大数据学习笔记之Hive(三):Hive入门
文章目录
- 复习:
- Hive框架基础(二)
- Hive的MapReduce任务
- Hive的元数据库的备份与还原(metastore)
- Hive操作HQL语句的两个参数
- 练习:
- Hive历史命令存放地
- Hive临时生效设置
- Hive的内部表与外部表
- Hive分区表
- 案例:见HQL案例文档
- Hive查看Mapreduce转换结构
- 常见函数
- HiveServer2
- UDF函数(用户定义函数)
复习:
安装流程
解压安装
配置文件修改
Mysql安装(可以使用其他数据库)
log4j的修改
启动命令
$ bin/hive 针对的是本地启动
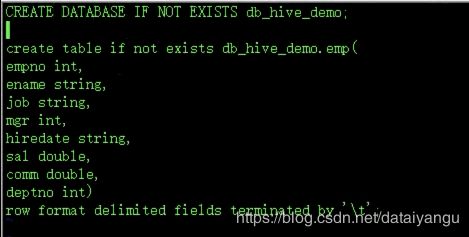
建表语句:
create table if not exists db_hive_demo.emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
row format delimited fields terminated by '\t';
导入数据
load data local(该关键字表明数据是从Linux本地加载,如果没有该关键字,则 从HDFS上加载)
desc formatted table;
Hive框架基础(二)
理性认知:
Hive的MapReduce任务
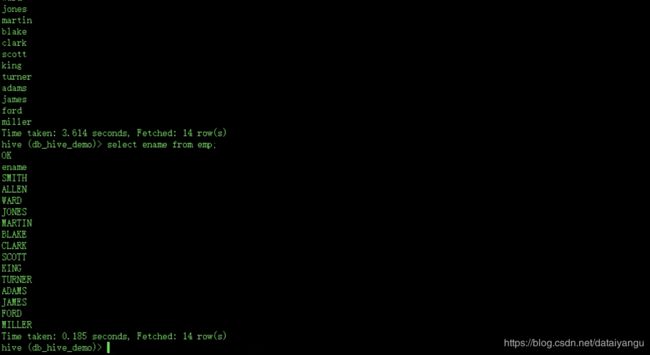
上一小节的最后(大数据学习笔记之Hive(二))select name for t1的时候,是通过了MapReduce的,对于这种简单的select操作不希望经过MapReduce怎么办?
<property>
<name>hive.fetch.task.conversion</name>
<value>more</value>
<description>
//一些简单的查询不需要reduce,某些单列查询需要执行MapReduce
//如果查询不包含子查询、聚合查询、去重查询、侧面视图、join,在这样的情况下可以不执行MapReduce
//对于单列查询而言,不属于上面所说的内容,可以设置成不执行MapReduce,将值设置为more
Some select queries can be converted to single FETCH task minimizing latency.
Currently the query should be single sourced not having any subquery and should not have
any aggregations or distincts (which incurs RS), lateral views and joins.
1. minimal : SELECT STAR, FILTER on partition columns, LIMIT only
2. more : SELECT, FILTER, LIMIT only (TABLESAMPLE, virtual columns)
</description>
</property>
配置成more之后
上一小节的最后(大数据学习笔记之Hive(二))select name for t1的时候,是通过了MapReduce的。
Hive的元数据库的备份与还原(metastore)
常见错误:启动Hive时,无法初始化metastore数据库,无法创建连接,无法创建会话。
可能性分析:
1、hive的metastore数据库丢失了,比如drop,比如文件损坏
2、metasotre版本号不对。
3、远程表服务
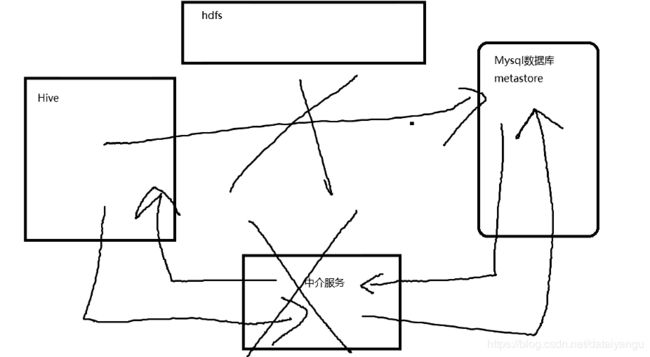
为什么会出现远程表服务的问题,一开始hive的文件路径和双射表,都直接从mysql中进行读取,后台从中介服务中进行读取,可是后来中介服务挂掉了,就会出现远程表服务的问题。
备份的基本语法:
$ mysqldump -uroot -p metastore > metastore.sql
可以备份成xls、txt、json、html等多种格式
还原的基本语法:
$ mysql -uroot -p metastore < metastore.sql
复习:find命令,查找metastore.sql默认存放位置
Hive操作HQL语句的两个参数
例如:公司让你定时定点的进行hive的数据清洗操作,比如说半夜三点,而且老板说执行万第一个任务的时候,紧接着执行第二个任务,上班时间明显是不包括半夜三四点的,需要怎样让hive定时操作这个东西?
一般使用:
oozie(流式)
azakban(流式)
crontab(非流式)
上面三种是定时任务,可是hive中的hql不是bash语句怎么办?
1. hive -e “”
将hive语句写到“”中,这条命令移位这直接用bash脚本执行了一条hql语句

将上面的语句放到crontab中,就被糅合到定时任务中了。
2. hive -f 文件.hql
把复杂的dadoop语句直接写到了hql文件中,通过这条命令执行文件中的一系列hql语句
新建hql文件

写入语句
通过脚本执行
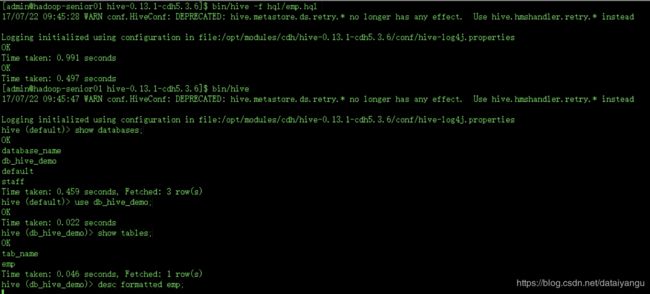
查看表的数据
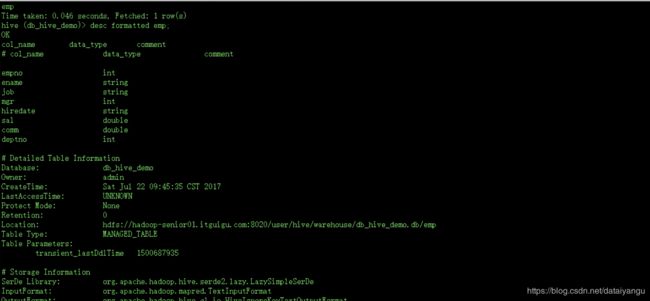
是没有问题的。
练习:
1、创建部门,员工信息表
hive> create table if not exists db_hive_demo.dept(
deptno int,
dname string,
loc string)
row format delimited fields terminated by '\t';
hive> create table if not exists db_hive_demo.emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
row format delimited fields terminated by '\t';
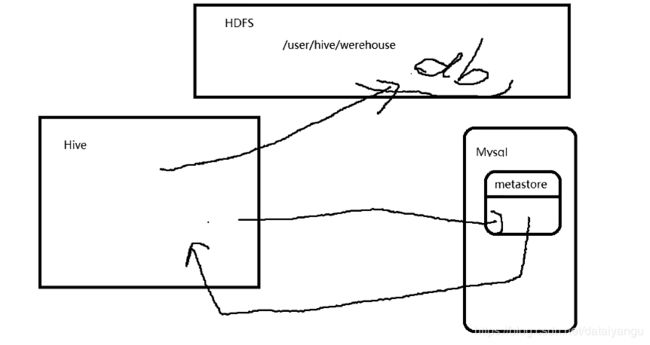
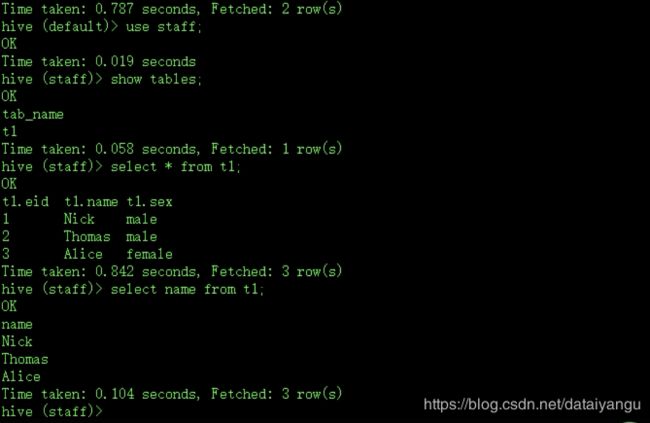
在hive中穿件库的瞬间,会在hdfs中有一个db目录,db严格来讲不是一个数据库,hive虽然不是数据库,而是数据仓库,但是在整个概念上都偏向于一个统一,跟数据库是差不多的,总是给人一种错觉,是在操作数据库,其实不是,当在hive中执行一条hql语句的同时,在hdfs上会创建xxx.db的数据库,在mysql数据库里面,在metestore中会创建一个hive数据库到hdfs的一个双射关系,也就是下次hive访问的时候就知道数据存在hdfs中的哪里,hive中是不存放任何数据的,hive访问的时候,先连接mysql数据库,从包含xxx.db的信息的双射表,从表里面拿到了hsdfs中的数据库(类数据库)的索引信息,拿到索引信息之后hive就可以直接对hdfs进行操作了,hive在xxx.db中创建了一张表,hive找到了xxx.db这个hdfs中的文件夹,进入文件夹,在文件夹中再生成一个文件,相当于一张表,比如t1.txt,然后把这个表的绝对路径放在mysql中,下次去访问的时候,下次访问的时候就可以找到t1.txt这个表的绝对路径。如果是操作数据源的话,需要到metastore中拿到数据源的属性值和每个字段的属性名字的双射关系,去metastore里面找,也就是hive中所有的东西,都不会在hive本身,hive只是客户端,数据源本身是在hdfs里面,数据源的各种双射关系存在了mysql metastore里面,hive里面没有存任何东西。
2、导入数据
hive (default)> load data local inpath '/home/admin/Desktop/dept.txt' into table db_hive_demo.dept;
hive (default)> load data local inpath '/home/admin/Desktop/emp.txt' into table db_hive_demo.emp;
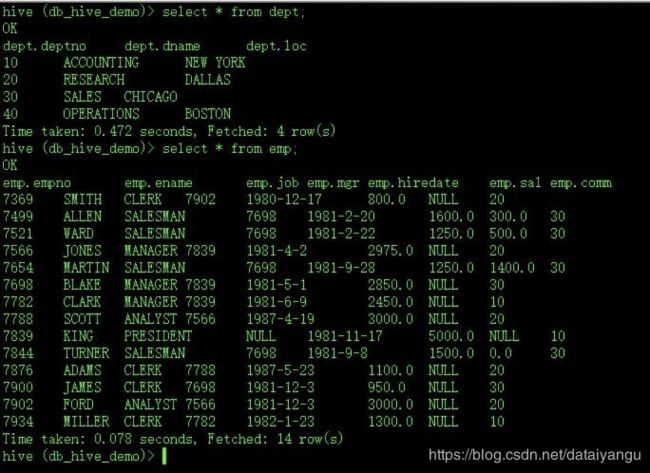
关于的导入,大数据学习笔记之Hive(二)的末尾也有讲,有关于.txt文件的具体内容的展示,这里类似
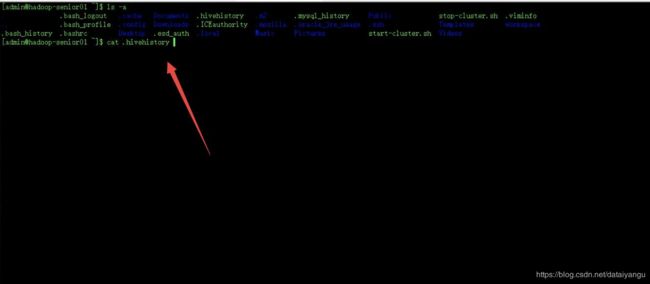
Hive历史命令存放地
cat ~/.hivehistory
主要用于排查逻辑错误或者查看常用命令,比如项目已经运行一个月了,日志中某一天出错了,想知道当时是如何操作的,通过这个功能查看当时是错误在了哪里
Hive临时生效设置
固定语法:set 属性名=属性值
例如:set hive.cli.print.header=false;
在Hive客户端启动的时候突然想改变某个属性值,但是又不想重启Hive,可以直接set属性名 = 属性值,也就是动态修改配置文件中的值,就像上面的set语句对应如图中的配置信息。
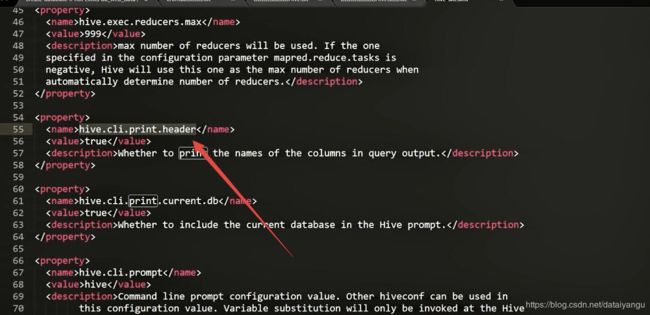
通过参数hive.cli.print.header可以控制在cli中是否显示表的列名。
但是注意 这个配置只在本次生效,下次启动的时候就不再生效了
Hive的内部表与外部表
伪代码:
hive> CREATE TABLE custom_table(id int, name string) location '/custom/z/hive/somedatabase'
默认情况:inner (内部表)
hive> CREATE INNER TABLE(报错)
显示指定:external (外部表)
hive> CREATE EXTERNAL TABLE
内部表:
删除表数据时,连同数据源以及元数据信息同时删除
外部表:
1、只会删除元数据信息(metastore)。
2、共享数据,外部表相对而言也更加方便和安全。
相同之处:
如果你导入数据时,操作于HDFS上,则会将数据进行迁移,并在metastore留下记录,而不是copy数据源。
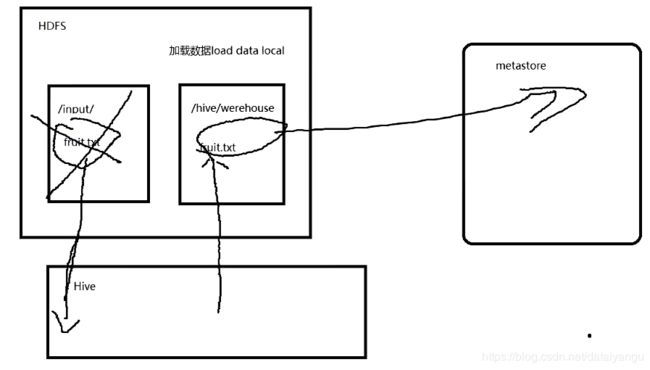
想把fruit.txt导入到hive中,表面上看是吧fruit.txt拿到hive中,其实是把它导入到了/hive/werehouse里面,在导入的同时,如果这件事情发生在hdfs集群里面,回到值fruit.txt这个源文件被删除,有点类似于剪切的功能,这样设计的合理性在于,比方说集群本来有三份,在集群里面相互转移仓库的时候,copy出来一个,那么存储的消耗就很大,所以hive在集群内部进行仓库转储的时候,是删除源文件的,hive做的这个工作相当于只是单纯的把数据源,在metastore里面做一个双射,如果加载数据是load data local,相当于把数据put到hdfs上面,然后做一个双射关系。

cd /opt/modules/cdh/hive-0.13.1-cdh5.36
vi fruit.txt
![]()
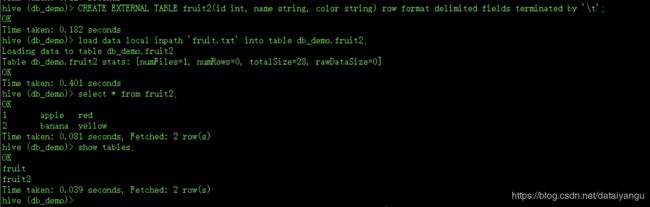
上传数据
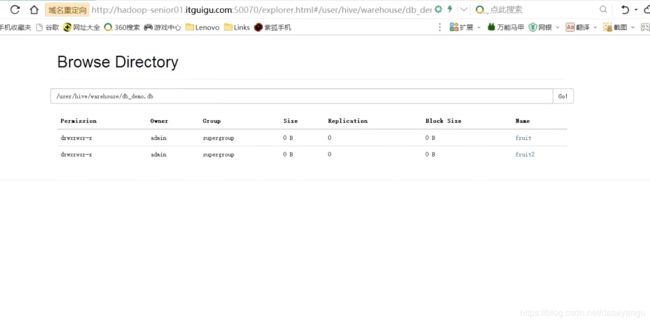
在hdfs中也有数据
现在删掉fruit2表
在hdfs中还是有的
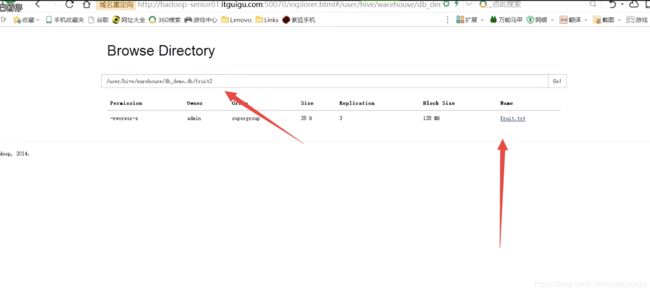
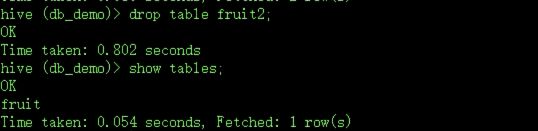
删掉fruit1表

在hdfs中就没有了
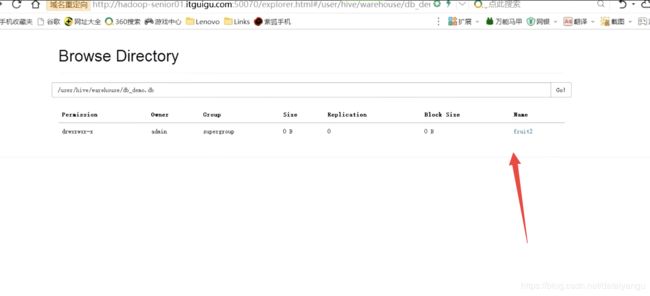
如何验证删除索引而不是删除元数据呢?show tables的时候,如果依赖于元数据信息,所有的show操作,或者说所有hive的操作,都依赖于metastore,metastore里面有的东西才会操作,没有的东西是不能操作的,既然show tables里面没有fruit2,说明里面没有了,但是通过hdfs系统查看的时候还是有的,说明外部表是不会删除掉数据本身的。
这样有什么好处?比如公司产生很多数据,这些数据在另一台客户端上操作的时候,是不需要展示出来的,只需要展示公司安排的特定的任务就可以了, 这块数据不需要设计到metastore表中,但是也不能删除掉,因为后面或者其他的业务会用到,这个时候就会涉及到外部表的操作。
Hive分区表
分区表有什么作用呢?
假如有一个非常大的文件
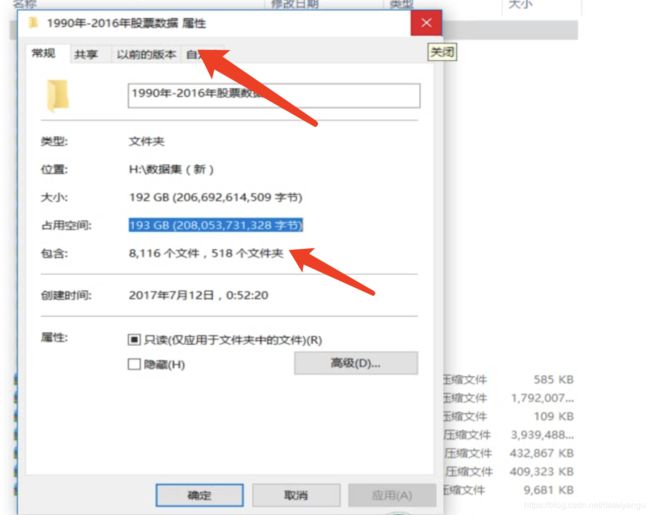
如果把所有的股票数据不管哪一天的全部加载到一张表里面
创建分区表:
vi pv_uv.hql
create database if not exists db_web_data ;
create table if not exists db_web_data.track_log(
id string,
url string,
referer string,
keyword string,
type string,
guid string,
pageId string,
moduleId string,
linkId string,
attachedInfo string,
sessionId string,
trackerU string,
trackerType string,
ip string,
trackerSrc string,
cookie string,
orderCode string,
trackTime string,
endUserId string,
firstLink string,
sessionViewNo string,
productId string,
curMerchantId string,
provinceId string,
cityId string,
fee string,
edmActivity string,
edmEmail string,
edmJobId string,
ieVersion string,
platform string,
internalKeyword string,
resultSum string,
currentPage string,
linkPosition string,
buttonPosition string
)
//-- 分区表的分区字段以逗号分隔,意思是创建这个表的时候以什么作为分区
partitioned by (date string,hour string)
row format delimited fields terminated by '\t';
bin/hive -f hql/pv_uv.hql
导入数据到分区表:
将两个文件导入到一个表中
hive> load data local inpath '/home/admin/Desktop/2015082818' into table db_web_data.track_log partition(date='20150828', hour='18');
hive> load data local inpath '/home/admin/Desktop/2015082819' into table db_web_data.track_log partition(date='20150828', hour='19');
查询分区表中的数据:
hive> select url from track_log where date='20150828';查询28整天的数据
hive> select url from track_log where date='20150828' and hour='18'; 查询28号18
时那一刻的数据
select url from track_log where date='20150828' and hour='18' limit 1;显示第一条
练习:
1、尝试将2015082818,2015082819两个文件上传到HDFS之后,再load data
案例:见HQL案例文档
tip 如何查看hive自带的函数(类似于MAX) 在hive中输入 show functions 或者查看官方文档,这些函数实际用的时候是不区分大小写的。
如果想把写好的语句直接粘贴到hive命令行,记得将每行的缩进去掉
查询每个部门的最高薪资:
SELECT
deptno, MAX(sal)
FROM
emp
GROUP BY
deptno;
经过MapReduce的原因是有聚合操作。
查询显示员工姓名,员工编号,部门名称
SELECT
e.ename,
e.empno,
d.dname
FROM
emp e JOIN dept d ON e.deptno = d.deptno
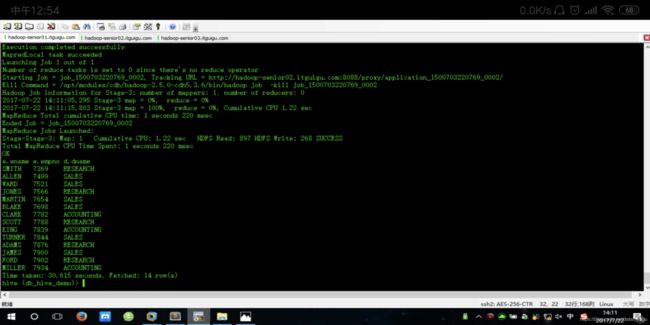
按照部门进行薪资的排位
SELECT
empno,
ename,
sal,
deptno,
ROW_NUMBER() OVER(PARTITION BY deptno ORDER BY sal DESC) rank
FROM
emp;
排位的时候需要涉及到一个序号1234557,hive中的函数是ROW_NUMBER 按照某一个已经排序号的序列,进行重新的编码,比方说薪资按照从大到小的排序,排序之后对每一个序列从1开始递增进行编码,比如说部门十,三月的薪资是三千、五千、两千,右边实现123
PARTITION BY deptno 按照deptno进行分区
ORDER BY sal DESC 按照sal排序,排序规则是DESC
rank 排序之后要对排序进行编码,123,赋值给一个字段rank
FROM emp from emp表
over这个函数不能单独使用,必须和其他的函数配合使用比如row_number,这里面相当于一个子查询,
按照部门进行薪资排位,只显示前两名
SELECT
temp.empno,
temp.ename,
temp.sal,
temp.deptno
FROM(
SELECT
empno,
ename,
sal,
deptno,
ROW_NUMBER() OVER(PARTITION BY deptno ORDER BY sal DESC) rank
FROM
emp) temp
WHERE
temp.rank <= 2
把上面的哪个sql语句当做临时表放了进来
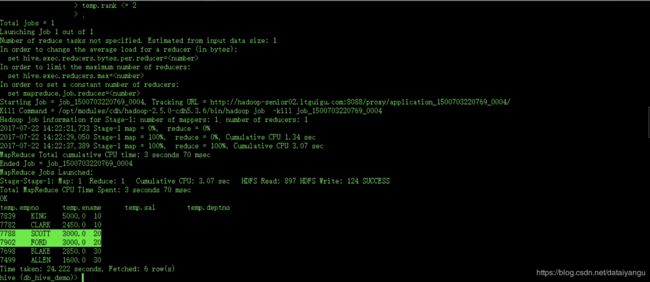
都是现实前两个
统计某个网站某天的所有PV数据
格式:
2015-08-28 35000
SELECT
temp.date,
COUNT(temp.url) pv
FROM(
SELECT
SUBSTRING(trackTime, 0, 10) date,
url
FROM
db_web_data.track_log
WHERE
LENGTH(url) > 0) temp
GROUP BY
temp.date;
SUBSTRING截取,这里是截取日志
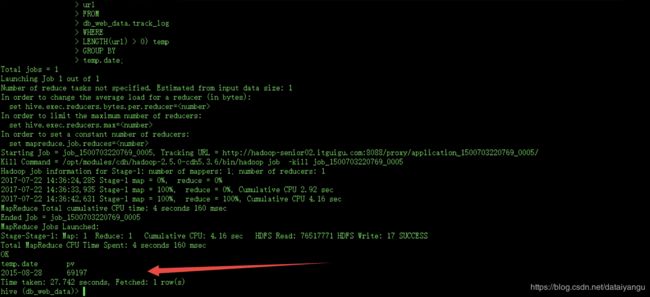
统计某个网站某天的所有UV数据
格式:
2015-08-28 35000 12000
SELECT
temp.date,
COUNT(temp.url) pv,
COUNT(DISTINCT temp.guid) uv
FROM(
SELECT
SUBSTRING(trackTime, 0, 10) date,
url,
guid
FROM
db_web_data.track_log
WHERE
length(url) > 0) temp
GROUP BY
temp.date;
同一个用户在同一天内访问同一个页面无数次都只按一次算,
guid 唯一用户id
DISTINCT 去重
COUNT(DISTINCT temp.guid)去重后的个数
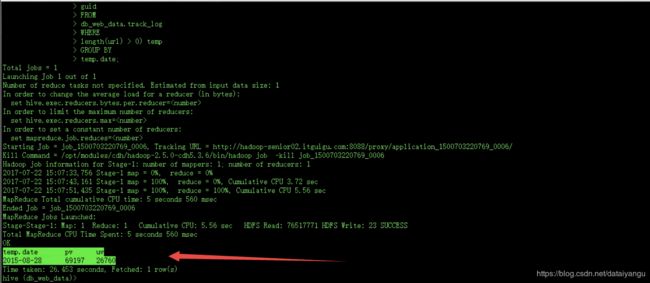
CASE案例
将总收入显示出来:
select ename, case when comm is null then 0 + sal else comm + sal end from emp;
显示收入评级:
select ename, case when sal < 1000 then "lower" when sal >= 1000 and sal <= 2000 then "mid" else "high" end from db_hive_demo.emp;
select ename, case when sal < 1000 then deptno when sal >= 1000 and sal <= 2000 then comm else "UNKNOWN" end from db_hive_demo.emp;
Hive查看Mapreduce转换结构
Hive是把任务转化成了MapReduce,可以通过explain关键字查看是如何分配的,
例如:hive (db_web_data)> explain SELECT deptno, MAX(sal) FROM db_hive_demo.emp GROUP BY deptno;
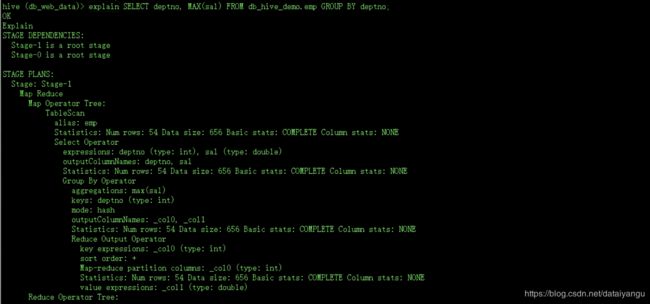
常见函数
avg
sum
min
max
cast 类型转换
case 匹配
练习:
一个case的练习:
select ename, case when comm is null then 0+sal else comm + sal end from emp;
如果没有提成的话就是自己,有提成的话就加上提成
1、统计所有部门的薪资总和(不包含提成)并显示。
2、统计部门薪资,如果该部门所需薪资大于3000,则砍掉该部门。
3、统计每个职业的平均薪资,显示出“职业”,“平均薪资”
HiveServer2
在使用hive去连接数据仓库的时候有多种方式,bin/hive是本地模式,hiveserver2是远程模式
HiveServer2作为一种服务接口,允许Hive远程客户端执行查询并返回结果。当前实现基于Thrift的RPC调用。是HiveServer的改进版本,支持多客户端的并发和权限控制
配置:hive-site.xml
hive.server2.thrift.port --> 10000
//默认是localhost 即127.0.0.1 ,就是别人能够连接自己
//相当于腾讯qq多人连天,hiversrever2就是腾讯服务器
//提供一个中间件的服务,方便于其他的节点控制该客户端
hive.server2.thrift.bind.host --> hadoop-senior01.itguigu.com 修改为自己的ip
hive.server2.long.polling.timeout -- > 5000(去掉L,默认后面是有L的)连接超时的时间
hive.server2.thrift.bind.host解释:都是启动自己本身的hiveserver2服务对外服务,外面能够访问,至于是localhost还是自己的ip,外部都是能够访问的,hiveserver2的作用:加入一间教室里面的同学想要控制班里另一个同学的电脑,然后开启一个连接,能够开启这个连接的原因是什么?是腾讯服务器下面的一个服务,通过腾讯的服务器进行传输,hiveserver2就相当于主机的一个服务器,如果打开这个服务,其他的人也可以通过hiveserver2连接到服务上面。
检查端口:
//查看端口是都被占用
$ sudo netstat -antp | grep 10000
启动服务:
$ bin/hive --service hiveserver2
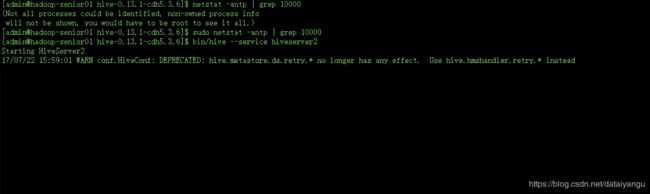
然后就到另一台服务器去进行连接
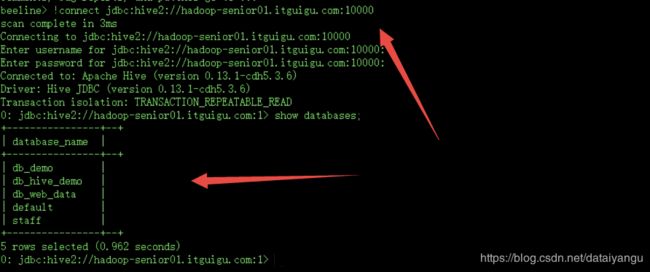
连接服务:
$ bin/beeline
beeline> !connect jdbc:hive2://hadoop-senior01.itguigu.com:10000
尖叫提示:注意此时不能够执行MR任务调度,报错:
Job Submission failed with exception 'org.apache.hadoop.security.AccessControlException(Permission denied:
user=anonymous, access=EXECUTE, inode="/tmp/hadoop-yarn":admin:supergroup:drwxrwx---
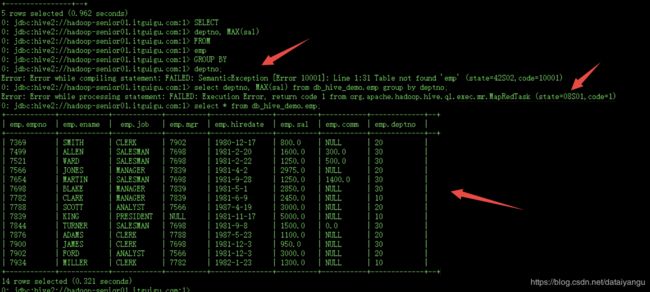
现在要做的事情是允许在hiveserver2的情况下,去调度MapReduce任务
hive-site.xml
hive.server2.enable.aoAs=========>false
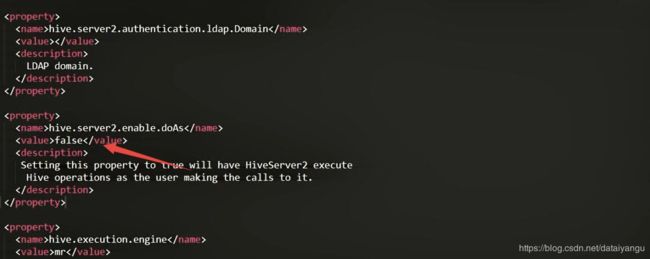
如果是true的话,需要用hadoop的用户去调度这个任务,否则的话就没有权限,false就是使用哪个用户启动hiveserver2,就可以使用哪个用户调度任务。

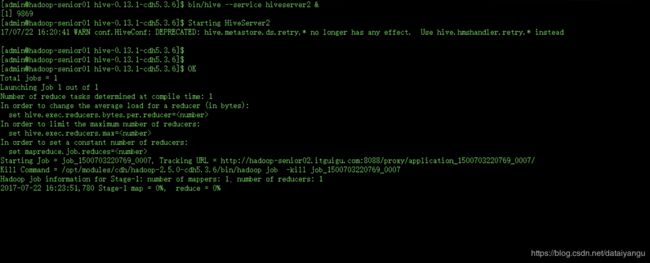
配置完之后在客户端调用需要MapReduce的函数,服务端有关于MapReduce的日志出现。
UDF函数(用户定义函数)
写一个函数实现字段属性值的大小写转换
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>0.13.1</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>0.13.1</version>
</dependency>
一个将传入的字符串变成小写的函数
import org. apache. hadoop. hive. ql exec. UDF
import org. apache hadoop. io. Text
ublic cLass ToLower Case extends UDF{
public Text evaluate(Text str){
if(str = null} return null;
if(str!= null && str.toString().length()<=o)return null;
return new Text(str.tostring().toLowerCase());
}
public static void main(String[] args){
Systemout.printin(new ToLowerCase().evaluate(new Text(args[01)));
}
}
然后打成jar包
将jar包放到hive服务器上
启动hibe
/bin/hive
hive>add jar jar路径 ;
hive>create temporary function zlowercase as 'com.z.demo.hive.ToLowerCase';

hive>show functions;

hive>use db_hive_demo
hive>slect zlowercase(ename) from emp;
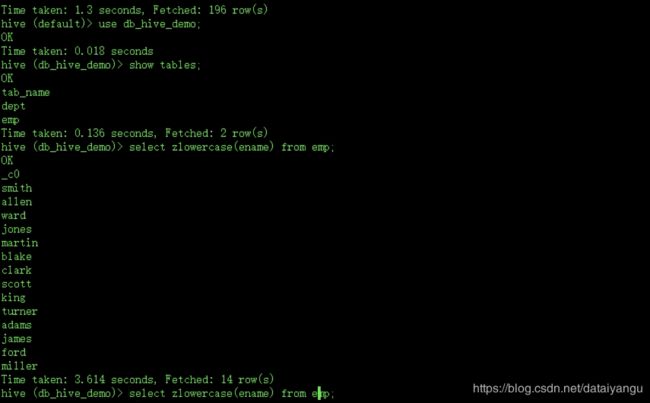
对比下如果不用这个函数的话