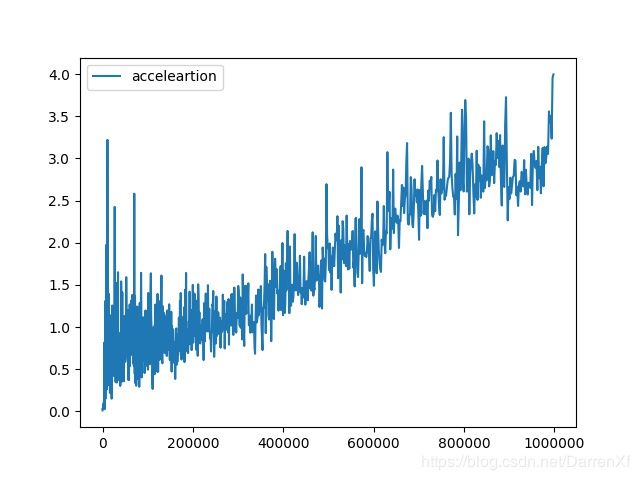
float32的对比就没有float64的明显.这违背了我原始的直觉,我原本认为float32的加速效果会比float64好.可能我的测试存在问题吧.
然后是加速效果
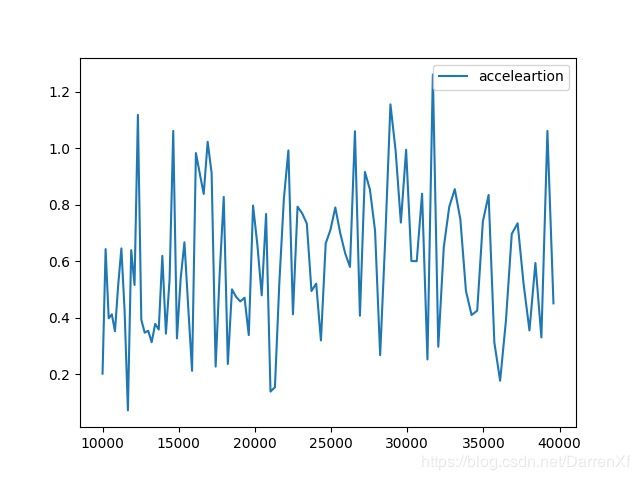
500_float64_100_200

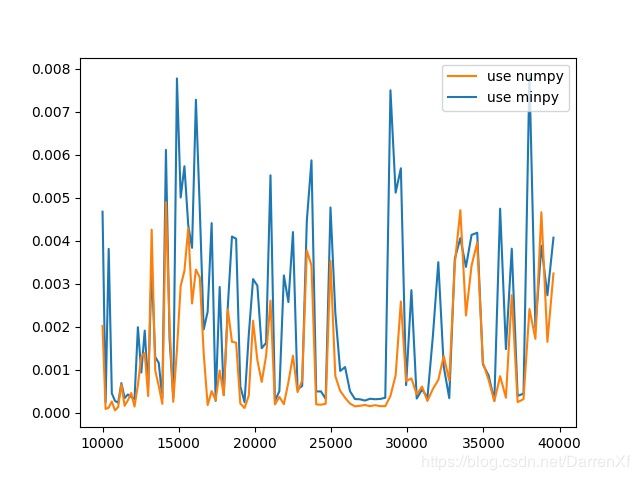
500_float32_100_200
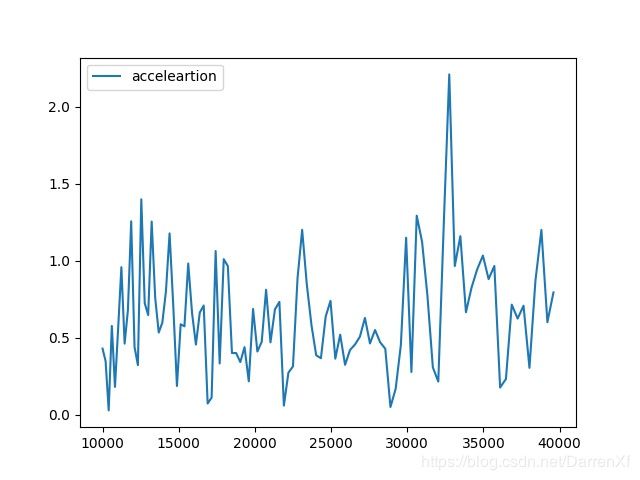
500_float64_200_300
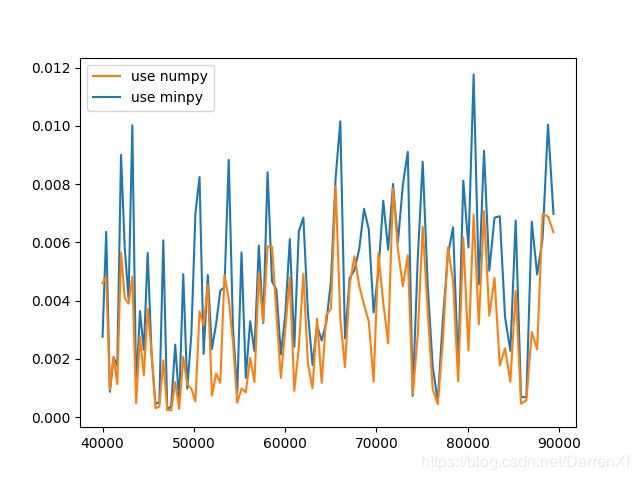

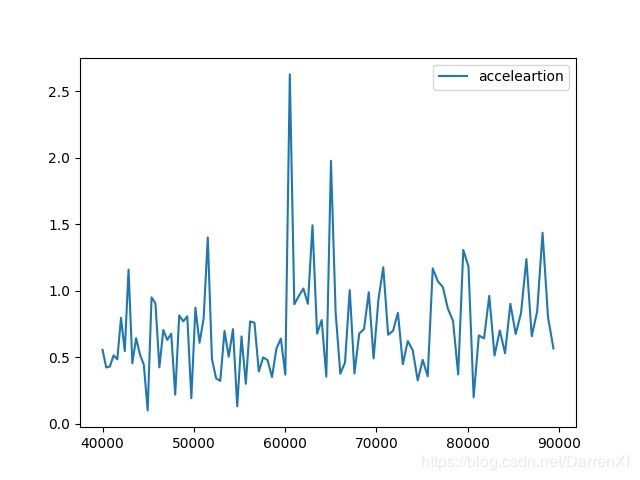
500_float32_200_300

500_float64_300_400
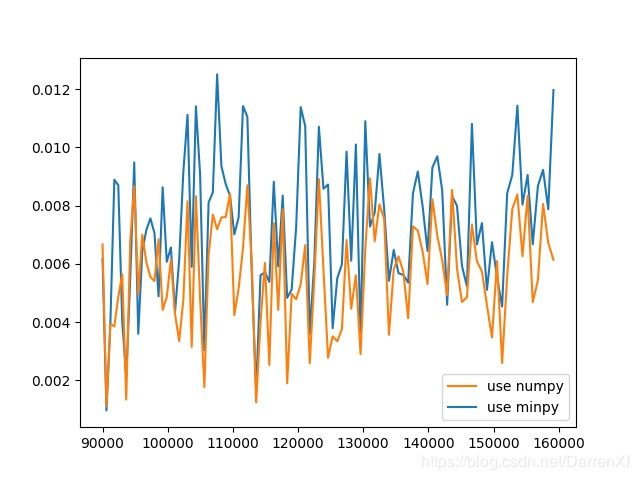
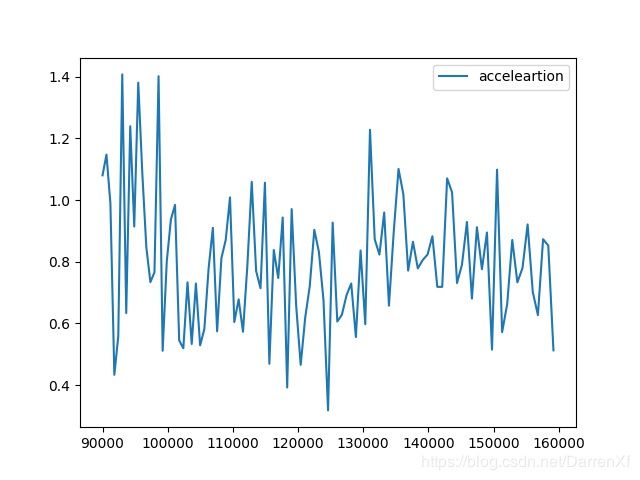
500_float32_300_400
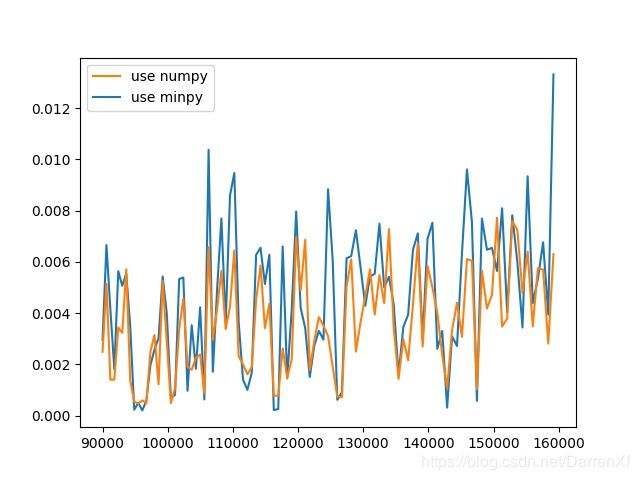

500_float64_400_500
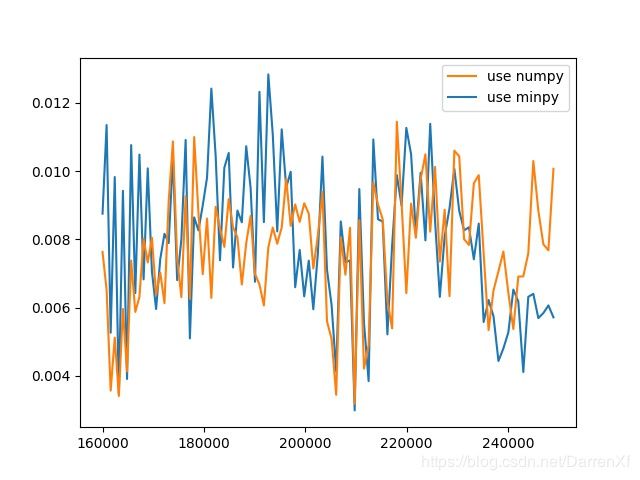

500_float32_400_500
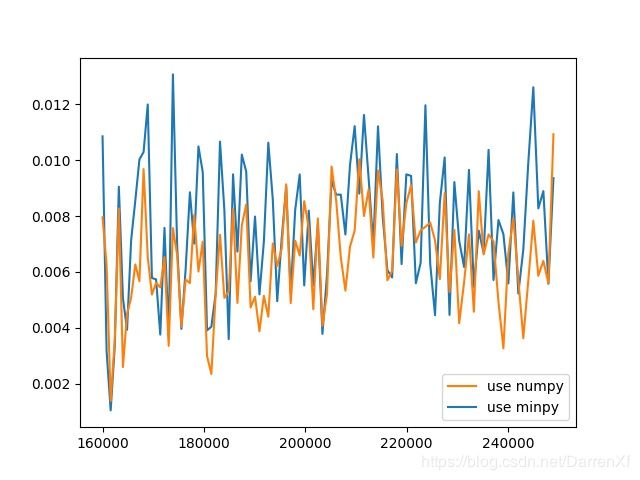
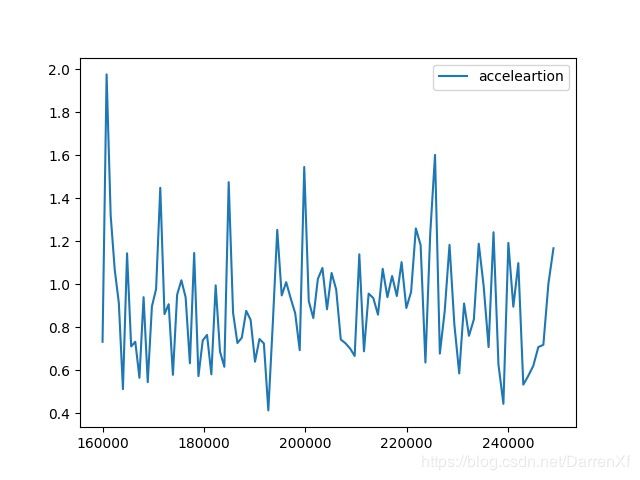
500_float64_500_600
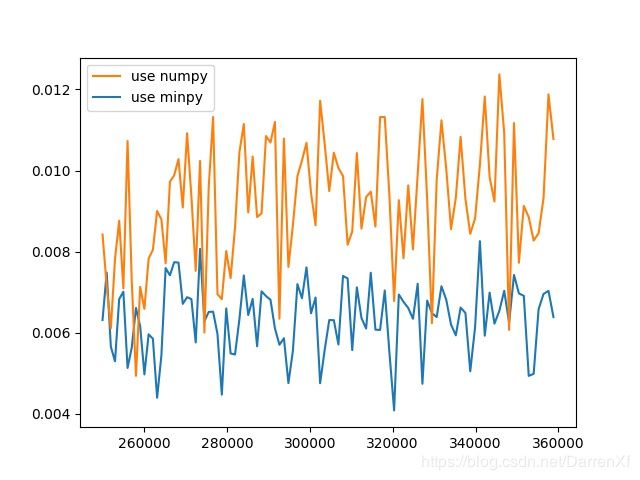
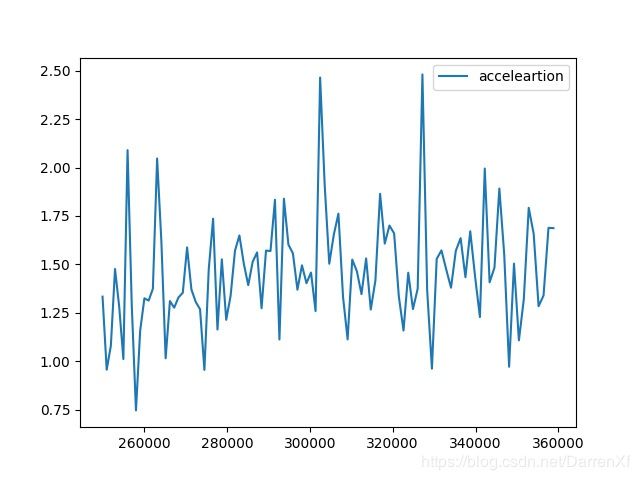
500_float32_500_600
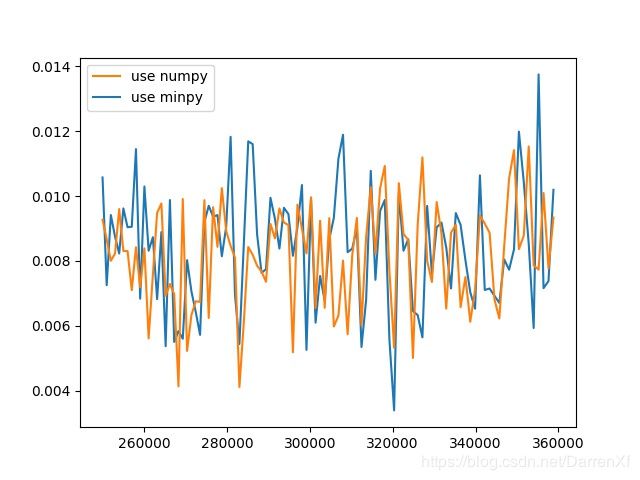

500_float64_600_700
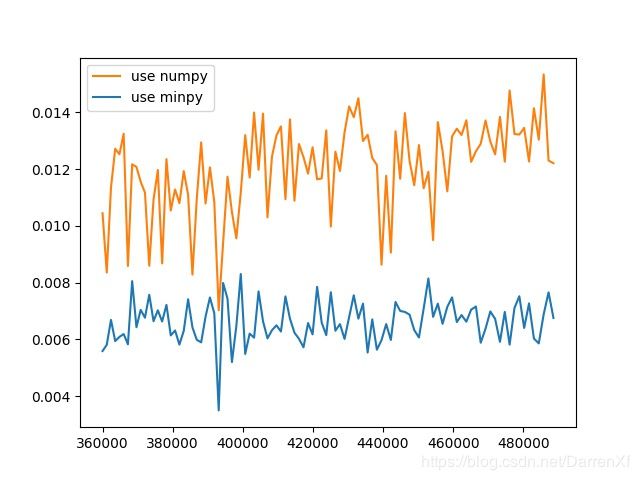
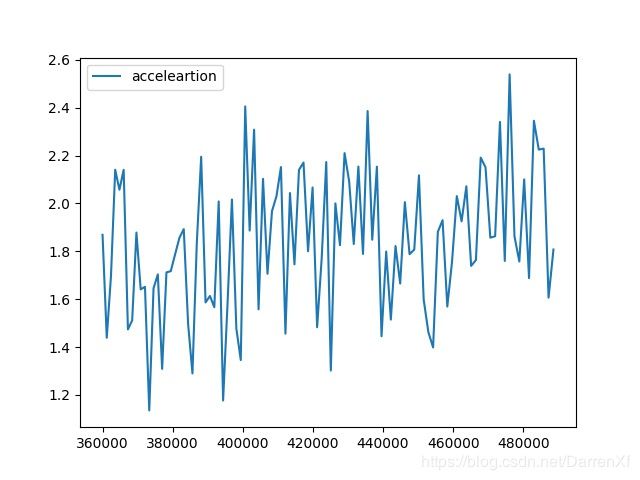
500_float32_600_700
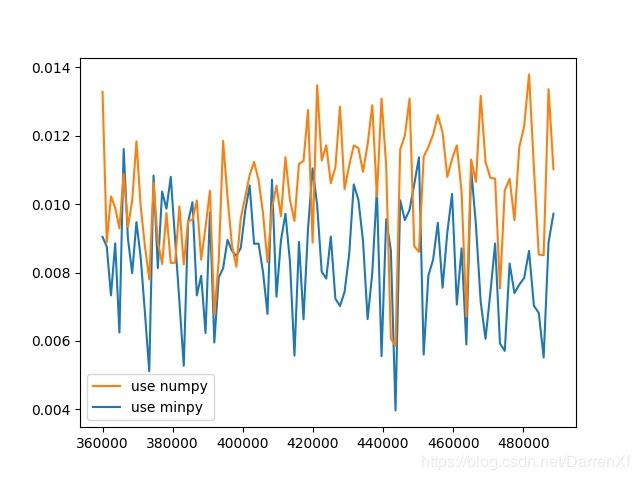
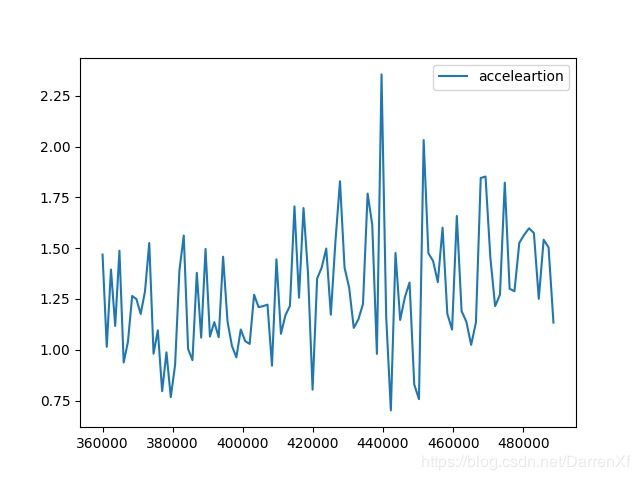
500_float64_700_800

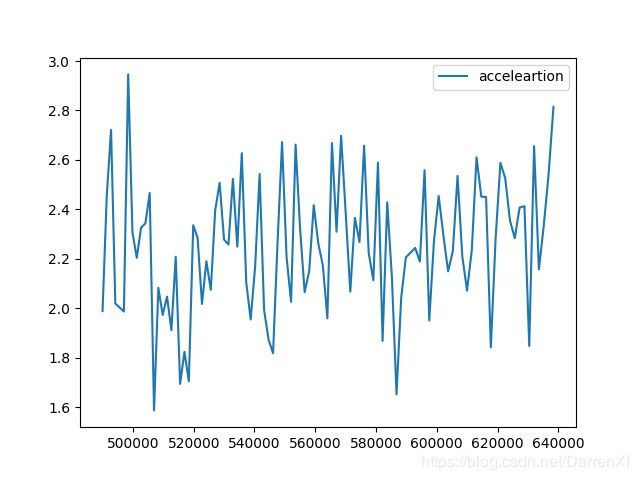
500_float32_700_800
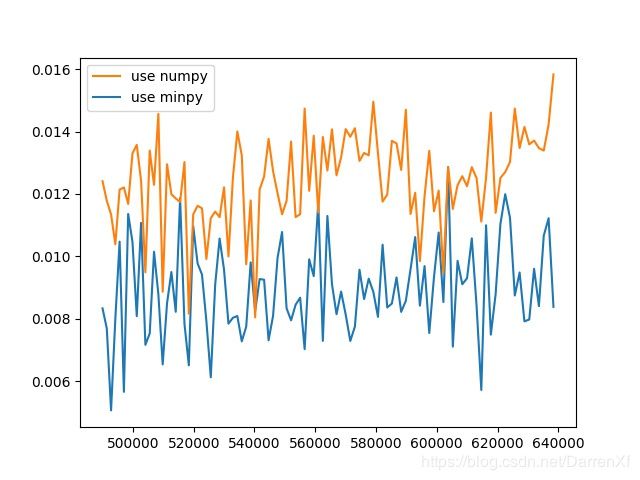
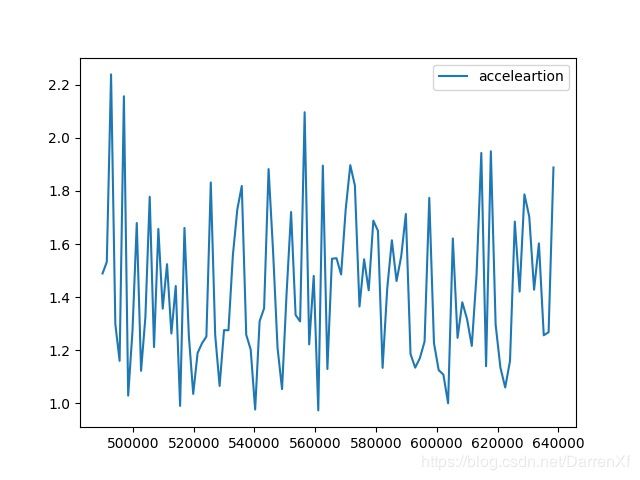
500_float64_800_900

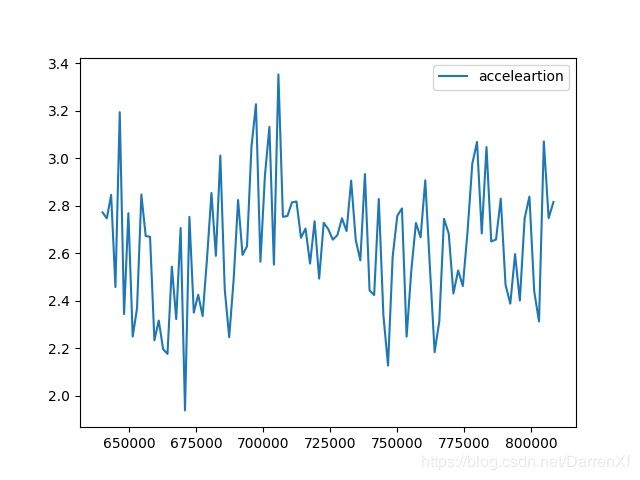
500_float32_800_900
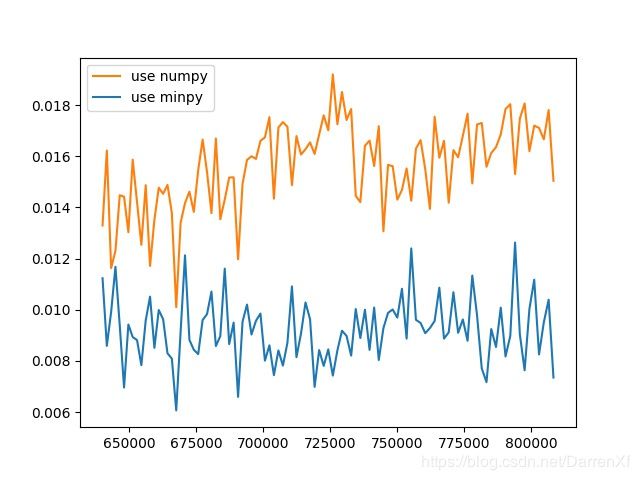
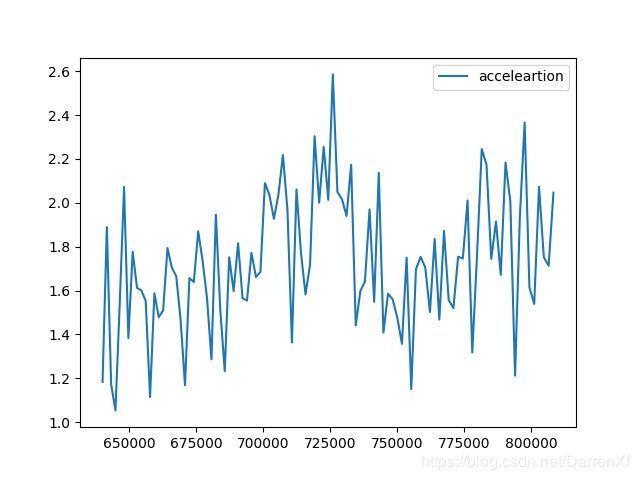
500_float64_900_1000

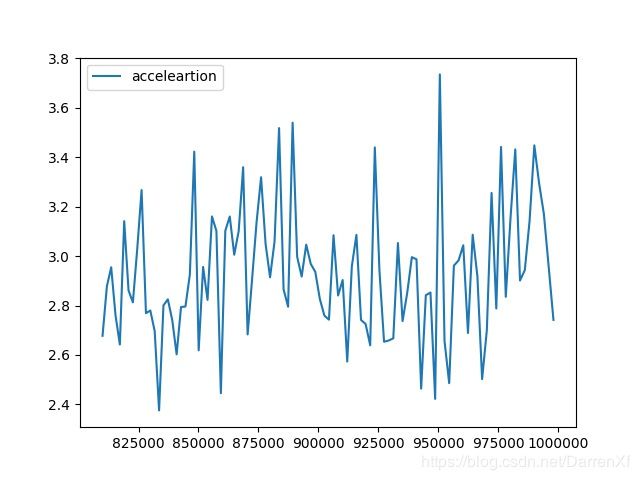
500_float32_900_1000