大数据学习笔记之Spark(八):Spark机器学习解析
文章目录
- 第1章机器学习概述
- 第2章机器学习的相关概念
- 2.1数据集
- 2.2泛化能力
- 2.3过拟合和欠拟合
- 2.4维度、特征
- 2.5模型
- 2.6学习
- 第3章算法常用指标
- 3.1精确率和召回率
- 3.2TPR、FPR&TNR
- 3.3综合评价指标F-measure
- 3.4ROC曲线、AUC
- 3.4.1为什么引入ROC曲线?
- 3.4.2什么是ROC曲线?
- 3.4.3什么是AUC?
- 3.4.4怎样计算AUC?
- 4.1梯度下降
- 4.2牛顿法
- 4.3拟牛顿法
- 4.4BFGS算法
- 第5章L1、L2正则化
- 5.1从经验风险最小化到结构经验最小化
- 5.2范数与正则项
- 5.3贝叶斯先验
- 第6章PCA降维
- 6.1数据降维的必要性
- 6.2PCA理论推导
- 6.2.1内积与投影
- 6.2.2向量的基
- 6.2.3矩阵的基变换
- 6.2.4协方差矩阵及优化目标
- 6.2.4.1 方差
- 6.2.4.2 协方差
- 6.2.4.3 协方差矩阵
- 6.2.4.4 协方差矩阵对角化
- 6.3算法及实例
- 6.3.1PCA算法
- 6.3.2实例
- 第7章ICA降维
- 7.1PCA存在的问题
- 7.2ICA的不确定性
- 7.3密度函数和线性变换
- 7.4ICA算法
- 7.5实例
- 第8章非平衡数据处理
- 8.1过采样
- 8.2欠采样
- 8.3Informed Understanding
- 8.4综合采样
- 第9章模型优化
第1章机器学习概述
第2章机器学习的相关概念
2.1数据集
一组数据的集合被称作数据集,用于模型训练的数据集叫训练集,用于测试的数据集叫测试集。一个数据集包含多条数据,一条数据包含多个属性。

2.2泛化能力
是指机器学习通过训练集进行模型的训练之后对未知的输入的准确判断能力
2.3过拟合和欠拟合
过拟合是指在利用训练数据进行模型训练的时候,模型过多的依赖训练数据中过多的特征属性。欠拟合是指没有通过训练集达到识别的能力。
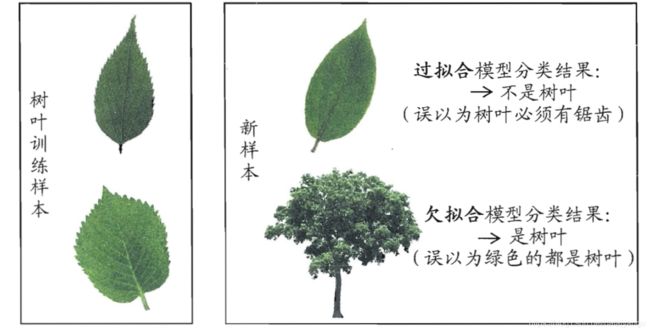
2.4维度、特征
对于西瓜数据集,色泽、根蒂、敲声就是维度,也叫特征值。

2.5模型
模型就是复杂的数学相关函数,只是该函数具有很多的未知的参数,通过训练集训练来确定模型中的参数,生成的已知参数的函数就是模型。
2.6学习
机器学习分为有监督学习和无监督学习,有监督学习是指训练集中有明确的标记,如下数据集:各种特征的西瓜是不是好瓜,有明确的标记。分类就是典型的有监督学习

无监督学习是指训练集中没有明确的标记,聚类就是典型的无监督学习。
第3章算法常用指标
3.1精确率和召回率
考虑一个二分问题,即将实例分成正类(positive)或负类(negative)。对一个二分问题来说,会出现四种情况。如果一个实例是正类并且也被 预测成正类,即为真正类(True positive),如果实例是负类被预测成正类,称之为假正类(False positive)。相应地,如果实例是负类被预测成负类,称之为真负类(True negative),正类被预测成负类则为假负类(false negative)。
TP:正确肯定的数目;
FN:漏报,没有正确找到的匹配的数目;
FP:误报,给出的匹配是不正确的;
TN:正确拒绝的非匹配对数;
列联表如下表所示,1代表正类,0代表负类:

预测1 预测0
实际1 True Positive(TP) False Negative(FN)
实际0 False Positive(FP) True Negative(TN)
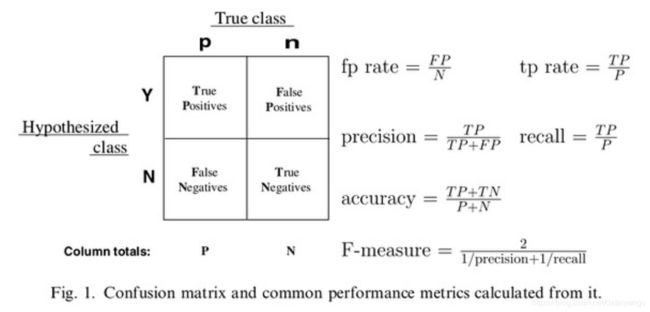
精确率(正确率)和召回率是广泛用于信息检索和统计学分类领域的两个度量值,用来评价结果的质量。其中精度是检索出相关文档数与检索出的文档总数的比率,衡量的是检索系统的查准率;召回率是指检索出的相关文档数和文档库中所有的相关文档数的比率,衡量的是检索系统的查全率。
一般来说,Precision就是检索出来的条目(比如:文档、网页等)有多少是准确的,Recall就是所有准确的条目有多少被检索出来了,两者的定义分别如下:
Precision = 提取出的正确信息条数 / 提取出的信息条数
Recall = 提取出的正确信息条数 / 样本中的信息条数
为了能够评价不同算法的优劣,在Precision和Recall的基础上提出了F1值的概念,来对Precision和Recall进行整体评价。F1的定义如下:
F1值 = 正确率 * 召回率 * 2 / (正确率 + 召回率)
不妨举这样一个例子:
某池塘有1400条鲤鱼,300只虾,300只鳖。现在以捕鲤鱼为目的。撒一大网,逮着了700条鲤鱼,200只虾,100只鳖。那么,这些指标分别如下:
正确率 = 700 / (700 + 200 + 100) = 70%
召回率 = 700 / 1400 = 50%
F1值 = 70% * 50% * 2 / (70% + 50%) = 58.3%
不妨看看如果把池子里的所有的鲤鱼、虾和鳖都一网打尽,这些指标又有何变化:
正确率 = 1400 / (1400 + 300 + 300) = 70%
召回率 = 1400 / 1400 = 100%
F1值 = 70% * 100% * 2 / (70% + 100%) = 82.35%
由此可见,正确率是评估捕获的成果中目标成果所占得比例;召回率,顾名思义,就是从关注领域中,召回目标类别的比例;而F值,则是综合这二者指标的评估指标,用于综合反映整体的指标。
当然希望检索结果Precision越高越好,同时Recall也越高越好,但事实上这两者在某些情况下有矛盾的。比如极端情况下,我们只搜索出了一个结果,且是准确的,那么Precision就是100%,但是Recall就很低;而如果我们把所有结果都返回,那么比如Recall是100%,但是Precision就会很低。因此在不同的场合中需要自己判断希望Precision比较高或是Recall比较高。如果是做实验研究,可以绘制Precision-Recall曲线来帮助分析。
3.2TPR、FPR&TNR
引入两个新名词。其一是真正类率(true positive rate ,TPR), 计算公式为
TPR = TP / (TP + FN)
刻画的是分类器所识别出的 正实例占所有正实例的比例。
另外一个是负正类率(false positive rate, FPR),计算公式为
FPR = FP / (FP + TN)
计算的是分类器错认为正类的负实例占所有负实例的比例。
还有一个真负类率(True Negative Rate,TNR),也称为specificity,计算公式为
TNR = TN /(FP + TN) = 1 - FPR
3.3综合评价指标F-measure
Precision和Recall指标有时候会出现的矛盾的情况,这样就需要综合考虑他们,最常见的方法就是F-Measure(又称为F-Score)。
F-Measure是Precision和Recall加权调和平均:
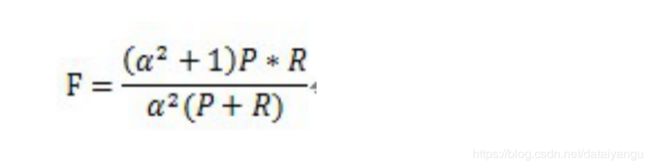
当参数α=1时,就是最常见的F1。因此,F1综合了P和R的结果,当F1较高时则能说明试验方法比较有效。
3.4ROC曲线、AUC
3.4.1为什么引入ROC曲线?
Motivation1:在一个二分类模型中,对于所得到的连续结果,假设已确定一个阀值,比如说 0.6,大于这个值的实例划归为正类,小于这个值则划到负类中。如果减小阀值,减到0.5,固然能识别出更多的正类,也就是提高了识别出的正例占所有正例 的比类,即TPR,但同时也将更多的负实例当作了正实例,即提高了FPR。为了形象化这一变化,引入ROC,ROC曲线可以用于评价一个分类器。
Motivation2:在类不平衡的情况下,如正样本90个,负样本10个,直接把所有样本分类为正样本,得到识别率为90%。但这显然是没有意义的。单纯根据Precision和Recall来衡量算法的优劣已经不能表征这种病态问题。
3.4.2什么是ROC曲线?
ROC(Receiver Operating Characteristic)翻译为"接受者操作特性曲线"。曲线由两个变量1-specificity 和 Sensitivity绘制. 1-specificity=FPR,即负正类率。Sensitivity即是真正类率,TPR(True positive rate),反映了正类覆盖程度。这个组合以1-specificity对sensitivity,即是以代价(costs)对收益(benefits)。
此外,ROC曲线还可以用来计算“均值平均精度”(mean average precision),这是当你通过改变阈值来选择最好的结果时所得到的平均精度(PPV)。
为了更好地理解ROC曲线,我们使用具体的实例来说明:
如在医学诊断中,判断有病的样本。那么尽量把有病的揪出来是主要任务,也就是第一个指标TPR,要越高越好。而把没病的样本误诊为有病的,也就是第二个指标FPR,要越低越好。
不难发现,这两个指标之间是相互制约的。如果某个医生对于有病的症状比较敏感,稍微的小症状都判断为有病,那么他的第一个指标应该会很高,但是第二个指标也就相应地变高。最极端的情况下,他把所有的样本都看做有病,那么第一个指标达到1,第二个指标也为1。
我们以FPR为横轴,TPR为纵轴,得到如下ROC空间。
我们可以看出,左上角的点(TPR=1,FPR=0),为完美分类,也就是这个医生医术高明,诊断全对。点A(TPR>FPR),医生A的判断大体是正确的。中线上的点B(TPR=FPR),也就是医生B全都是蒙的,蒙对一半,蒙错一半;下半平面的点C(TPR
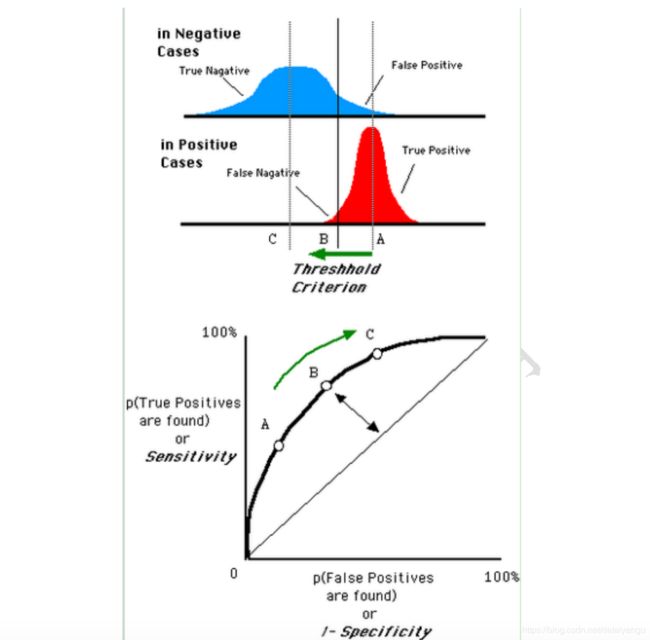
曲线距离左上角越近,证明分类器效果越好。
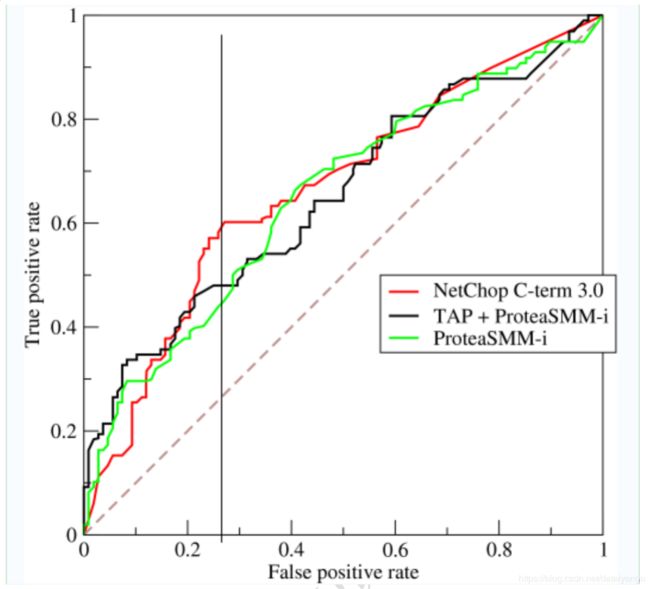
如上,是三条ROC曲线,在0.23处取一条直线。那么,在同样的低FPR=0.23的情况下,红色分类器得到更高的PTR。也就表明,ROC越往上,分类器效果越好。我们用一个标量值AUC来量化它。
3.4.3什么是AUC?
AUC值为ROC曲线所覆盖的区域面积,显然,AUC越大,分类器分类效果越好。
AUC = 1,是完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
AUC的物理意义:假设分类器的输出是样本属于正类的socre(置信度),则AUC的物理意义为,任取一对(正、负)样本,正样本的score大于负样本的score的概率。
3.4.4怎样计算AUC?
第一种方法:AUC为ROC曲线下的面积,那我们直接计算面积可得。面积为一个个小的梯形面积之和。计算的精度与阈值的精度有关。
第二种方法:根据AUC的物理意义,我们计算正样本score大于负样本的score的概率。取NM(N为正样本数,M为负样本数)个二元组,比较score,最后得到AUC。时间复杂度为O(NM)。
第三种方法:与第二种方法相似,直接计算正样本score大于负样本的概率。我们首先把所有样本按照score排序,依次用rank表示他们,如最大score的样本,rank=n(n=N+M),其次为n-1。那么对于正样本中rank最大的样本,rank_max,有M-1个其他正样本比他score小,那么就有(rank_max-1)-(M-1)个负样本比他score小。其次为(rank_second-1)-(M-2)。最后我们得到正样本大于负样本的概率为
时间复杂度为O(N+M)。
MSE: Mean Squared Error
均方误差是指参数估计值与参数真值之差平方的期望值;
MSE可以评价数据的变化程度,MSE的值越小,说明预测模型描述实验数据具有更好的精确度。
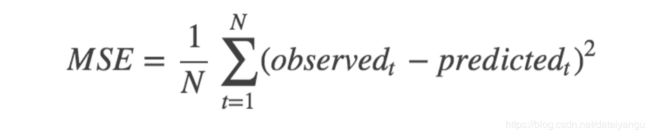
RMSE
均方误差:均方根误差是均方误差的算术平方根
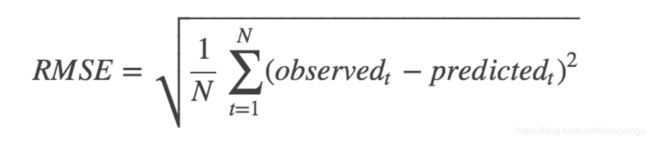
MAE :Mean Absolute Error
平均绝对误差是绝对误差的平均值
平均绝对误差能更好地反映预测值误差的实际情况.
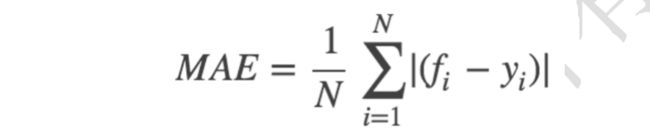
fi表示预测值,yi表示真实值;
SD :standard Deviation
标准差:标准差是方差的算术平方根。标准差能反映一个数据集的离散程度。平均数相同的两组组数据,标准差未必相同。
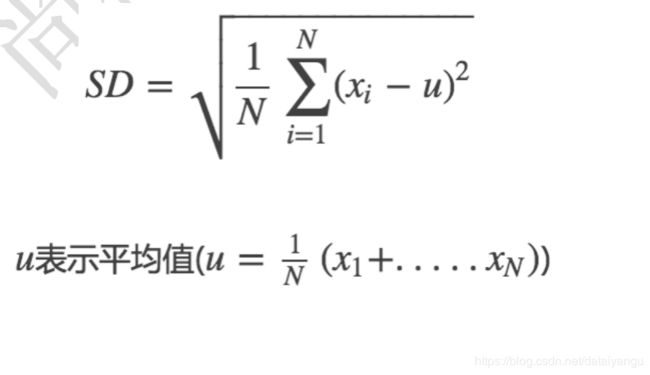
第4章凸优化算法
不严格的说,凸优化就是在标准优化问题的范畴内,要求目标函数和约束函数是凸函数的一类优化问题。
注意:中国大陆数学界某些机构关于函数凹凸性定义和国外的定义是相反的。Convex Function在某些中国大陆的数学书中指凹函数。Concave Function指凸函数。但在中国大陆涉及经济学的很多书中,凹凸性的提法和其他国家的提法是一致的,也就是和数学教材是反的。举个例子,同济大学高等数学教材对函数的凹凸性定义与本条目相反,本条目的凹凸性是指其上方图是凹集或凸集,而同济大学高等数学教材则是指其下方图是凹集或凸集,两者定义正好相反。
4.1梯度下降


4.2牛顿法



4.3拟牛顿法



4.4BFGS算法

第5章L1、L2正则化

5.1从经验风险最小化到结构经验最小化

5.2范数与正则项




5.3贝叶斯先验

第6章PCA降维
6.1数据降维的必要性
PCA(Principal Component Analysis)是一种常用的数据分析方法。PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维数据的降维。
一般情况下,在数据挖掘和机器学习中,数据被表示为向量。例如某个淘宝店2012年全年的流量及交易情况可以看成一组记录的集合,其中每一天的数据是一条记录,格式如下:
(日期, 浏览量, 访客数, 下单数, 成交数, 成交金额)
其中“日期”是一个记录标志而非度量值,而数据挖掘关心的大多是度量值,因此如果我们忽略日期这个字段后,我们得到一组记录,每条记录可以被表示为一个五维向量,其中一条看起来大约是这个样子:
我们当然可以对这一组五维向量进行分析和挖掘,不过我们知道,很多机器学习算法的复杂度和数据的维数有着密切关系,甚至与维数呈指数级关联。当然,这里区区五维的数据,也许还无所谓,但是实际机器学习中处理成千上万甚至几十万维的情况也并不罕见,在这种情况下,机器学习的资源消耗是不可接受的,因此我们必须对数据进行降维。
降维当然意味着信息的丢失,不过鉴于实际数据本身常常存在的相关性,我们可以想办法在降维的同时将信息的损失尽量降低。
举个例子,假如某学籍数据有两列M和F,其中M列的取值是如何此学生为男性取值1,为女性取值0;而F列是学生为女性取值1,男性取值0。此时如果我们统计全部学籍数据,会发现对于任何一条记录来说,当M为1时F必定为0,反之当M为0时F必定为1。在这种情况下,我们将M或F去掉实际上没有任何信息的损失,因为只要保留一列就可以完全还原另一列。
上面是一个极端的情况,在现实中也许不会出现,不过类似的情况还是很常见的。例如上面淘宝店铺的数据,从经验我们可以知道,“浏览量”和“访客数”往往具有较强的相关关系,而“下单数”和“成交数”也具有较强的相关关系。这里我们非正式的使用“相关关系”这个词,可以直观理解为“当某一天这个店铺的浏览量较高(或较低)时,我们应该很大程度上认为这天的访客数也较高(或较低)”。这种情况表明,如果我们删除浏览量或访客数其中一个指标,我们应该期待并不会丢失太多信息。因此我们可以删除一个,以降低机器学习算法的复杂度。
总之,我们需要降维来提高学习的效率以及防止学习过拟合的问题。那么
问题是我们到底删除哪一列损失的信息才最小?亦或根本不是单纯删除几列,而是通过某些变换将原始数据变为更少的列但又使得丢失的信息最小?到底如何度量丢失信息的多少?如何根据原始数据决定具体的降维操作步骤?
6.2PCA理论推导
既然我们面对的数据被抽象为一组向量,那么下面有必要研究一些向量的数学性质。而这些数学性质将成为后续导出PCA的理论基础。
6.2.1内积与投影
下面先来看一个向量运算:内积。两个维数相同的向量的内积被定义为:
内积运算将两个向量映射为一个实数。其计算方式非常容易理解,但是其意义并不明显。下面我们分析内积的几何意义。假设A和B是两个n维向量,我们知道n维向量可以等价表示为n维空间中的一条从原点发射的有向线段,为了简单起见我们假设A和B均为二维向量,则,。则在二维平面上A和B可以用两条发自原点的有向线段表示,见下图:
现在我们从A点向B所在直线引一条垂线。我们知道垂线与B的交点叫做A在B上的投影,再设A与B的夹角是a,则投影的矢量长度为,其中是向量A的模,也就是A线段的标量长度。
注意这里我们专门区分了矢量长度和标量长度,标量长度总是大于等于0,值就是线段的长度;而矢量长度可能为负,其绝对值是线段长度,而符号取决于其方向与标准方向相同或相反。
到这里还是看不出内积和这东西有什么关系,不过如果我们将内积表示为另一种我们熟悉的形式:
A与B的内积等于A到B的投影长度乘以B的模。再进一步,如果我们假设B的模为1,即让|B|=1,那么就变成了:
也就是说,设向量B的模为1,则A与B的内积值等于A向B所在直线投影的矢量长度!这就是内积的一种几何解释,也是我们得到的第一个重要结论。
6.2.2向量的基
一个二维向量可以对应二维笛卡尔直角坐标系中从原点出发的一个有向线段。例如下面这个向量:
在代数表示方面,我们经常用线段终点的点坐标表示向量,例如上面的向量可以表示为(3,2)。
不过我们常常忽略,只有一个(3,2)本身是不能够精确表示一个向量的。我们仔细看一下,这里的3实际表示的是向量在x轴上的投影值是3,在y轴上的投影值是2。也就是说我们其实隐式引入了一个定义:以x轴和y轴上正方向长度为1的向量为标准。那么一个向量(3,2)实际是说在x轴投影为3而y轴的投影为2。注意投影是一个矢量,所以可以为负。
更正式的说,向量(x,y)实际上表示线性组合:
不难证明所有二维向量都可以表示为这样的线性组合。此处(1,0)和(0,1)叫做二维空间中的一组基。
所以,要准确描述向量,首先要确定一组基,然后给出在基所在的各个直线上的投影值,就可以了。只不过我们经常省略第一步,而默认以(1,0)和(0,1)为基。
我们之所以默认选择(1,0)和(0,1)为基,当然是比较方便,因为它们分别是x和y轴正方向上的单位向量,因此就使得二维平面上点坐标和向量一一对应,非常方便。但实际上任何两个线性无关的二维向量都可以成为一组基,所谓线性无关在二维平面内可以直观认为是两个不在一条直线上的向量。
例如,(1,1)和(-1,1)也可以成为一组基。一般来说,我们希望基的模是1,因为从内积的意义可以看到,如果基的模是1,那么就可以方便的用向量点乘基而直接获得其在新基上的坐标了!实际上,对应任何一个向量我们总可以找到其同方向上模为1的向量,只要让两个分量分别除以模就好了。例如,上面的基可以变为。
现在,我们想获得(3,2)在新基上的坐标,即在两个方向上的投影矢量值,那么根据内积的几何意义,我们只要分别计算(3,2)和两个基的内积,不难得到新的坐标为。下图给出了新的基以及(3,2)在新基上坐标值的示意图:
另外这里要注意的是,我们列举的例子中基是正交的(即内积为0,或直观说相互垂直),但可以成为一组基的唯一要求就是线性无关,非正交的基也是可以的。不过因为正交基有较好的性质,所以一般使用的基都是正交的。
6.2.3矩阵的基变换
下面我们找一种简便的方式来表示基变换。还是拿上面的例子,想一下,将(3,2)变换为新基上的坐标,就是用(3,2)与第一个基做内积运算,作为第一个新的坐标分量,然后用(3,2)与第二个基做内积运算,作为第二个新坐标的分量。实际上,我们可以用矩阵相乘的形式简洁的表示这个变换:
其中矩阵的两行分别为两个基,乘以原向量,其结果刚好为新基的坐标。可以稍微推广一下,如果我们有m个二维向量,只要将二维向量按列排成一个两行m列矩阵,然后用“基矩阵”乘以这个矩阵,就得到了所有这些向量在新基下的值。例如(1,1),(2,2),(3,3),想变换到刚才那组基上,则可以这样表示:
于是一组向量的基变换被干净的表示为矩阵的相乘。
一般的,如果我们有M个N维向量,想将其变换为由R个N维向量表示的新空间中,那么首先将R个基按行组成矩阵A,然后将向量按列组成矩阵B,那么两矩阵的乘积AB就是变换结果,其中AB的第m列为A中第m列变换后的结果。
数学表示为:
其中是一个行向量,表示第i个基,是一个列向量,表示第j个原始数据记录。
特别要注意的是,这里R可以小于N,而R决定了变换后数据的维数。也就是说,我们可以将一N维数据变换到更低维度的空间中去,变换后的维度取决于基的数量。因此这种矩阵相乘的表示也可以表示降维变换。
最后,上述分析同时给矩阵相乘找到了一种物理解释:两个矩阵相乘的意义是将右边矩阵中的每一列列向量变换到左边矩阵中每一行行向量为基所表示的空间中去。更抽象的说,一个矩阵可以表示一种线性变换。很多同学在学线性代数时对矩阵相乘的方法感到奇怪,但是如果明白了矩阵相乘的物理意义,其合理性就一目了然了。
6.2.4协方差矩阵及优化目标
如果基的数量少于向量本身的维数,则可以达到降维的效果。但是我们还没有回答一个最最关键的问题:如何选择基才是最优的。或者说,如果我们有一组N维向量,现在要将其降到K维(K小于N),那么我们应该如何选择K个基才能最大程度保留原有的信息?
假设我们的数据由五条记录组成,将它们表示成矩阵形式:
其中每一列为一条数据记录,而一行为一个字段。为了后续处理方便,我们首先将每个字段内所有值都减去字段均值,其结果是将每个字段都变为均值为0(这样做的道理和好处后面会看到)。
我们看上面的数据,第一个字段均值为2,第二个字段均值为3,所以变换后:
我们可以看下五条数据在平面直角坐标系内的样子:
问题来了:如果我们必须使用一维来表示这些数据,又希望尽量保留原始的信息,你要如何选择?
通过上一节对基变换的讨论我们知道,这个问题实际上是要在二维平面中选择一个方向,将所有数据都投影到这个方向所在直线上,用投影值表示原始记录。这是一个实际的二维降到一维的问题。
那么如何选择这个方向(或者说基)才能尽量保留最多的原始信息呢?一种直观的看法是:希望投影后的投影值尽可能分散。
以上图为例,可以看出如果向x轴投影,那么最左边的两个点会重叠在一起,中间的两个点也会重叠在一起,于是本身四个各不相同的二维点投影后只剩下两个不同的值了,这是一种严重的信息丢失,同理,如果向y轴投影最上面的两个点和分布在x轴上的两个点也会重叠。所以看来x和y轴都不是最好的投影选择。我们直观目测,如果向通过第一象限和第三象限的斜线投影,则五个点在投影后还是可以区分的。
下面,我们用数学方法表述这个问题。
6.2.4.1 方差
上文说到,我们希望投影后投影值尽可能分散,而这种分散程度,可以用数学上的方差来表述。此处,一个字段的方差可以看做是每个元素与字段均值的差的平方和的均值,即:
由于上面我们已经将每个字段的均值都化为0了,因此方差可以直接用每个元素的平方和除以元素个数表示:
于是上面的问题被形式化表述为:寻找一个一维基,使得所有数据变换为这个基上的坐标表示后,方差值最大。
6.2.4.2 协方差
对于上面二维降成一维的问题来说,找到那个使得方差最大的方向就可以了。不过对于更高维,还有一个问题需要解决。考虑三维降到二维问题。与之前相同,首先我们希望找到一个方向使得投影后方差最大,这样就完成了第一个方向的选择,继而我们选择第二个投影方向。
如果我们还是单纯只选择方差最大的方向,很明显,这个方向与第一个方向应该是“几乎重合在一起”,显然这样的维度是没有用的,因此,应该有其他约束条件。从直观上说,让两个字段尽可能表示更多的原始信息,我们是不希望它们之间存在(线性)相关性的,因为相关性意味着两个字段不是完全独立,必然存在重复表示的信息。
数学上可以用两个字段的协方差表示其相关性,由于已经让每个字段均值为0,则:
可以看到,在字段均值为0的情况下,两个字段的协方差简洁的表示为其内积除以元素数m。
当协方差为0时,表示两个字段完全独立。为了让协方差为0,我们选择第二个基时只能在与第一个基正交的方向上选择。因此最终选择的两个方向一定是正交的。
至此,我们得到了降维问题的优化目标:将一组N维向量降为K维(K大于0,小于N),其目标是选择K个单位(模为1)正交基,使得原始数据变换到这组基上后,各字段两两间协方差为0,而字段的方差则尽可能大(在正交的约束下,取最大的K个方差)。
6.2.4.3 协方差矩阵
上面我们导出了优化目标,但是这个目标似乎不能直接作为操作指南(或者说算法),因为它只说要什么,但根本没有说怎么做。所以我们要继续在数学上研究计算方案。
我们看到,最终要达到的目的与字段内方差及字段间协方差有密切关系。因此我们希望能将两者统一表示,仔细观察发现,两者均可以表示为内积的形式,而内积又与矩阵相乘密切相关。于是我们来了灵感:
假设我们只有a和b两个字段,那么我们将它们按行组成矩阵X:
然后我们用X乘以X的转置,并乘上系数1/m:
奇迹出现了!这个矩阵对角线上的两个元素分别是两个字段的方差,而其它元素是a和b的协方差。两者被统一到了一个矩阵的。
根据矩阵相乘的运算法则,这个结论很容易被推广到一般情况:
设我们有m个n维数据记录,将其按列排成n乘m的矩阵X,设C=1mXXC=1mXXT,则C是一个对称矩阵,其对角线分别个各个字段的方差,而第i行j列和j行i列元素相同,表示i和j两个字段的协方差。
6.2.4.4 协方差矩阵对角化
根据上述推导,我们发现要达到优化目前,等价于将协方差矩阵对角化:即除对角线外的其它元素化为0,并且在对角线上将元素按大小从上到下排列,这样我们就达到了优化目的。这样说可能还不是很明晰,我们进一步看下原矩阵与基变换后矩阵协方差矩阵的关系:
设原始数据矩阵X对应的协方差矩阵为C,而P是一组基按行组成的矩阵,设Y=PX,则Y为X对P做基变换后的数据。设Y的协方差矩阵为D,我们推导一下D与C的关系:
现在事情很明白了!我们要找的P不是别的,而是能让原始协方差矩阵对角化的P。换句话说,优化目标变成了寻找一个矩阵P,满足PCPPCPT是一个对角矩阵,并且对角元素按从大到小依次排列,那么P的前K行就是要寻找的基,用P的前K行组成的矩阵乘以X就使得X从N维降到了K维并满足上述优化条件。
现在所有焦点都聚焦在了协方差矩阵对角化问题上,由上文知道,协方差矩阵C是一个是对称矩阵,在线性代数上,实对称矩阵有一系列非常好的性质:
1)实对称矩阵不同特征值对应的特征向量必然正交。
2)设特征向量λλ重数为r,则必然存在r个线性无关的特征向量对应于λλ,因此可以将这r个特征向量单位正交化。
由上面两条可知,一个n行n列的实对称矩阵一定可以找到n个单位正交特征向量,设这n个特征向量为,我们将其按列组成矩阵:
则对协方差矩阵C有如下结论:
其中ΛΛ为对角矩阵,其对角元素为各特征向量对应的特征值(可能有重复)。
到这里,我们发现我们已经找到了需要的矩阵P:
P是协方差矩阵的特征向量单位化后按行排列出的矩阵,其中每一行都是C的一个特征向量。如果设P按照ΛΛ中特征值的从大到小,将特征向量从上到下排列,则用P的前K行组成的矩阵乘以原始数据矩阵X,就得到了我们需要的降维后的数据矩阵Y。
6.3算法及实例
6.3.1PCA算法
总结一下PCA的算法步骤:
设有m条n维数据。
1)将原始数据按列组成n行m列矩阵X
2)将X的每一行(代表一个属性字段)进行零均值化,即减去这一行的均值
3)求出协方差矩阵
4)求出协方差矩阵的特征值及对应的特征向量
5)将特征向量按对应特征值大小从上到下按行排列成矩阵,取前k行组成矩阵P
6)Y=PX即为降维到k维后的数据
6.3.2实例
这里以上文提到的
为例,我们用PCA方法将这组二维数据其降到一维。
因为这个矩阵的每行已经是零均值,这里我们直接求协方差矩阵:
然后求其特征值和特征向量,具体求解方法不再详述,可以参考相关资料。求解后特征值为:
其对应的特征向量分别是:
其中对应的特征向量分别是一个通解,c1c1和c2c2可取任意实数。那么标准化后的特征向量为:
因此我们的矩阵P是:
可以验证协方差矩阵C的对角化:
最后我们用P的第一行乘以数据矩阵,就得到了降维后的表示:
降维投影结果如下图:
第7章ICA降维
7.1PCA存在的问题
上面提到的PCA是一种数据降维的方法,但是只对符合高斯分布的样本点比较有效,那么对于其他分布的样本,有没有主元分解的方法呢?
比如经典的鸡尾酒宴会问题(cocktail party problem)。假设在party中有n个人,他们可以同时说话,我们也在房间中一些角落里共放置了n个声音接收器(Microphone)用来记录声音。宴会过后,我们从n个麦克风中得到了一组数据,i表示采样的时间顺序,也就是说共得到了m组采样,每一组采样都是n维的。我们的目标是单单从这m组采样数据中分辨出每个人说话的信号。
将第二个问题细化一下,有n个信号源,,每一维都是一个人的声音信号,每个人发出的声音信号独立。A是一个未知的混合矩阵(mixing matrix),用来组合叠加信号s,那么
x的意义在上文解释过,这里的x不是一个向量,是一个矩阵。其中每个列向量是,
表示成图就是
的每个分量都由的分量线性表示。A和s都是未知的,x是已知的,我们要想办法根据x来推出s。这个过程也称作为盲信号分离。
令,那么
将W表示成
其中,其实就是将写成行向量形式。那么得到:
7.2ICA的不确定性
由于w和s都不确定,那么在没有先验知识的情况下,无法同时确定这两个相关参数。比如上面的公式s=wx。当w扩大两倍时,s只需要同时扩大两倍即可,等式仍然满足,因此无法得到唯一的s。同时如果将人的编号打乱,变成另外一个顺序,如上图的蓝色节点的编号变为3,2,1,那么只需要调换A的列向量顺序即可,因此也无法单独确定s。这两种情况称为原信号不确定。
还有一种ICA不适用的情况,那就是信号不能是高斯分布的。假设只有两个人发出的声音信号符合多值正态分布,,I是2*2的单位矩阵,s的概率密度函数就不用说了吧,以均值0为中心,投影面是椭圆的山峰状(参见多值高斯分布)。因为,因此,x也是高斯分布的,均值为0,协方差为。
令R是正交阵,。如果将A替换成A’。那么。s分布没变,因此x’仍然是均值为0,协方差。
因此,不管混合矩阵是A还是A’,x的分布情况是一样的,那么就无法确定混合矩阵,也就无法确定原信号。
7.3密度函数和线性变换
在讨论ICA具体算法之前,我们先来回顾一下概率和线性代数里的知识。
假设我们的随机变量s有概率密度函数(连续值是概率密度函数,离散值是概率)。为了简单,我们再假设s是实数,还有一个随机变量x=As,A和x都是实数。令是x的概率密度,那么怎么求?
令,首先将式子变换成,然后得到,求解完毕。可惜这种方法是错误的。比如s符合均匀分布的话(),那么s的概率密度是,现在令A=2,即x=2s,也就是说x在[0,2]上均匀分布,可知。然而,前面的推导会得到。正确的公式应该是
推导方法
更一般地,如果s是向量,A可逆的方阵,那么上式子仍然成立。
7.4ICA算法
ICA算法归功于Bell和Sejnowski,这里使用最大似然估计来解释算法,原始的论文中使用的是一个复杂的方法Infomax principal。
我们假定每个有概率密度,那么给定时刻原信号的联合分布就是
这个公式代表一个假设前提:每个人发出的声音信号各自独立。有了p(s),我们可以求得p(x)
左边是每个采样信号x(n维向量)的概率,右边是每个原信号概率的乘积的|W|倍。
前面提到过,如果没有先验知识,我们无法求得W和s。因此我们需要知道,我们打算选取一个概率密度函数赋给s,但是我们不能选取高斯分布的密度函数。在概率论里我们知道密度函数p(x)由累计分布函数(cdf)F(x)求导得到。F(x)要满足两个性质是:单调递增和在[0,1]。我们发现sigmoid函数很适合,定义域负无穷到正无穷,值域0到1,缓慢递增。我们假定s的累积分布函数符合sigmoid函数
求导后
这就是s的密度函数。这里s是实数。
如果我们预先知道s的分布函数,那就不用假设了,但是在缺失的情况下,sigmoid函数能够在大多数问题上取得不错的效果。由于上式中是个对称函数,因此E[s]=0(s的均值为0),那么E[x]=E[As]=0,x的均值也是0。
知道了,就剩下W了。给定采样后的训练样本,样本对数似然估计如下:
使用前面得到的x的概率密度函数,得
大括号里面是。
接下来就是对W求导了,这里牵涉一个问题是对行列式|W|进行求导的方法,属于矩阵微积分。这里先给出结果,在文章最后再给出推导公式。
最终得到的求导后公式如下,的导数为(可以自己验证):
其中是梯度上升速率,人为指定。
当迭代求出W后,便可得到来还原出原始信号。
注意:我们计算最大似然估计时,假设了与之间是独立的,然而对于语音信号或者其他具有时间连续依赖特性(比如温度)上,这个假设不能成立。但是在数据足够多时,假设独立对效果影响不大,同时如果事先打乱样例,并运行随机梯度上升算法,那么能够加快收敛速度。
回顾一下鸡尾酒宴会问题,s是人发出的信号,是连续值,不同时间点的s不同,每个人发出的信号之间独立(和之间独立)。s的累计概率分布函数是sigmoid函数,但是所有人发出声音信号都符合这个分布。A(W的逆阵)代表了s相对于x的位置变化,x是s和A变化后的结果。
7.5实例
s=2时的原始信号
观察到的x信号
使用ICA还原后的s信号
对行列式求导,设矩阵A是n×n的,我们知道行列式与代数余子式有关,
是去掉第i行第j列后的余子式,那么对求导得
adj(A)跟我们线性代数中学的是一个意思,因此
第8章非平衡数据处理
8.1过采样
8.2欠采样
8.3Informed Understanding
8.4综合采样
第9章模型优化
第10章损失函数
10.1对数损失函数(逻辑回归)
10.2平方损失函数(最小二乘法,Ordinary Least Squares)
10.3指数损失函数(Adaboost)
10.4Hinge损失函数(SVM)
10.4.1Hinge损失函数(SVM)
10.4.2逻辑斯谛回归和SVM的损失函数对比
第11章矩阵奇异值分解SVD
11.1简介
11.2奇异值分解
11.3应用实例
第12章线性回归算法
12.1数学模型
线性回归是利用被称为线性回归方程的最小平方函数对一个或者多个自变量和因变量之间关系进行建模的一种回归分析。这种函数式一个或者多个被称为回归系数的模型参数的线性组合。
在统计学中,线性回归(Linear Regression)是利用称为线性回归方程的最小平方函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。这种函数是一个或多个称为回归系数的模型参数的线性组合。
回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
下面我们来举例何为一元线性回归分析,图1为某地区的房屋面积(feet)与价格( ) 的 一 个 数 据 集 , 在 该 数 据 集 中 , 只 有 一 个 自 变 量 面 积 ( f e e t ) , 和 一 个 因 变 量 价 格 ( )的一个数据集,在该数据集中,只有一个自变量面积(feet),和一个因变量价格( )的一个数据集,在该数据集中,只有一个自变量面积(feet),和一个因变量价格(),所以我们可以将数据集呈现在二维空间上,如图2所示。利用该数据集,我们的目的是训练一个线性方程,无限逼近所有数据点,然后利用该方程与给定的某一自变量(本例中为面积),可以预测因变量(本例中为房价)。本例中,训练所得的线性方程如图3所示。
图1、房价与面积对应数据集
图2、二维空间上的房价与面积对应图
图3、线性逼近
同时,分析得到的线性方程为:
接下来还是该案例,举一个多元线性回归的例子。如果增添了一个自变量:房间数,那么数据集可以如下所示:
图4、房价与面积、房间数对应数据集
那么,分析得到的线性方程应如下所示:
因此,无论是一元线性方程还是多元线性方程,可统一写成如下的格式:
上式中x0=1,而求线性方程则演变成了求方程的参数ΘT。
线性回归假设特征和结果满足线性关系。其实线性关系的表达能力非常强大,每个特征对结果的影响强弱可以有前面的参数体现,而且每个特征变量可以首先映射到一个函数,然后再参与线性计算,这样就可以表达特征与结果之间的非线性关系。
12.2损失函数
12.2.1损失函数
上面的公式的参数向量θ是n+1维的,每个参数的取值是实数集合,也就是说参数向量θ在n+1维实数空间中取值结果有无穷种可能。
那么,如何利用一个规则或机制帮助我们评估求得的参数θ,并且使得线性模型效果最佳呢?直观地认为,如果求得参数θ线性求和后,得到的结果与真实值yy之差越小越好。
这时我们需要映入一个函数来衡量表示真实值y好坏的程度,该函数称为损失函数(loss function,也称为错误函数)。数学表示如下:
这个损失函数用的是的预测值与真实值之差的平方和。如果不考虑诸如过拟合等其他问题,这就是我们需要优化的目标函数。
12.2.2目标函数的概率解释
一般地,机器学习中不同的模型会有相应的目标函数。而回归模型(尤其是线性回归类)的目标函数通常用平方损失函数来作为优化的目标函数(即真实值与预测值之差的平方和)。为什么要选用误差平方和作为目标函数呢?答案可以从概率论中的中心极限定理、高斯分布等知识中找到。
12.2.2.1 中心极限定理
目标函数的概率解释需要用到中心极限定理。中心极限定理本身就是研究独立随机变量和的极限分布为正态分布的问题。
中心极限定理的公式表示为:
设n个随机变量X1,X2,···,Xn相互独立,均具有相同的数学期望与方差,即,令为随机变量之和,有
称随机变量Zn为n个随机变量X1,X2,···,Xn的规范和。
它的定义为:
设从均值为μ、方差为σ2(有限)的任意一个总体中抽取样本量为n的样本,当n充分大时,样本均值的抽样分布近似服从于均值为μ、方差为σ2的正态分布。
12.2.2.2 高斯分布
假设给定一个输入样例根据公式得到预测值与真实值之间存在误差,即为。那么,它们之间的关系表示如下:
而这里假设误差服从标准高斯分布是合理的。
解释如下:
回归模型的最终目标是通过函数表达式建立自变量x与结果y之间的关系,希望通过x能较为准确地表示结果y。而在实际的应用场合中,很难甚至不可能把导致y的所有变量(特征)都找出来,并放到回归模型中。那么模型中存在的x通常认为是影响结果y最主要的变量集合(又称为因子,在ML中称为特征集)。根据中心极限定理,把那些对结果影响比较小的变量(假设独立同分布)之和认为服从正态分布是合理的。
可以用一个示例来说明误差服从高斯分布是合理的:
在例子中,根据训练数据建立房屋的面积x与房屋的售价y之间的函数表达。它的数据集把房屋面积作为最为主要的变量。除此之外我们还知道房屋所在的地段(地铁、学区、城区、郊区),周边交通状况,当地房价、楼层、采光、绿化面积等等诸多因素会影响房价。
实际上,因数据收集问题可能拿不到所有影响房屋售价的变量,可以假设多个因素变量相互独立,根据中心极限定理,认为变量之和服从高斯分布。即:
那么x和y的条件概率可表示为:
12.2.2.3 极大似然估计与损失函数极小化等价
根据上述公式估计得到一条样本的结果概率,模型的最终目标是希望在全部样本上预测最准,也就是概率积最大,这个概率积就是似然函数。优化的目标函数即为似然函数,表示如下:
对L(x)取对数,可得对数似然函数:
由于n,σ都为常数,因此上式等价于
我们可以发现,经过最大似然估计推导出来的待优化的目标函数与平方损失函数是等价的。因此可以得出结论:
线性回归误差平方损失极小化与极大似然估计等价。其实在概率模型中,目标函数的原函数(或对偶函数)极小化(或极大化)与极大似然估计等价,这是一个带有普遍性的结论。比如在最大熵模型中,有对偶函数极大化与极大似然估计等价的结论。
那上面为什么是条件概率p(y|x;θ)呢?因为我们希望预测值与真实值更接近,这就意味着希望求出来的参数θ,在给定输入x的情况下,得到的预测值等于真实值得可能性越大越好。而θ,x均为前提条件,因此用条件概率p(y|x;θ) 表示。即p(y|x;θ) 越大,越能说明估计的越准确。当然也不能一味地只有该条件函数,还要考虑拟合过度以及模型的泛化能力问题。
12.3最小二乘法
通过观察或者求二阶导数可知,是一个凸函数,
将m个n维样本组成矩阵X:
则目标函数的矩阵形式为
凸函数有最小值,即导数为0,
令其为零,求得驻点:
若XTX不可逆,不可使用
实际中,若XTX阶过高,仍然需要使用梯度下降的方式计算数值解。
12.4梯度下降
我们可以将函数最小值求解想象成下山操作。
一个在山顶的人的下山逻辑:
1、找到下山最快的坡度
2、沿着这个坡度走一段距离a。
3、重复1、2步骤,直到到山底
梯度下降一般分为批量梯度下降算法和随机梯度下降算法。
不同点在于重新选择梯度方向的时候,是否计算所有的样本集。
梯度下降算法的描述如下:
1)初始化θ(随机初始化)
2)迭代,新的θ能够使得J(θ)更小
3)如果J(θ)能够继续减少不收敛,返回2)
4)α称为学习率
收敛条件:J(θ)不再变化、或者变化小于某个阈值
每一次迭代,改变值如下:
针对于更新值,批量梯度下降算法如下:算法复杂度O(mn)
可以看出,参数θ的值每更新一次都要遍历样本集中的所有的样本,得到新的θj,看是否满足阈值要求,若满足,则迭代结束,根据此值就可以得到;否则继续迭代。注意到,虽然梯度下降法易受到极小值的影响,但是一般的线性规划问题只有一个极小值,所以梯度下降法一般可以收敛到全局的最小值。例如,J是二次凸函数,则梯度下降法的示意图为:
图中,一圈上表示目标函数的函数值类似于地理上的等高线,从外圈开始逐渐迭代,最终收敛全局最小值。
随机梯度下降算法如下表示:算法复杂度O(n)
在这个算法中,我们每次更新只用到一个训练样本,若根据当前严格不能进行迭代得到一个,此时会得到一个,有新样本进来之后,在此基础上继续迭代,又得到一组新的和,以此类推。
批量梯度下降法,每更新一次,需要用到样本集中的所有样本;随机梯度下降法,每更新一次,只用到训练集中的一个训练样本,所以一般来说,随机梯度下降法能更快地使目标函数达到最小值(新样本的加入,随机梯度下降法有可能会使目标函数突然变大,迭代过程中在变小。所以是在全局最小值附近徘徊,但对于实际应用俩说,误差完全能满足要求)。另外,对于批量梯度下降法,如果样本集增加了一些训练样本,就要重新开始迭代。由于以上原因,当训练样本集较大时,一般使用随机梯度下降法。
下降的梯度即为导数的负数:
一个很重要的地方值得注意的是,梯度是有方向的,对于一个向量θ,每一维分量θi都可以求出一个梯度的方向,我们就可以找到一个整体的方向,在变化的时候,我们就朝着下降最多的方向进行变化就可以达到一个最小点,不管他是全局的还是局部的。
在对目标函数J(θ)求偏导时,可以用更简单的数学语言(倒三角表示梯度)进行描述:
12.5Spark MLlib实现
第13章逻辑回归算法
13.1逻辑斯谛分布
介绍逻辑斯谛回归模型之前,首先看一个并不常见的概率分布,即逻辑斯谛分布。设X是连续随机变量,X服从逻辑斯谛分布是指X具有下列的分布函数和密度函数:
式中,μ为位置参数,γ>0为形状参数。逻辑斯谛的分布的密度函数f(x)和分布函数F(x)的图形如下图所示。其中分布函数属于逻辑斯谛函数,其图形为一条S形曲线。该曲线以点(μ,1/2)为中心对称,即满足
曲线在中心附近增长较快,在两端增长速度较慢。形状参数γ的值越小,曲线在中心附近增长得越快。
13.2逻辑回归模型
线性回归的应用场合大多是回归分析,一般不用在分类问题上。原因可以概括为以下两个:
1)回归模型是连续型模型,即预测出的值都是连续值(实数值),非离散值;
2)预测结果受样本噪声的影响比较大。
13.2.1逻辑回归模型表达式
LR模型表达式为参数化的逻辑斯谛函数(默认参数μ=0,γ=1),即
其中作为事件结果y=1的概率取值。这里, ,y∈{1,0}, 是权值向量。其中权值向量w中包含偏置项,即
13.2.2理解逻辑回归模型
13.2.2.1 对数几率
13.2.2.2 函数映射
13.2.2.3 概率解释
13.3模型参数估计
13.3.1Sigmoid函数
以下的推导中会用到,带来了很大的便利。
13.3.2参数估计推导
13.3.3分类边界
13.4延伸
13.4.1生成模型和判别模型
13.4.2多分类
13.5应用
13.6LR与SVM
第14章贝叶斯分类算法
14.1朴素贝叶斯分类算法概述
14.1.1分类问题
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。
对于分类问题,其实谁都不会陌生,说我们每个人每天都在执行分类操作一点都不夸张,只是我们没有意识到罢了。例如,当你看到一个陌生人,你的脑子下意识判断TA是男是女;你可能经常会走在路上对身旁的朋友说“这个人一看就很有钱、那边有个非主流”之类的话,其实这就是一种分类操作。
从数学角度来说,分类问题可做如下定义:
已知集合: 和,确定映射规则,使得任意有且仅有一个使得成立。其中C叫做类别集合,其中每一个元素是一个类别,而I叫做项集合,其中每一个元素是一个待分类项,f叫做分类器。分类算法的任务就是构造分类器f。
这里要着重强调,分类问题往往采用经验性方法构造映射规则,即一般情况下的分类问题缺少足够的信息来构造100%正确的映射规则,而是通过对经验数据的学习从而实现一定概率意义上正确的分类,因此所训练出的分类器并不是一定能将每个待分类项准确映射到其分类,分类器的质量与分类器构造方法、待分类数据的特性以及训练样本数量等诸多因素有关。
例如,医生对病人进行诊断就是一个典型的分类过程,任何一个医生都无法直接看到病人的病情,只能观察病人表现出的症状和各种化验检测数据来推断病情,这时医生就好比一个分类器,而这个医生诊断的准确率,与他当初受到的教育方式(构造方法)、病人的症状是否突出(待分类数据的特性)以及医生的经验多少(训练样本数量)都有密切关系。
14.1.2贝叶斯定理
贝叶斯定理是所有贝叶斯分类算法的核心:已知某条件概率,如何得到两个事件交换后的概率,也就是在已知P(A|B)的情况下如何求得P(B|A)。这里先解释什么是条件概率:
表示事件B已经发生的前提下,事件A发生的概率,叫做事件B发生下事件A的条件概率。其基本求解公式为:。
贝叶斯定理之所以有用,是因为我们在生活中经常遇到这种情况:我们可以很容易直接得出P(A|B),P(B|A)则很难直接得出,但我们更关心P(B|A),贝叶斯定理就为我们打通从P(A|B)获得P(B|A)的道路。
下面不加证明地直接给出贝叶斯定理:
条件概率的乘法定理如下:
全概率公式如下:
贝叶斯公式如下:
14.1.3特征条件独立假设
14.1.4朴素贝叶斯分类原理
朴素贝叶斯分类是一种十分简单的分类算法,叫它朴素贝叶斯分类是因为这种方法的思想真的很朴素,朴素贝叶斯的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。通俗来说,就好比这么个道理,你在街上看到一个黑人,我问你你猜这哥们哪里来的,你十有八九猜非洲。为什么呢?因为黑人中非洲人的比率最高,当然人家也可能是美洲人或亚洲人,但在没有其它可用信息下,我们会选择条件概率最大的类别,这就是朴素贝叶斯的思想基础。
朴素贝叶斯分类的正式定义如下:
1、设为一个待分类项,而每个a为x的一个特征属性。
2、有类别集合。
3、计算。
4、如果,则。
那么现在的关键就是如何计算第3步中的各个条件概率。我们可以这么做:
1、找到一个已知分类的待分类项集合,这个集合叫做训练样本集。
2、统计得到在各类别下各个特征属性的条件概率估计。即
。
3、如果各个特征属性是条件独立的,则根据贝叶斯定理有如下推导:
因为分母对于所有类别为常数,因为我们只要将分子最大化皆可。又因为各特征属性是条件独立的,所以有:
根据上述分析,朴素贝叶斯分类的流程可以由下图表示:
可以看到,整个朴素贝叶斯分类分为三个阶段:
第一阶段——准备工作阶段,这个阶段的任务是为朴素贝叶斯分类做必要的准备,主要工作是根据具体情况确定特征属性,并对每个特征属性进行适当划分,然后由人工对一部分待分类项进行分类,形成训练样本集合。这一阶段的输入是所有待分类数据,输出是特征属性和训练样本。这一阶段是整个朴素贝叶斯分类中唯一需要人工完成的阶段,其质量对整个过程将有重要影响,分类器的质量很大程度上由特征属性、特征属性划分及训练样本质量决定。
第二阶段——分类器训练阶段,这个阶段的任务就是生成分类器,主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率估计,并将结果记录。其输入是特征属性和训练样本,输出是分类器。这一阶段是机械性阶段,根据前面讨论的公式可以由程序自动计算完成。
第三阶段——应用阶段。这个阶段的任务是使用分类器对待分类项进行分类,其输入是分类器和待分类项,输出是待分类项与类别的映射关系。这一阶段也是机械性阶段,由程序完成。
1.4.2、估计类别下特征属性划分的条件概率及Laplace校准
这一节讨论P(a|y)的估计。
由上面看出,计算各个划分的条件概率P(a|y)是朴素贝叶斯分类的关键性步骤,当特征属性为离散值时,只要很方便的统计训练样本中各个划分在每个类别中出现的频率即可用来估计P(a|y),下面重点讨论特征属性是连续值的情况。
当特征属性为连续值时,通常假定其值服从高斯分布(也称正态分布)。即概率函数如下:
而
因此只要计算出训练样本中各个类别中此特征项划分的各均值和标准差,代入上述公式即可得到需要的估计值。均值与标准差的计算在此不再赘述。
另一个需要讨论的问题就是当P(a|y)=0怎么办,当某个类别下某个特征项划分没有出现时,就是产生这种现象,这会令分类器质量大大降低。为了解决这个问题,我们引入Laplace校准,它的思想非常简单,就是对没类别下所有划分的计数加1,这样如果训练样本集数量充分大时,并不会对结果产生影响,并且解决了上述频率为0的尴尬局面。
14.1.5朴素贝叶斯分类算法演示:检测SNS社区中不真实账号
这个问题是这样的,对于SNS(社交网络)社区来说,不真实账号(使用虚假身份或用户的小号)是一个普遍存在的问题,作为SNS社区的运营商,希望可以检测出这些不真实账号,从而在一些运营分析报告中避免这些账号的干扰,亦可以加强对SNS社区的了解与监管。
如果通过纯人工检测,需要耗费大量的人力,效率也十分低下,如能引入自动检测机制,必将大大提升工作效率。这个问题说白了,就是要将社区中所有账号在真实账号和不真实账号两个类别上进行分类,下面我们一步一步实现这个过程。
首先设C=0表示真实账号,C=1表示不真实账号。
1、确定特征属性及划分
这一步要找出可以帮助我们区分真实账号与不真实账号的特征属性,在实际应用中,特征属性的数量是很多的,划分也会比较细致,但这里为了简单起见,我们用少量的特征属性以及较粗的划分,并对数据做了修改。
我们选择三个特征属性:a1:日志数量/注册天数,a2:好友数量/注册天数,a3:是否使用真实头像。在SNS社区中这三项都是可以直接从数据库里得到或计算出来的。
下面给出划分:a1:{a<=0.05, 0.05
2、获取训练样本
假设这里使用运维人员曾经人工检测过的1万个账号作为训练样本。
3、计算训练样本中每个类别的频率
用训练样本中真实账号和不真实账号数量分别除以一万,得到:
4、计算每个类别条件下各个特征属性划分的频率
5、使用分类器进行鉴别
下面我们使用上面训练得到的分类器鉴别一个账号,这个账号使用非真实头像,日志数量与注册天数的比率为0.1,好友数与注册天数的比率为0.2。
可以看到,虽然这个用户没有使用真实头像,但是通过分类器的鉴别,更倾向于将此账号归入真实账号类别。这个例子也展示了当特征属性充分多时,朴素贝叶斯分类对个别属性的抗干扰性。
关于对分类器的评价,首先要定义,分类器的正确率指分类器正确分类的项目占所有被分类项目的比率。
通常使用回归测试来评估分类器的准确率,最简单的方法是用构造完成的分类器对训练数据进行分类,然后根据结果给出正确率评估。但这不是一个好方法,因为使用训练数据作为检测数据有可能因为过分拟合而导致结果过于乐观,所以一种更好的方法是在构造初期将训练数据一分为二,用一部分构造分类器,然后用另一部分检测分类器的准确率。
14.2朴素贝叶斯参数估计
14.2.1极大似然估计
14.2.2贝叶斯估计
14.3贝叶斯网络算法概述
14.3.1算法概述
朴素贝叶斯分类有一个限制条件,就是特征属性必须有条件独立或基本独立(实际上在现实应用中几乎不可能做到完全独立)。当这个条件成立时,朴素贝叶斯分类法的准确率是最高的,但不幸的是,现实中各个特征属性间往往并不条件独立,而是具有较强的相关性,这样就限制了朴素贝叶斯分类的能力。
贝叶斯网络(Bayesian network),又称信念网络(Belief Network),或有向无环图模型(directed acyclic graphical model),是一种概率图模型,于1985年由Judea Pearl首先提出。它是一种模拟人类推理过程中因果关系的不确定性处理模型,其网络拓朴结构是一个有向无环图(DAG)。
贝叶斯网络的有向无环图中的节点表示随机变量,它们可以是可观察到的变量,或隐变量、未知参数等。认为有因果关系(或非条件独立)的变量或命题则用箭头来连接(换言之,连接两个节点的箭头代表此两个随机变量是具有因果关系,或非条件独立)。若两个节点间以一个单箭头连接在一起,表示其中一个节点是“因(parents)”,另一个是“果(children)”,两节点就会产生一个条件概率值。
例如,假设节点E直接影响到节点H,即E→H,则用从E指向H的箭头建立结点E到结点H的有向弧(E,H),权值(即连接强度)用条件概率P(H|E)来表示,如下图所示:
简言之,把某个研究系统中涉及的随机变量,根据是否条件独立绘制在一个有向图中,就形成了贝叶斯网络。其主要用来描述随机变量之间的条件依赖,用圈表示随机变量(random variables),用箭头表示条件依赖(conditional dependencies)。
令G = (I,E)表示一个有向无环图(DAG),其中I代表图形中所有的节点的集合,而E代表有向连接线段的集合,且令X = (Xi)i ∈ I为其有向无环图中的某一节点i所代表的随机变量,若节点X的联合概率可以表示成:
则称X为相对于一有向无环图G 的贝叶斯网络,其中,表示节点i之“因”,或称pa(i)是i的parents(父母)。
此外,对于任意的随机变量,其联合概率可由各自的局部条件概率分布相乘而得出:
如下图所示,便是一个简单的贝叶斯网络:
从图上可以比较直观的看出:
-
x1,x2,…x7的联合分布为
-
x1和x2独立(对应head-to-head);
-
x6和x7在x4给定的条件下独立(对应tail-to-tail)。
根据上图,第1点可能很容易理解,但第2、3点中所述的条件独立是啥意思呢?其实第2、3点是贝叶斯网络中3种结构形式中的其中二种。为了说清楚这个问题,需要引入D-Separation(D-分离)这个概念。
D-Separation是一种用来判断变量是否条件独立的图形化方法。换言之,对于一个DAG(有向无环图)E,D-Separation方法可以快速的判断出两个节点之间是否是条件独立的。贝叶斯网络有三种链接结构:
形式1:head-to-head
贝叶斯网络的第一种结构形式如下图所示:
所以有:P(a,b,c) = P(a)*P(b)*P(c|a,b)成立,化简后可得:
即在c未知的条件下,a、b被阻断(blocked),是独立的,称之为head-to-head条件独立。
形式2:tail-to-tail
贝叶斯网络的第二种结构形式如下图所示
有P(a,b,c)=P©*P(a|c)*P(b|c),则:P(a,b|c)=P(a,b,c)/P©,然后将P(a,b,c)=P©*P(a|c)*P(b|c)带入上式,得到:P(a,b|c)=P(a|c)*P(b|c)。
即在c给定的条件下,a,b被阻断(blocked),是独立的,称之为tail-to-tail条件独立,对应本节中最开始那张图中的“x6和x7在x4给定的条件下独立”。
形式3:head-to-tail
贝叶斯网络的第三种结构形式如下图所示:
有:P(a,b,c)=P(a)*P(c|a)*P(b|c)。
化简后可得:
即:在c给定的条件下,a,b被阻断(blocked),是独立的,称之为head-to-tail条件独立。
14.3.2应用案例
胸部疾病诊所(Chest Clinic)
假想你是Los Angeles一名新毕业的医生,专攻肺部疾病。你决定建立一个胸部疾病诊所,主治肺病及相关疾病。大学课本已经中告诉你了肺癌、肺结核和支气管炎的发生比率以及这些疾病典型的临床症状、病因等,于是你就可以根据课本里的理论知识建立自己的Bayes网。如根据如下数据信息:
美国有30%的人吸烟.
每10万人中就就有70人患有肺癌.
每10万人中就就有10人患有肺结核.
每10万人中就就有800人患有支气管炎.
10%人存在呼吸困难症状, 大部分人是哮喘、支气管炎和其他非肺结核、非肺癌性疾病引起.
根据上面的数据可以建立如下BN模型:
这样的一个BN模型对你意义不大,因为它没有用到来你诊所病人的案例数据,不能反映真实病人的情况。当诊所诊治了数千病人后,会发现课本中所描述的北美的情况与实际诊所数据显示的情况是完全不同的,实际诊所数据显示:
50%的病人吸烟.
1%患有肺结核.
5.5% 得了肺癌.
45% 患有不同程度支气管炎.
将这些新数据输入到BN模型中,才真正的获得了对你有意义的实用BN模型:
现在,看看如何在日常诊断中用该BN模型。
首先,应该注意到,上述模型反映了一个来诊所求医的新患者,为诊断之前我们没有这个患者的任何信息。而当我们向患者咨询信息时,BN网中的概率就会自动调整,这就是贝叶斯推理最完美、强大之处。贝叶斯网络最强大之处在于从每个阶段结果所获得的概率都是数学与科学的反映,换句话说,假设我们了解了患者的足够信息,根据这些信息获得统计知识,网络就会告诉我们合理的推断。
现在看看如何增加个别病人信息调节概率。一个女病人进入诊所,我们开始和她谈论。她告诉我们她呼吸困难。我们将这个信息输入到网络。我们相信病人的信息,认为其存在100%呼吸困难。
可以观察到,一旦病人有呼吸困难症状,三种疾病的概率都增大了,因为这些疾病都有呼吸困难的症状。我们的病人存在这样的症状,某种程度上我们会推断这三种疾病可能性比较大,也增加了我们患者有严重疾病认识的信念。
仔细看看推断的过程:
明显增大的是支气管炎,从 45% 到 83.4%. 为什么会有如此大的增长呢?因为支气管炎病比癌症和肺结核更常见. 只要我们相信患者有严重的肺部疾病,那最支气管炎的可能性会更大些。
病人是抽烟者的几率也会随之增大,从50% 到63.4%.
近期访问过亚洲的几率也会增大: 从1% 到1.03%, 显然是不重要的.
X光照片不正常的几率也会上涨,从11% 到16%.
知道现在我们还无法确认什么疾病困扰着我们的这个女患者,我们目前比较相信她患有支气管炎的可能性很大,但是,我们应该获得更多信息来确定我们的判断,如果我们现在就主观定了病症,她可能得的是癌症,那我们就是一个烂医生。这就需要更多信息来做最后的决定。
因此,我们按照流程依此问她一些问题,如她最近是不是去过亚洲国家,吃惊的是她回答了“是”。现在获得的信息就影响了BN模型。
患肺结核的几率显然增大,从 2%到 9%. 而患有癌症、支气管炎以及该患者是吸烟患者的几率都有所减少。为什么呢?因为此时呼吸困难的原因相对更倾向于肺结核。
继续问患者一些问题,假设患者是个吸烟者,则网络变为
此时注意到最好的假设仍然是认为患者患有支气管炎。为了确认我们要求她做一个X光透视,结果显示其正常。结果如下:
这就更加肯定我们的推断她患有支气管炎。
如果X光显示不正常的话,则结果将有很大不同:
注意最大的区别。结核病或肺癌增加的概率极大。支气管炎仍然是三个独立的疾病中最可能的一个,但它小于"结核或肺癌"这一组合的假设。所以,我们将决定进行进一步测试,血液测试,肺组织活检,等等。我们当前的贝叶斯网不包括这些测试,但它很容易扩展,只需添加额外的节点作为我们获得新的统计数据的诊断程序。我们不需要扔掉以前的任何部分。这是贝叶斯网的另一个强大的功能。他们很容易扩展(或减少,简化),以适应不断变化的需求和变化的知识。
14.4Spark MLlib算法实现
第15章SVM支持向量机算法
15.1算法思想
SVM(Support Vector Machines)是分类算法中应用广泛、效果不错的一类。由简至繁SVM可分类为三类:线性可分(linear SVM in linearly separable case)的线性SVM、线性不可分的线性SVM、非线性(nonlinear)SVM。
15.1.1线性可分
对于二类分类问题,训练T={(x1,y1),(x2,y2),⋯,(xN,yN)}T={(x1,y1),(x2,y2),⋯,(xN,yN)},其类别yi∈{0,1}yi∈{0,1},线性SVM通过学习得到分离超平面:
以及相应的分类决策函数:
有如下图所示的分离超平面,哪一个超平面的分类效果更好呢?
直观上,超平面B1B1的分类效果更好一些。将距离分离超平面最近的两个不同类别的样本点称为支持向量(support vector)的,构成了两条平行于分离超平面的长带,二者之间的距离称之为margin。显然,margin更大,则分类正确的确信度更高(与超平面的距离表示分类的确信度,距离越远则分类正确的确信度越高)。通过计算容易得到:
从上图中可观察到:margin以外的样本点对于确定分离超平面没有贡献,换句话说,SVM是有很重要的训练样本(支持向量)所确定的。至此,SVM分类问题可描述为在全部分类正确的情况下,最大化(等价于最小化);线性分类的约束最优化问题:
对每一个不等式约束引进拉格朗日乘子;构造拉格朗日函数(Lagrange function):
根据拉格朗日对偶性,原始的约束最优化问题可等价于极大极小的对偶问题:
将L(w,b,α)L(w,b,α)对w,bw,b求偏导并令其等于0,则
将上述式子代入拉格朗日函数(3)(3)中,对偶问题转为
等价于最优化问题:
线性可分是理想情形,大多数情况下,由于噪声或特异点等各种原因,训练样本是线性不可分的。因此,需要更一般化的学习算法。
15.1.2线性不可分
线性不可分意味着有样本点不满足约束条件(2)(2),为了解决这个问题,对每个样本引入一个松弛变量ξi≥0ξi≥0,这样约束条件变为:
目标函数则变为
其中,C为惩罚函数,目标函数有两层含义:
margin尽量大,
误分类的样本点计量少
C为调节二者的参数。通过构造拉格朗日函数并求解偏导(具体推导略去),可得到等价的对偶问题:
与上一节中线性可分的对偶问题相比,只是约束条件αiαi发生变化,问题求解思路与之类似。
15.1.3非线性
对于非线性问题,线性SVM不再适用了,需要非线性SVM来解决了。解决非线性分类问题的思路,通过空间变换ϕϕ(一般是低维空间映射到高维空间x→ϕ(x)x→ϕ(x))后实现线性可分,在下图所示的例子中,通过空间变换,将左图中的椭圆分离面变换成了右图中直线。
在SVM的等价对偶问题中的目标函数中有样本点的内积xi⋅xjxi⋅xj,在空间变换后则是ϕ(xi)⋅ϕ(xj)ϕ(xi)⋅ϕ(xj),由于维数增加导致内积计算成本增加,这时核函数(kernel function)便派上用场了,将映射后的高维空间内积转换成低维空间的函数:
将其代入一般化的SVM学习算法的目标函数(7)(7)中,可得非线性SVM的最优化问题:
第16章决策树算法
16.1决策树
决策树(Decision Tree)是一种基本的分类与回归方法。决策树模型呈树形结构,在分类问题中,表示基于特征对实例进行分类的过程。它可以认为是if-then规则的集合,也可以认为是定义在特征空间与类空间上的条件概率分布。相比朴素贝叶斯分类,决策树的优势在于构造过程不需要任何领域知识或参数设置,因此在实际应用中,对于探测式的知识发现,决策树更加适用。
分类决策树模型是一种描述对实例进行分类的树形结构。决策树由结点和有向边组成。结点有两种类型:内部节点和叶节点,内部节点表示一个特征或属性,叶节点表示一个类。
分类的时候,从根节点开始,对实例的某一个特征进行测试,根据测试结果,将实例分配到其子结点;此时,每一个子结点对应着该特征的一个取值。如此递归向下移动,直至达到叶结点,最后将实例分配到叶结点的类中。
举一个通俗的例子,各位立志于脱单的单身男女在找对象的时候就已经完完全全使用了决策树的思想。假设一位母亲在给女儿介绍对象时,有这么一段对话:
母亲:给你介绍个对象。
女儿:年纪多大了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
这个女生的决策过程就是典型的分类决策树。相当于对年龄、外貌、收入和是否公务员等特征将男人分为两个类别:见或者不见。假设这个女生的决策逻辑如下:
上图完整表达了这个女孩决定是否见一个约会对象的策略,其中绿色结点(内部结点)表示判断条件,橙色结点(叶结点)表示决策结果,箭头表示在一个判断条件
在不同情况下的决策路径,图中红色箭头表示了上面例子中女孩的决策过程。 这幅图基本可以算是一棵决策树,说它“基本可以算”是因为图中的判定条件没有量化,如收入高中低等等,还不能算是严格意义上的决策树,如果将所有条件量化,则就变成真正的决策树了。
16.2决策树模型的两种解释
分类决策树模型是一种描述对实例进行分类的树形结构。决策树由结点和有向边组成。结点有两种类型:内部结点和叶节点。内部结点表示一个特征或属性,叶节点表示一个类。
16.2.1决策树与if-then规则
可以将决策树看成一个if-then规则的集合。即由决策树的根结点到叶节点的每一条路径构建一条规则;路径上内部结点的特征对应着规则的条件,而叶结点的类对应着规则的结论。
决策树的路径或其对应的if-then规则集合的重要性质:互斥且完备(每一个实例都被一条路径或一条规则所覆盖,且只被一条路径或一条规则所覆盖,这里的覆盖是指实例的特征与路径上的特征一致或实例满足规则的条件)
16.2.2决策树与条件概率分布
决策树还表示给定特征条件下类的条件概率分布,它定义在特征空间的一个划分。将特征空间划分为互不相交的单元,并在每个单元定义一个类的概率分布就构成了一个条件概率分布。决策树的每一条路径对应于划分中的一个单元。
假设X为表示特征的随机变量,Y为表示类的随机变量,那么这个条件概率分布可以表示为P(X|Y),各叶结点上的条件概率往往偏向于某一个类,即属于某一类的概率越大。决策树分类时将该结点的实例强行分到条件概率大的那一类去。
16.3特征选择
知道了什么是决策树,那么如果构造决策树呢?为什么拿年龄作为第一个分类?那么就涉及到特征选择的问题。特征选择中用的最多的方法是通过熵和基尼进行对比。
特征选择的标准是找出局部最优的特征,判断一个特征对于当前数据集的分类效果,也就是按照这个特征进行分类后,不同分类的数据是否能够被尽量分开。
16.3.1熵
16.3.1.1 信息量
信息量由这个事件发生的概率所决定。经常发生的事件是没有什么信息量的,只有小概率的事件才有信息量,所以信息量的定义为:
例如:英语有26个字母,假如每个字母在文章中出现的次数是平均数,那每个字母的信息量是:
16.3.1.2 熵
熵,就是信息量的期望,熵表示随机变量不确定性的度量。熵越大,随机变量的不确定性就越大。信息熵的公式为:
条件熵表示在已知随机变量Y的条件下随机变量X的不确定性,公式为:
16.3.1.3 条件熵
H(Y|X) 表示在已知随机变量X的条件下随机变量Y的不确定性定义为X给定条件下Y的条件概率分布的熵对X的数学期望。
经验熵和经验条件熵:当熵和条件熵中的概率由数据估计(特别是极大似然估计)得到时,所对应的熵与条件熵分别称为经验熵和条件经验熵。
16.3.1.4 信息增益
信息增益表示得知特征X的信息而使得类Y的信息的不确定性减少的程度。特征A对训练数据集D的信息增益g(D,A),定义为集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差,即
g(D,A)=H(D)−H(D|A)
这个差又称为互信息。信息增益大的特征具有更强的分类能力。
根据信息增益准则的特征选择方法是:对训练数据集(或子集)计算其每个特征的信息增益,选择信息增益最大的特征。
计算信息增益的算法如下:
输入:训练数据集D和特征A;
输出:特征A对训练数据集D的信息增益g(D,A).
(1)计算数据集D的经验熵H(D)
(2)计算特征A对数据集D的经验条件熵H(D|A)
16.3.1.5 信息增益比
单纯的信息增益只是个相对值,因为这依赖于H(D)的大小,所以信息增益比更能客观地反映信息增益。特征A对训练数据集D的信息增益比gR(D,A)定义为其信息增益g(D,A)与训练数据集D关于特征A的值的熵HA(D)之比,即
其中,,n是特征A取值的个数。
16.3.2基尼系数
16.4决策树生成
16.4.1ID3算法
ID3算法由Ross Quinlan发明,建立在“奥卡姆剃刀”的基础上:越是小型的决策树越优于大的决策树(be simple简单理论)。ID3算法中根据信息增益评估和选择特征,每次选择信息增益最大的特征作为判断模块建立子结点。ID3算法可用于划分标称型数据集,没有剪枝的过程,为了去除过度数据匹配的问题,可通过裁剪合并相邻的无法产生大量信息增益的叶子节点(例如设置信息增益阀值)。使用信息增益的话其实是有一个缺点,那就是它偏向于具有大量值的属性。就是说在训练集中,某个属性所取的不同值的个数越多,那么越有可能拿它来作为分裂属性,而这样做有时候是没有意义的,另外ID3不能处理连续分布的数据特征,于是就有了C4.5算法。CART算法也支持连续分布的数据特征。
算法步骤如下:
16.4.2C4.5算法
C4.5算法用信息增益比来选择属性,继承了ID3算法的优点。并在以下几方面对ID3算法进行了改进:
克服了用信息增益选择属性时偏向选择取值多的属性的不足;
在树构造过程中进行剪枝;
能够完成对连续属性的离散化处理;
能够对不完整数据进行处理。
C4.5算法产生的分类规则易于理解、准确率较高;但效率低,因树构造过程中,需要对数据集进行多次的顺序扫描和排序。也是因为必须多次数据集扫描,C4.5只适合于能够驻留于内存的数据集。在实现过程中,C4.5算法在结构与递归上与ID3完全相同,区别只在于选取决决策特征时的决策依据不同,二者都有贪心性质:即通过局部最优构造全局最优。以下是算法步骤:
16.4.3CART
分类树与回归树(classification and regression tree,CART)模型(Breiman)由特征选择、树生成及剪枝组成,既可用于分类也可用于回归。CART是在给定输入随机变量X条件下输出变量Y的条件概率分布的学习方法。它假定决策树是二叉树,内部取值为“是”(左分支)和“否”(右分支)。
它的基本步骤为
o1)决策树生成:基于训练数据集生成决策树,生成的决策树要尽量大。
o2)决策树剪枝:用验证数据集对已生成的树进行剪枝并选择最优子树,这是用损失函数最小作为剪枝的标准。
16.4.3.1 分类树
对分类树用基尼系数(Gini index)最小化准则,进行特征选择,生成二叉树。
具体算法步骤如下:
o1)设结点的训练数据集为D,计算现有特征对该数据集的基尼指数。此时,对每一个特征A,对其可能取的每个值aa,根据样本点对A=aA=a的测试为”是”或者“否”将D分割为D1D1和D2D2两部分,计算其基尼系数。
o2)在所有可能的特征A以及他们所有可能的切分点aa中,选择基尼系数最小的特征及其对应的切分点作为最优特征与最优切分点。依最优特征与最优切分点,从现结点生成两个子结点,将训练数据集依特征分配到两个子结点中去。
o3)对两个子结点递归地调用上述两个步骤,直至满足停止条件。
o4)生成CART决策树
16.4.3.2 回归树
首先看一个简单的回归树生成实例:
接下来具体说说回归树是如何进行特征选择生成二叉回归树的。
假设X与Y分别为输入和输出变量,并且Y是连续变量,给定训练数据集
我们利用最小二乘回归树生成算法来生成回归树f(x),即在训练数据集所在的输入空间中,递归地将每个区域分为两个子区域并决定每个子区域上的输出值,构建二叉决策树,步骤如下:
1)选择最优切分变量j与切分点s,求解
遍历变量j,对固定的切分变量j扫描切分点s,选择使上式达到最小值得对j,s
2)用选定的对(j,s)划分区域并决定相应的输出值:
3)继续对两个子区域调用步骤(1),(2),直至满足停止条件。
4)将输入空间划分为M个区域R1,R2,···,RM,在每个单元Rm上有一个固定的输出值cm,生成决策树:
16.5决策树剪枝
决策树生成算法对于训练集是很准确的,也就是生成的树枝很详细,但这样会过拟合,需要通过剪枝操作来提高泛化能力,思路很简单,就是在决策树对训练集数据的预测误差和树复杂度之间找一个平衡。
预测误差就是所有叶子节点的经验熵的和,其中表示该叶节点的样本点个数,而表示该叶子节点的经验熵:
树的复杂度由叶子节点的个数来表示:T。
所以,剪枝的标准就是极小化损失函数:
其中,是调节参数。其越大表示选择越简单的树,而越小表示选择越复杂的树,对训练集拟合度高的树。
树的剪枝算法就是从叶子节点往上回溯,比较剪掉该叶子节点前后的损失函数的值。如果剪掉该叶子节点后,损失函数更小就剪掉,具体流程如下:
输入:生成算法产生的整个树T,参数。
输出:修剪后的子树。
1)计算每个节点的经验熵。
2)递归地从树的节点向上回溯。
设一组叶子节点回溯到其父节点之前与之后的整体树分别为和,其对应的损失函数值分别是和。如果小于等于,则进行剪枝,即将父节点变为新的叶子节点。
3) 返回2),直到不能继续为止,最终得到损失函数最小的子树。
16.6CART剪枝
16.7Spark MLlib案例实现
第17章K近邻算法
17.1算法概述
K近邻算法简单、直观。首先给出一张图,根据这张图来理解最近邻分类器。
根据上图所示,有两类不同的样本数据,分别用蓝色的小正方形和红色的小三角形表示,而图正中间的那个绿色的圆所标示的数据则是待分类的数据。也就是说,现在,我们不知道中间那个绿色的数据是从属于哪一类(蓝色小正方形或者红色小三角形),下面,我们就要解决这个问题:给这个绿色的圆分类。
我们常说,物以类聚,人以群分,判别一个人是一个什么样的人,常常可以从他身边的朋友入手,所谓观其友,而识其人。我们不是要判别上图中那个绿色的圆是属于那一类数据么,好说,从他的邻居下手。但一次性看多少个邻居呢?从上图中,你还可以看到:
o如果K=3,绿色圆点最近的3个邻居是2个红色小三角形和1个蓝色小正方形,少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于红色的三角形一类。
o如果K=5,绿色圆点的最近5个邻居是2个红色三角形和3个蓝色的正方形,还是少数从属于多数,基于统计的方法,判定绿色这个待分类点属于蓝色的正方形一类。
于是,我们看到,KNN算法为给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,就把该输入实例分为这个类。
K近邻法算法步骤如下:
输入:训练数据集
,其中,是实例的特征向量,是实例的类别;新实例的特征向量x。
输出:新实例x所属的类别y。
o1)根据给定的距离度量,在训练集T中找出与x最邻近的k个点,涵盖这k个点的x领域记作
o2)在中根据分类决策规则(如多数表决)决定x的类别y:
其中I为指示函数,即当时为1,否则为0。
17.2K近邻模型
17.2.1模型
k近邻法中,当训练集、距离度量、K值以及分类决策规则确定后,对于任何一个新的输入实例,它所属的类唯一地确定。这相当于根据上述要素将特征空间划分为一些子空间,确定子空间里的每个点所属的类。
17.2.2距离度量
特征空间中两个实例点的距离可以反映出两个实力点之间的相似性程度。K近邻模型的特征空间一般是N维实数向量空间,使用的距离可以是欧式距离,也可以是其他距离。
1)欧氏距离:最常见的两点之间或多点之间的距离表示法,又称之为欧几里得度量,它定义于欧几里得空间中
2)曼哈顿距离:我们可以定义曼哈顿距离的正式意义为L1距离或城市区块距离,也就是在欧几里得空间的固定直角坐标系上两点所形成的线段对轴产生的投射的距离总和。
通俗来讲,想想你在曼哈顿要从一个十字路口开车到另一个十字路口,驾驶距离是两点间的直线距离吗?显然不是,除非你能穿越大楼。而实际驾驶距离就是这个“曼哈顿距离”,此即曼哈顿距离名称的来源,同时,曼哈顿距离也称为城市街区距离。
3)切比雪夫距离:
4)闵可夫斯基距离:它不是一种距离,而是一组距离的定义。
当p=1时,即曼哈顿距离
当p=2时,即欧式距离
当p→∞,即切比雪夫距离
5)标准化欧氏距离:对样本集先进行标准化经过简单的推导就可以得到来标准化欧氏距离。
6)夹角余弦:几何中夹角余弦可用来衡量两个向量方向的相似度,机器学习中借用这一概念来衡量向量之间的相似度。
17.2.3K值得选择
K值得选择会对K近邻法的结果产生重大影响。
如果选择较小的K值,就相当于用较小的领域中的训练实例进行预测,“学习”近似误差会减小,只有与输入实例较近或相似的训练实例才会对预测结果起作用,与此同时带来的问题是“学习”的估计误差会增大,换句话说,K值得减小就意味着整体模型变得复杂,容易发生过拟合(容易受到训练数据的噪声而产生的过拟合的影响)。
如果选择较大的K值,就相当于用较大领域中的训练实例进行预测,其优点是可以减小学习的估计误差,但缺点是学习的近似误差会增大。这时候,与输入实例较远的训练实例也会对预测器作用,使预测发生错误,且K值得增大就意味着整体的模型变得简单。
如果K=N。那么无论输入实例是什么,都将简单地预测它属于在训练实例中最多的类。这时,模型过于简单,完全忽略训练实例中的大量有用信息,是不可取的(最近邻列表中可能包含远离其近邻的数据点),如下图所示。
17.2.4分类决策规则
K近邻法中的分类决策规则往往是多数表决,即由输入实例的K个邻近的训练实例中的多数类决定输入实例的类。
在实际应用中,K值一般取一个比较小的数值。通常采用交叉验证法来选取最优的K值(经验规则:K一般低于训练样本数的平方根)。
17.3K紧邻的优缺点
17.3.1优点
简单、易于理解、易于实现、无需估计参数、无需训练。
适合对稀有事件进行分类(如大概流式率很低时,比如0.5%,构造流失预测模型);
特别适合多酚类问题,如根据基因特征来判断其功能分类,KNN比SVM的表现要好。
17.3.2缺点
懒惰算法,对测试样本分类时的计算量大,内存开销大,评分慢。
可解释性较差,无法给出决策树那样的规则。
当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。
KNN是一种懒惰算法,平时不好好学习,考试(对测试样本分类)时才临阵磨枪(临时去找K个近邻),懒惰的后果,构造模型很简单,但在测试样本分类地系统开销大,因为要扫描全部训练样本并计算距离。已经有一些方法提高计算的效率,例如压缩训练样本量。
决策树和基于规则的分类器都是积极学习eager learner的例子,因为一旦训练数据可用,它们就开始学习从输入属性到类标号的映射模型。一个相反的策略是推迟对训练数据的建模,直到需要分类测试样例时再进行。采用这种策略的技术被称为消极学习法lazy learner。最近邻分类器就是这样的一种方法。
第18章聚类算法概述
18.1算法概述
“物以类聚,人以群分”
聚类算法属于无监督学习,类别提前是未知的。解决的问题是如何在海量的数据中将未知的数据分布特性收敛到具体的类别上。和分类不一样,分类是提前直到标签,属于有监督学习。
18.2应用场景
18.2.1基于用户位置信息的商业选址
随着信息技术的快速发展,移动设备和移动互联网已经普及到千家万户。在用户使用移动网络时,会自然的留下用户的位置信息。随着近年来GIS地理信息技术的不断完善普及,结合用户位置和GIS地理信息将带来创新应用。希望通过大量移动设备用户的位置信息,为某连锁餐饮机构提供新店选址。
18.2.2搜索引擎查询聚类以进行流量推荐
在搜索引擎中, 很多网民的查询意图的比较类似的,对这些查询进行聚类,一方面可以使用类内部的词进行关键词推荐;另一方面, 如果聚类过程实现自动化,则也有助于新话题的发现;同时还有助于减少存储空间等。
18.2.3保险投保者分组
通过一个高的平均消费来鉴定汽车保险单持有者的分组,同时根据住宅类型,价值,地理位置来鉴定一个城市的房产分组。
18.2.4网站关键词来源聚类整和
以领域特征明显的词和短语作为聚类对象,在分类系统的大规模层级分类语料库中,利用文本分类的特征提取算法进行词语的领域聚类,通过控制词语频率的影响,分别获取领域通用词和领域专类词。
第19章KMEANS聚类算法
19.1算法思想
K-means的目标是要将数据点划分为k个cluster,找到这每个cluster的中心未知,使最小化函数
其中就是第i个cluster的中心。上式就是要求每个数据点要与它们所属cluster的中心尽量接近。
基本思想使初始随机给定K个簇中心,按照最邻近原则把待分类样本点分到各个簇。然后按平均法重新计算各个簇的质心。一直迭代,直到簇心得移动距离小于某个给定的值。
19.2KMEANS算法演示
设定K取2,即设定有两个类别。
1.未聚类的初始点集;
2.随机选取两个点作为聚类中心;
3.计算每个点到聚类中心的距离,并聚类到离该点最近的聚类中去;
4.计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心;
5.重复(c),计算每个点到聚类中心的距离,并聚类到离该点最近的聚类中去;
6.重复(d),计算每个聚类中的所有点的坐标平均值,并将这个平均值作为新的聚类中心。
KMEANS结束条件:直到类中心不再进行大范围移动或者聚类迭代次数达到要求为止。
19.3最邻近算法
19.3.1欧氏距离
欧几里德距离,这个距离就是平时我们理解的距离,如果是两个平面上的点,也就是(X1,Y1),和(X2,Y2),那这俩点距离就是√( (x1-x2)2+(y1-y2)2) ,如果是三维空间中呢?√( (x1-x2)2+(y1-y2)2+(z1-z2)^2;推广到高维空间公式就以此类推。可以看出,欧几里德距离真的是数学加减乘除算出来的距离,因此这就是只能用于连续型变量的原因。
19.3.2余弦相似度
余弦相似度,余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。相比距离度量,余弦相似度更加注重两个向量在方向上的差异,而非距离或长度上。下图表示余弦相似度的余弦是哪个角的余弦,A,B是三维空间中的两个向量,这两个点与三维空间原点连线形成的角,如果角度越小,说明这两个向量在方向上越接近,在聚类时就归成一类:
从上图可以看出,欧氏距离衡量的是空间各点的绝对距离,跟各个点所在的位置坐标直接相关;而余弦距离衡量的是空间向量的夹角,更加体现在方向上的差异,而不是位置。如果保持A点位置不变,B点朝原方向远离坐标轴原点,那么这个时候余弦距离是保持不变的(因为夹角没有发生变化),而A、B两点的距离显然在发生改变,这就是欧氏距离和余弦距离之间的不同之处。
欧氏距离和余弦距离各自有不同的计算方式和衡量特征,因此它们适用于不同的数据分析模型:欧氏距离能够体现个体数值特征的绝对差异,所以更多的用于需要从维度的数值大小中体现差异的分析,如使用用户行为指标分析用户价值的相似度或差异。
余弦距离更多的是从方向上区分差异,而对绝对的数值不敏感,更多的用于使用用户对内容评分来区分兴趣的相似度和差异,同时修正了用户间可能存在的度量标准不统一的问题(因为余弦距离对绝对数值不敏感)。
19.4K的取值
这个真的没有确定的做法,分几类主要取决于个人的经验与感觉,通常的做法是多尝试几个K值,看分成几类的结果更好解释,更符合分析目的等。或者可以把各种K值算出的SSE做比较,取最小的SSE的K值。
如果有业务专家可以进行分析,或者可以使用层次聚类先进行比较粗粒度的聚类。
19.5K的初始位置
k-means++算法选择初始位置的基本思想就是:初始的聚类中心之间的相互距离要尽可能的远。
1.从输入的数据点集合中随机选择一个点作为第一个聚类中心
2.对于数据集中的每一个点x,计算它与最近聚类中心(指已选择的聚类中心)的距离D(x)
3.选择一个新的数据点作为新的聚类中心,选择的原则是:D(x)较大的点,被选取作为聚类中心的概率较大
4.重复2和3直到k个聚类中心被选出来
5.利用这k个初始的聚类中心来运行标准的k-means算法
从上面的算法描述上可以看到,算法的关键是第3步,如何将D(x)反映到点被选择的概率上,一种算法如下:
1.先从我们的数据库随机挑个随机点当“种子点”
2.对于每个点,我们都计算其和最近的一个“种子点”的距离D(x)并保存在一个数组里,然后把这些距离加起来得到Sum(D(x))。
3.然后,再取一个随机值,用权重的方式来取计算下一个“种子点”。这个算法的实现是,先取一个能落在Sum(D(x))中的随机值Random,然后用Random -= D(x),直到其<=0,此时的点就是下一个“种子点”。
4.重复2和3直到k个聚类中心被选出来
5.利用这k个初始的聚类中心来运行标准的k-means算法
可以看到算法的第三步选取新中心的方法,这样就能保证距离D(x)较大的点,会被选出来作为聚类中心了。至于为什么原因比较简单,如下图所示:
假设A、B、C、D的D(x)如上图所示,当算法取值Sum(D(x))*random时,该值会以较大的概率落入D(x)较大的区间内,所以对应的点会以较大的概率被选中作为新的聚类中心。
19.6Spark MLlib案例实现
第20章EM算法
20.1定义
20.2Jensen不等式
20.3EM思想
20.3.1极大似然估计
20.3.2EM算法思想
20.4EM推导
第21章FPGrowth关联规则算法
21.1算法思想
FPGrowth算法通过构造一个FPTree树结构来压缩数据记录,使得挖掘频繁项集只需要扫描两次数据记录,而且该算法不需要生成候选集合,所以效率会比较高。如何从购物篮里面发现 尿布+啤酒 的最佳组合。 我们以以下数据集为例:
TID Items
T1 { 面包 , 牛奶 }
T2 { 面包 , 尿布 , 啤酒 , 鸡蛋 }
T3 { 牛奶 , 尿布 , 啤酒 , 可乐 }
T4 { 面包 , 牛奶 , 尿布 , 啤酒 }
T5 { 面包 , 牛奶 , 尿布 , 可乐 }
注意:牛奶、面包叫做项,{ 牛奶、面包 }叫做项集。项集出现的次数叫做支持度。T* 表示用户每次的购物清单。
21.1.1构造FPTree
FPTree是一种树结构,需要将表中的数据以及关系进行保存,我们先来看构建过程:假设我们的最小支持度是3。
Step 1:扫描鼓舞数据记录,生成一级频繁项集,并按出现次数由多到少排序,如下所示:
Item Count
牛奶 4
面包 4
尿布 4
啤酒 3
可乐 2
鸡蛋 1
可以看到,鸡蛋和可乐在上表中要删除,因为可乐只出现2次,鸡蛋只出现1次,小于最小支持度,因此不是频繁项集,非频繁项集的超集一定不是频繁项集,所以可乐和鸡蛋不需要再考虑。
Step 2:再次扫描数据记录,对每条记录中出现在Step 1产生的表中的项,按表中的顺序排序。初始时,新建一个根结点,标记为null;
1)第一条记录:{面包,牛奶}需要根据Step1中结果转换成:{牛奶,面包},新建一个结点,name为{牛奶},将其插入到根节点下,并设置count为1,然后新建一个{面包}结点,插入到{牛奶}结点下面,插入后如下所示:
2)第二条记录:{面包,尿布,啤酒,鸡蛋},过滤并排序后为:{面包,尿布,啤酒},发现根结点没有包含{面包}的儿子(有一个{面包}孙子但不是儿子),因此新建一个{面包}结点,插在根结点下面,这样根结点就有了两个孩子,随后新建{尿布}结点插在{面包}结点下面,新建{啤酒}结点插在{尿布}下面,插入后如下所示:
3)第三条记录:{牛奶,尿布,啤酒,可乐},过滤并排序后为:{牛奶,尿布,啤酒},这时候发现根结点有儿子{牛奶},因此不需要新建结点,只需将原来的{牛奶}结点的count加1即可,往下发现{牛奶}结点有一个儿子{尿布},于是新建{尿布}结点,并插入到{牛奶}结点下面,随后新建{啤酒}结点插入到{尿布}结点后面。插入后如下图所示:
4)第四条记录:{面包,牛奶,尿布,啤酒},过滤并排序后为:{牛奶,面包,尿布,啤酒},这时候发现根结点有儿子{牛奶},因此不需要新建结点,只需将原来的{牛奶}结点的count加1即可,往下发现{牛奶}结点有一个儿子{面包},于是也不需要新建{面包}结点,只需将原来{面包}结点的count加1,由于这个{面包}结点没有儿子,此时需新建{尿布}结点,插在{面包}结点下面,随后新建{啤酒}结点,插在{尿布}结点下面,插入后如下图所示:
5)第五条记录:{面包,牛奶,尿布,可乐},过滤并排序后为:{牛奶,面包,尿布},检查发现根结点有{牛奶}儿子,{牛奶}结点有{面包}儿子,{面包}结点有{尿布}儿子,本次插入不需要新建结点只需更新count即可,示意图如下:
按照上面的步骤,我们已经基本构造了一棵FPTree(Frequent Pattern Tree),树中每个路径代表一个项集,因为许多项集有公共项,而且出现次数越多的项越可能是公公项,因此按出现次数由多到少的顺序可以节省空间,实现压缩存储,另外我们需要一个表头和对每一个name相同的结点做一个线索,方便后面使用,线索的构造也是在建树过程形成的(下图虚线)。最后的FPTree如下:
至此,整个FpTree就构造好了。
21.1.2利用FPTree挖掘频繁项集
FPTree建好后,就可以进行频繁项集的挖掘,挖掘算法称为FPGrowth(Frequent Pattern Growth)算法,挖掘从表头header的最后一个项开始。
1)此处即从{啤酒}开始,根据{啤酒}的线索链找到所有{啤酒}结点,然后找出每个{啤酒}结点的分支:{牛奶,面包,尿布,啤酒:1},{牛奶,尿布,啤酒:1},{面包,尿布,啤酒:1},其中的“1”表示出现1次,注意,虽然{牛奶}出现4次,但{牛奶,面包,尿布,啤酒}只同时出现1次,因此分支的count是由后缀结点{啤酒}的count决定的,除去{啤酒},我们得到对应的前缀路径{牛奶,面包,尿布:1},{牛奶,尿布:1},{面包,尿布:1},根据前缀路径我们可以生成一颗条件FPTree,构造方式跟之前一样,此处的数据记录变为:
TID Items
T1 {牛奶,面包,尿布 : 1}
T2 {牛奶,尿布: 1}
T3 {面包,尿布: 1}
绝对支持度依然是3,我们发现此时,牛奶的支持度为2、面包的支持度为2、尿布的支持度为3,由于我们的支持度为3,所以删除牛奶和面包。按照相同的算法构造得到的FPTree为:
构造好条件树后,对条件树进行递归挖掘,当条件树只有一条路径时,路径的所有组合即为条件频繁集,假设{啤酒}的条件频繁集为{S1,S2},则{啤酒}的频繁集为{S1+{啤酒},S2+{啤酒},S1+S2+{啤酒}},即{啤酒}的频繁集一定有相同的后缀{啤酒},此处的条件频繁集为:{{},{尿布}},于是{啤酒}的频繁集为{{啤酒}{尿布,啤酒}}。
2)接下来找header表头的倒数第二个项{尿布}的频繁集,同上可以得到{尿布}的前缀路径为:{面包:1},{牛奶:1},{牛奶,面包:2},条件FPTree的数据集为:
TID Items
T1 {面包 :1 }
T2 {牛奶 :1}
T3 {牛奶,面包 :2}
构造的条件FpTree为:
这颗条件树路径上的所有组合即为条件频繁集:{{},{牛奶},{面包},{牛奶,面包}},加上{尿布}后,又得到一组频繁项集{{尿布},{牛奶,尿布},{面包,尿布},{牛奶,面包,尿布}},这组频繁项集一定包含一个相同的后缀:{尿布},并且不包含{啤酒},因此这一组频繁项集与上一组不会重复。
重复以上步骤,对header表头的每个项进行挖掘,即可得到整个频繁项集,频繁项集即不重复也不遗漏。
21.2Spark MLlib案例实现
第22章Apriori关联规则算法
22.1关联分析
22.1.1引言
22.1.2简单关联规则初探
22.1.3简单关联规则的有效性
22.1.4简单关联规则的实用性
22.2Apriori算法
22.2.1简介
22.2.2频繁项集的相关定义
22.2.3寻找频繁项集
22.2.4在最大频繁项集的基础上产生简单关联规则
第23章协同过滤推荐算法
23.1算法思想
比如你想看一个电影,但是不知道具体看哪一部,你会怎么做?有两种办法,一种是问问周围兴趣相似的朋友,看看他们最近有什么好的电影推荐。另外一种是看看电影的相似程度,比如都喜欢看僵尸片,那就会找电影名带有僵尸、丧尸之类的电影。
协同过滤算法就是基于上面的思想,主要包含基于用户的协同过滤推荐算法以及基于物品的协同过滤推荐算法。
实现协同过滤,一般需要几个步骤:
1、收集用户偏好。
2、找到相似的用户或者物品。
3、计算推荐。
23.2推荐数据准备
要进行推荐我们需要的数据如下: 用户ID、物品ID、偏好值
偏好值就是用户对物品的喜爱程度,推荐系统所做的事就是根据这些数据为用户推荐他还没有见过的物品,并且猜测这个物品用户喜欢的概率比较大。
用户ID和物品ID一般通过系统的业务数据库就可以获得,偏好值的采集一般会有很多办法,比如评分、投票、转发、保存书签、页面停留时间等等,然后系统根据用户的这些行为流水,采取减噪、归一化、加权等方法综合给出偏好值。一般不同的业务系统给出偏好值的计算方法不一样。
23.3相似性度量
基于用户的推荐和基于物品的推荐都需要找相似,即需要找相似用户以及相似物品。比如一个男生和一个女生是朋友,不能讲该女生穿的衣服推荐给男生。要找相似。那么衡量的指标有哪些?比如皮尔逊相关系数、欧式距离、同现相似度、Cosine相似度、Tanimoto系数等。
23.3.1皮尔逊相关系数
皮尔逊相关系数是介于1到-1之间的数,他衡量两个一一对应的序列之间的线性相关性。也就是两个序列一起增大或者一起减小的可能性。两个序列正相关值就趋近1,否者趋近于0。
数学含义:两个序列协方差与二者方差乘积的比值
如果比较两个人的相似度,那么他们所有共同评价过的物品可以看做两个人的特征序列,这两个特征序列的相似度就可以用皮尔逊相关系数去衡量。物品的相似度比较也是如此。
皮尔逊对于稀疏矩阵表现不好,可以通过引入权重进行优化。
23.3.2欧式距离
这个已经在KMEANS中讲过,同理可以将两个人所有共同评价过的物品看做这个人的特征,将这些特征看做是空间中的点,计算两点之间的距离。
23.3.3同现相似度
物品i和物品j的同相似度公式定义:
其中,分母是喜欢物品i的用户数,而分子则是同时喜欢物品i和物品j的用户数。因此,上述公式可用理解为喜欢物品i的用户有多少比例的用户也喜欢j (和关联规则类似)
但上述的公式存在一个问题,如果物品j是热门物品,有很多人都喜欢,则会导致Wij很大,接近于1。因此会造成任何物品都和热门物品交有很大的相似度。为此我们用如下公式进行修正:
这个格式惩罚了物品j的权重,因此减轻了热门物品和很多物品相似的可能性。(也归一化了[i,j]和[j,i])
23.4邻域大小
有了相似度的比较,那么比较多少个用户或者物品为好呢?一般会有基于固定大小的邻域以及基于阈值的领域。具体的数值一般是通过对模型的评比分数进行调整优化。
23.5基于用户的CF
模型核心算法伪代码表示:
基于该核心算法,完成用户商品矩阵:
预测用户对于未评分的物品的分值,然后按照降序排序,进行推荐。
23.6基于物品的CF
先计算出物品-物品的相似矩阵:
基于上面的结果:
给用户推送预测偏好值n个最高的物品。
23.7Spark MLlib算法实现
第24章ALS交替最小二乘算法
24.1算法思想
24.1.1矩阵分解模型
在协同过滤推荐算法中,最主要的是产生用户对物品的打分,用户对物品的打分行为可以表示成一个评分矩阵A(m*n),表示m个用户对n各物品的打分情况。如下图所示:
其中,A(i,j)表示用户user i对物品item j的打分。但是,用户不会对所有物品打分,图中?表示用户没有打分的情况,所以这个矩阵A很多元素都是空的,我们称其为“缺失值(missing value)”,是一个稀疏矩阵。在推荐系统中,我们希望得到用户对所有物品的打分情况,如果用户没有对一个物品打分,那么就需要预测用户是否会对该物品打分,以及会打多少分。这就是所谓的“矩阵补全(填空)”。
我们从另外一个层面考虑用户对物品的喜爱程序,而不是通过用户的推荐。用户之所以喜欢一个物品,绝大对数是因为这个物品的某些属性和这个用户的属性是一致或者是接近的,比如一个人总是具有爱国情怀或者侠义情怀,那么根据这些推断一定喜欢比如《射雕英雄传》、抗战剧等电视剧,因为这些电视剧所表达的正是侠义和爱国。可以设想用户拥有某些隐含的特征、物品也具有某种隐含的特征,如果这些特征都相似,那么很大程度上用户会喜欢这个物品。
根据上面的假设,我们可以把评分矩阵表示成两个低纬度的矩阵相乘,如下:
我们希望学习到一个P代表user的特征,Q代表item的特征。特征的每一个维度代表一个隐性因子,比如对电影来说,这些隐性因子可能是导演,演员等。当然,这些隐性因子是机器学习到的,具体是什么含义我们不确定。
ALS 的核心就是下面这个假设:打分矩阵A是近似低秩的。换句话说,一个 的打分矩阵A 可以用两个小矩阵和的乘积来近似:。这样我们就把整个系统的自由度从一下降到了。 一个人的喜好映射到了一个低维向量,一个电影的特征变成了纬度相同的向量,那么这个人和这个电影的相似度就可以表述成这两个向量之间的内积。
我们把打分理解成相似度,那么“打分矩阵A(mn)”就可以由“用户喜好特征矩阵U(mk)”和“产品特征矩阵V(n*k)”的乘积来近似了。这种方法被称为概率矩阵分解算法(probabilistic matrix factorization,PMF)。ALS算法是PMF在数值计算方面的应用。
24.1.2交替最小二乘法(ALS)
为了使低秩矩阵X和Y尽可能地逼近R,需要最小化下面的平方误差损失函数:
考虑到矩阵的稳定性问题,使用吉洪诺夫正则化Tikhonov regularization,则上式变为:
所以整个矩阵分解模型的损失函数为:
有了损失函数之后,下面就开始谈优化方法了,通常的优化方法分为两种:交叉最小二乘法(alternative least squares)和随机梯度下降法(stochastic gradient descent)。本次使用交叉最小二乘法(ALS)来最优化损失函数。算法的思想就是:我们先随机生成然后固定它求解,再固定求解,这样交替进行下去,直到取得最优解min©。因为每步迭代都会降低误差,并且误差是有下界的,所以ALS 一定会收敛。但由于问题是非凸的,ALS 并不保证会收敛到全局最优解。但在实际应用中,ALS 对初始点不是很敏感,是不是全局最优解造成的影响并不大。
算法的执行步骤:
1、先随机生成一个。一般可以取0值或者全局均值。
2、固定(即:认为是已知的常量),来求解。
此时,损失函数为:
由于C中只有Vj一个未知变量,因此C的最优化问题转化为最小二乘问题,用最小二乘法求解Vj的最优解:
固定j(j=1,2,…,n),则:C的导数
令,得到:
即:
令,,则:
按照上式依次计算v1,v2,…,vn,从而得到。
3、固定(即:认为是已知的量),来求解。
此时,损失函数为:
同理,用步骤2中类似的方法,可以计算ui的值:
令,得到:
即:
令
,,则:
依照上式依次计算u1,u2,…,um,从而得到。
4、循环执行步骤2、3,直到损失函数C的值收敛(或者设置一个迭代次数N,迭代执行步骤2、3 N次后停止)。这样,就得到了C最优解对应的矩阵U、V。
24.2Spark MLlib算法实现
第25章SVD推荐系统算法
25.1传统的SVD算法
25.2Funk-SVD算法
25.2.1基本思想
25.2.2Funk-SVD
25.3Bias-SVD
25.4SVD++
25.5矩阵分解的优缺点
第26章随机森林算法
26.1算法原理
顾名思义,是用随机的方式建立一个森林,森林里面有很多的决策树组成,随机森林的每一棵决策树之间是没有关联的。在得到森林之后,当有一个新的输入样本进入的时候,就让森林中的每一棵决策树分别进行一下判断,看看这个样本应该属于哪一类(对于分类算法),然后看看哪一类被选择最多,就预测这个样本为那一类。
我们可以这样比喻随机森林算法:每一棵决策树就是一个精通于某一个窄领域的专家(因为我们从M个特征中选择m个让每一棵决策树进行学习),这样在随机森林中就有了很多个精通不同领域的专家,对一个新的问题(新的输入数据),可以用不同的角度去看待它,最终由各个专家,投票得到结果。
下图为随机森林算法的示意图:
随机森林算法有很多优点:
在数据集上表现良好,两个随机性的引入,使得随机森林不容易陷入过拟合
在当前的很多数据集上,相对其他算法有着很大的优势,两个随机性的引入,使得随机森林具有很好的抗噪声能力
它能够处理很高维度(feature很多)的数据,并且不用做特征选择,对数据集的适应能力强:既能处理离散型数据,也能处理连续型数据,数据集无需规范化
可生成一个矩阵,用于度量样本之间的相似性:表示样本i和j出现在随机森林中同一个叶子结点的次数,N随机森林中树的颗数
在创建随机森林的时候,对generlization error使用的是无偏估计
训练速度快,可以得到变量重要性排序(两种:基于OOB误分率的增加量和基于分裂时的GINI下降量
在训练过程中,能够检测到feature间的互相影响
容易做成并行化方法
实现比较简单
26.2随机森林的生成
26.2.1生成步骤
步骤如下:
1)如果训练集大小为NN,对于每棵树而言,随机且有放回地从训练集中抽取NN个训练样本(bootstrap抽样方法),作为该树的训练集;每棵树的训练集都是不同的,但里面包含重复的训练样本
2)如果每个样本的特征维度为MM,指定一个常数mm,且mm
26.2.2影响分类效果的参数
随机森林的分类效果(即错误率)与以下两个因素有关:
1)森林中任意两棵树的相关性:相关性越大,错误率越大
2)森林中每棵树的分类能力:每棵树的分类能力越强,整个森林的错误率越低
减小特征选择个数m,树的相关性和分类能力也会相应的降低;增大m,两者也会随之增大。所以关键问题是如何选择最优的m(或者是范围),这也是随机森林唯一的一个参数。
26.2.3袋外误差率
如何选择最优的特征个数m,要解决这个问题,我们主要依据计算得到的袋外错误率oob error(out-of-bag error)。
随机森林有一个重要的优点就是,没有必要对它进行交叉验证或者用一个独立的测试集来获得误差的一个无偏估计。它可以在内部进行评估,也就是说在生成的过程中就可以对误差建立一个无偏估计。
我们知道,在构建每棵树时,我们对训练集使用了不同的bootstrap sample(随机且有放回地抽取)。所以对于每棵树而言,部分训练实例没有参与这棵树的生成,它们称为第k棵树的oob样本。
袋外错误率(oob error)计算方式如下:
1)对每个样本计算它作为oob样本的树对它的分类情况
2)以简单多数投票作为该样本的分类结果
3)最后用误分个数占样本总数的比率作为随机森林的oob误分率
26.3随机采样与完全分裂
在建立每一棵决策树的过程中,有两点需要注意,分别是采样与完全分裂。
26.3.1随机采样
首先是两个随机采样的过程,random forest对输入的数据要进行行、列的采样。对于行采样,采用有放回的方式,也就是在采样得到的样本集合中,可能有重复的样本。假设输入样本为N个,那么采样的样本也为N个。这样使得在训练的时候,每一棵树的输入样本都不是全部的样本,使得相对不容易出现over-fitting。然后进行列采样,从M个feature中,选择m个(m << M)。
有放回抽样的解释
如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是”有偏的”,都是绝对”片面的”(当然这样说可能不对),也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决,这种表决应该是”求同”,因此使用完全不同的训练集来训练每棵树这样对最终分类结果是没有帮助的,这样无异于是”盲人摸象”。
对Bagging的改进
随机森林对Bagging的改进就在于随机采用的不同,即以下两点:
1)Random forest是选与输入样本的数目相同多的次数(可能一个样本会被选取多次,同时也会造成一些样本不会被选取到),而bagging一般选取比输入样本的数目少的样本;
2)bagging是用全部特征来得到分类器,而Random forest是需要从全部特征中选取其中的一部分来训练得到分类器; 一般Random forest效果比bagging效果好。
26.3.2完全分裂
之后就是对采样之后的数据使用完全分裂的方式建立出决策树,这样决策树的某一个叶子节点要么是无法继续分裂的,要么里面的所有样本的都是指向的同一个分类。一般很多的决策树算法都一个重要的步骤 - 剪枝,但是这里不这样干,由于之前的两个随机采样的过程保证了随机性,所以就算不剪枝,也不会出现over-fitting。 按这种算法得到的随机森林中的每一棵都是很弱的,但是大家组合起来就很厉害了。
26.4随机森林的变体
也可以使用SVM、Logistic回归等其他分 类器,习惯上,这些分类器组成的“总分类器”,仍然叫做随机森林。
比如回归问题,图中离散点为臭氧(横轴)和温度(纵轴)的关系,试拟合变化曲线,记原始数据为D,长度为N(即图中有N个离散点)
算法过程为:
1)做100次bootstrap,每次得到的数据Di,Di的长度为N
2)对于每一个Di,使用局部回归(LOESS)拟合一条曲线(图 中灰色线是其中的10条曲线)
3)将这些曲线取平均,即得到红色的最终拟合曲线
4)显然,红色的曲线更加稳定,并且没有过拟合明显减弱
第27章AdaBoost算法
27.1集成学习
27.1.1定义
所谓集成学习(ensemble learning),是指通过构建多个弱学习器,然后结合为一个强学习器来完成分类任务。并相较于弱分类器而言,进一步提升结果的准确率。严格来说,集成学习并不算是一种分类器,而是一种学习器结合的方法。
下图显示了集成学习的整个流程:首次按产生一组“个体学习器”,这些个体学习器可以是同质的(homogeneous)(例如全部是决策树),这一类学习器被称为基学习器(base learner),相应的学习算法称为“基学习算法”;集成也可包含不同类型的个体学习器(例如同时包含决策树和神经网络),这一类学习器被称为“组件学习器”(component learner)。
集成学习通过将多个学习器进行结合,可获得比单一学习器显著优越的泛化性能,它基于这样一种思想:对于一个复杂任务来说,将多个专家的判断进行适当的综合所得出的判断,要比其中任何一个专家单独的判断好,直观一点理解,就是我们平时所说的“三个臭皮匠,顶个诸葛亮”,通过使用多个决策者共同决策一个实例的分类从而提高分类器的泛化能力。
27.1.2集成学习的条件
当然,这种通过集成学习来提高学习器(这里特指分类器)的整体泛化能力也是有条件的:
首先,分类器之间应该具有差异性,即要有“多样性”。很容易理解,如果使用的是同一个分类器,那么集成起来的分类结果是不会有变化的。‘
其次,每个个体分类器的分类精度必须大于0.5,如果p<0.5p<0.5那么随着集成规模的增加,分类精度会下降;但如果是大于0.5的话,那么最后最终分类精度是可以趋于1的。
因此,要获得好的集成,个体学习器应该“好而不同”,即个体学习器要有一定的“准确性”,即学习器不能太坏,并且要有“多样性”,即学习器间具有差异。
27.1.3集成学习的分类
当前,我们可以立足于通过处理数据集生成差异性分类器,即在原有数据集上采用抽样技术获得多个训练数据集来生成多个差异性分类器。根据个体学习器的生成方式,目前集成学习方法大致可分为两大类:第一类是个体学习器之间存在强依赖关系、必须串行生成的序列化方法,这种方法的代表是“Boosting”;第二类是个体学习器间不存在强依赖关系、可同时生成的并行化方法,它的代表是“Bagging”和“Random Forest”
Bagging:通过对原数据进行有放回的抽取,构建出多个样本数据集,然后用这些新的数据集训练多个分类器。因为是有放回的采用,所以一些样本可能会出现多次,而其他样本会被忽略。该方法是通过降低基分类器方法来改善泛化能力,因此Bagging的性能依赖于基分类器的稳定性,如果基分类器是不稳定的,Bagging有助于减低训练数据的随机扰动导致的误差,但是如果基分类器是稳定的,即对数据变化不敏感,那么Bagging方法就得不到性能的提升,甚至会降低。
Boosting:提升方法是一个迭代的过程,通过改变样本分布,使得分类器聚集在那些很难分的样本上,对那些容易错分的数据加强学习,增加错分数据的权重,这样错分的数据再下一轮的迭代就有更大的作用(对错分数据进行惩罚)。
Bagging与Boosting的区别:
二者的主要区别是取样方式不同。Bagging采用均匀取样,而Boosting根据错误率来取样,因此Boosting的分类精度要优于Bagging。Bagging的训练集的选择是随机的,各轮训练集之间相互独立,而Boostlng的各轮训练集的选择与前面各轮的学习结果有关;Bagging的各个预测函数没有权重,而Boosting是有权重的;Bagging的各个预测函数可以并行生成,而Boosting的各个预测函数只能顺序生成。对于象神经网络这样极为耗时的学习方法。Bagging可通过并行训练节省大量时间开销。
bagging是减少variance,而boosting是减少bias。Bagging 是 Bootstrap Aggregating 的简称,意思就是再取样 (Bootstrap) 然后在每个样本上训练出来的模型取平均,所以是降低模型的 variance. Bagging 比如 Random Forest 这种先天并行的算法都有这个效果。Boosting 则是迭代算法,每一次迭代都根据上一次迭代的预测结果对样本进行加权,所以随着迭代不断进行,误差会越来越小,所以模型的 bias 会不断降低。这种算法无法并行。
27.2AdaBoost算法
27.2.1AdaBoost算法思想
对于分类问题而言,给定一个训练样本集,求比较粗糙的分类规则(弱分类器)要比求精确地分类规则(强分类器)容易得多。提升算法就是从弱学习算法出发,反复学习,得到一系列弱分类器(又称为基本分类器),然后组合这些弱分类器,构成一个强分类器。大多数的提升方法都是改变训练数据的概率分布(训练数据的权值分布),针对不同的训练数据分布调用弱学习算法学习一系列弱分类器。
这样,对提升方法来说,有两个问题需要回答:一是在每一轮如果改变训练数据的权值或概率分布;二是如何将弱分类器组合成一个强分类器。对于第一个问题,AdaBoost的做法是,提高那些被前一轮弱分类器错误分类样本的权值,而降低那些被正确分类样本的权值。这样一来,那些没有得到正确分类的数据,由于其权值的加大而受到后一轮的弱分类器的更大关注,于是,分类问题就被一系列的弱分类器“分而治之”。至于第二个问题,即弱分类器的组合,AdaBoost采取加权多数表决的方法。具体地,加大分类误差率小的弱分类器的权值,使其在表决中起较大的作用,减小分类误差率较大的弱分类器的权值,使其在表决中起较小的作用。
AdaboostBoost的算法的框架如下图所示
具体来说,整个AdaBoost算法包括以下三个步骤:
1)初始化训练样本的权值分布。如果有N个样本,则每一个训练样本最开始时都被赋予相同的权值:1/N1/N。
2)训练弱分类器。具体训练过程中,如果某个样本已经被准确地分类,那么在构造下一个训练集中,它的权值就会被降低;相反,如果某个样本点没有被准确地分类,那么它的权值就得到提高。然后,权值更新过的样本被用于训练下一个分类器,整个训练过程如果迭代地进行下去,使得分类器在迭代过程中逐步改进。
3)将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用。换言之,误差率低的弱分类器在最终分类器中权重较大,否则较小。得到最终分类器。
27.2.2AdaBoost算法流程
27.2.3AdaBoost算法的一个实例
27.3AdaBoost算法的训练误差分析
27.3.1AdaBoost的训练误差界
27.3.2二类分类问题AdaBoost的训练误差界
27.3.3推论
27.4AdaBoost算法的数学推导
27.4.1前向分布算法
27.4.2基于前向分布算法的AdaBoost推导
第28章XgBoost算法
28.1XGBoost简介
在数据建模中,经常采用Boosting方法通过将成百上千个分类准确率较低的树模型组合起来,成为一个准确率很高的预测模型。这个模型会不断地迭代,每次迭代就生成一颗新的树。但在数据集较复杂的时候,可能需要几千次迭代运算,这将造成巨大的计算瓶颈。
针对这个问题。华盛顿大学的陈天奇博士开发的XGBoost(eXtreme Gradient Boosting)基于C++通过多线程实现了回归树的并行构建,并在原有Gradient Boosting算法基础上加以改进,从而极大地提升了模型训练速度和预测精度。
在Kaggle的希格斯子信号识别竞赛,XGBoost因为出众的效率与较高的预测准确度在比赛论坛中引起了参赛选手的广泛关注,在1700多支队伍的激烈竞争中占有一席之地。随着它在Kaggle社区知名度的提高,最近也有队伍借助XGBoost在比赛中夺得第一。其次,因为它的效果好,计算复杂度不高,也在工业界中有大量的应用。
28.2监督学习的三要素
因为Boosting Tree本身是一种有监督学习算法,要讲Boosting Tree,先从监督学习讲起。在监督学习中有几个逻辑上的重要组成部件,粗略地可以分为:模型、参数、目标函数和优化算法。
28.2.1模型
28.2.2参数
28.2.3目标函数:误差函数+正则化项
28.2.4优化算法
上面三个部分包含了机器学习的主要成分,也是机器学习工具划分模型比较有效的办法。其实这几部分之外,还有一个优化算法,就是给定目标函数之后怎么学的问题。有时候我们往往只知道“优化算法”,而没有仔细考虑目标函数的设计问题,比如常见的例子如决策树的学习算法的每一步去优化基尼系数,然后剪枝,但是没有考虑到后面的目标是什么。而这些启发式优化方法背后往往隐含了一个目标函数,理解了目标函数本身也有利于我们设计相应的学习算法。
28.3回归树与树集成
28.3.1回归树
28.3.2树集成
28.4XGBoost的推导过程
28.4.1XGBoost的目标函数与泰勒展开
28.4.2决策树的复杂度
28.4.3目标函数的最小化
28.4.4枚举树的结果——贪心法
第29章GBDT算法
29.1Regression Desicion Tree:回归树
29.1.1回归树简介
29.1.2回归树的生成
29.2Boosting Decision Tree:提升树
29.2.1提升树模型
29.2.2提升树算法
29.2.3提升树实例
29.3Gradient Boosting Decision Tree:梯度提升决策树
29.3.1GBDT简介
29.3.2GBDT算法步骤