GMM-HMM学习笔记
最近几天钻研了语音处理中的GMM-HMM模型,阅读了一些技术博客和学术论文,总算是对这个框架模型和其中的算法摸清了皮毛。在这里梳理一下思路,总结一下这几天学习的成果,也是为以后回顾时提高效率。
本文主要结合论文和博客资料来介绍我对GMM-HMM的理解,主要分为以下几个部分:第一个部分介绍语音识别总体框架,第二部分介绍典型的HMM结构和识别过程,第三部分介绍HMM的学习算法,最后补充介绍一些其他细枝末节的相关点。
1. 语音识别总体框架
首先,如下图所示是一个常见的语音识别框架图,语音识别系统的模型通常由声学模型和语言模型两部分组成,分别对应于语音到音节概率的计算和音节到字概率的计算。这里我们要探讨的GMM-HMM模型属于其中的声学模型。 而语言模型是用来计算一个句子出现概率的概率模型。它主要用于决定哪个词序列的可能性更大,或者在出现了几个词的情况下预测下一个即将出现的词语的内容,即用来约束单词搜索。
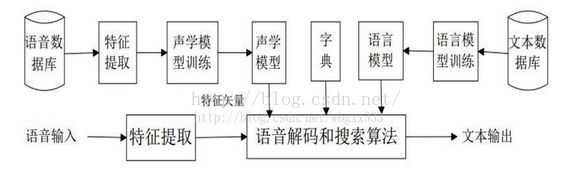
接下来,如下所示是一个更具体一些的语音识别框架图。很明显,在这个图中,我们已经将声学模型明确为GMM-HMM模型。从这个图中已经可以看到GMM和HMM的雏形了。
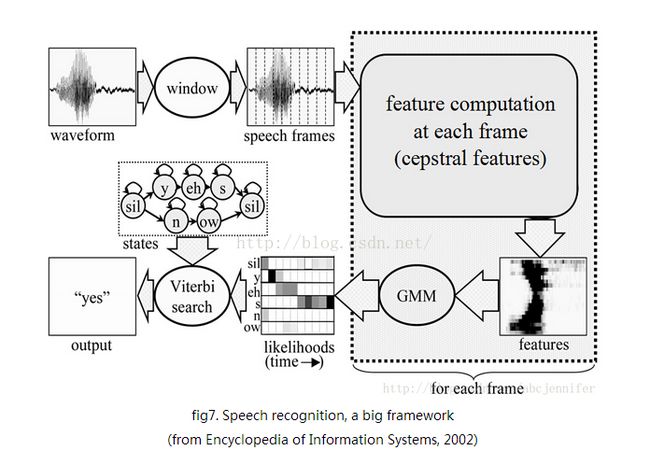
从这两个图中,可以归纳语音识别的主要步骤包括: (1)预处理模块: 对输入的原始语音信号进行处理,滤除掉其中的不重要的信息以及背景噪声,并进行相关变换处理。(2)特征提取:提取出反映语音信号特征的关键特征参数形成特征矢量序列,常用的是由频谱衍生出来的Mel频率倒谱系数(MFCC)。典型地,用长度约为10ms的帧去分割语音波形,然后从每帧中提取出MFCC特征,共39个数字,用特征向量来表示。(3)声学模型训练:根据训练语音库的特征参数训练出声学模型参数,识别时将待识别的语音的特征参数同声学模型进行匹配,得到识别结果。目前的主流语音识别系统多采用隐马尔可夫模型HMM进行声学模型建模,这将在下一节进行介绍。(4)语言模型训练:语言建模能够有效的结合汉语语法和语义的知识,描述词之间的内在关系,从而提高识别率,减少搜索范围。对训练文本数据库进行语法、语义分析,经过基于统计模型训练得到语言模型。(5)语音解码:即指语音技术中的识别过程。针对输入的语音信号,根据己经训练好的HMM声学模型、语言模型及字典建立一个识别网络,根据搜索算法在该网络中寻找最佳的一条路径,这个路径就是能够以最大概率输出该语音信号的词串。
2. GMM-HMM结构和识别过程
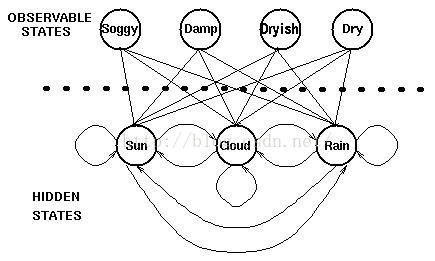

援引zouxy09大神的话“ HMM是对语音信号的时间序列结构建立统计模型,将其看作一个数学上的双重随机过程:一个是用具有有限状态数的Markov链来模拟语音信号统计特性变化的隐含(马尔可夫模型的内部状态外界不可见)的随机过程,另一个是与Markov链的每一个状态相关联的外界可见的观测序列(通常就是从各个帧计算而得的声学特征)的随机过程。”在单词词典(lexicon)中,根据每个单词的发音过程,以音素作为隐藏节点,音素的变化过程构成了HMM状态序列。每一个音素以一定的概率密度函数生成观测向量(即MFCC特征向量)。在GMM-HMM中,用高斯混合函数去拟合这样的概率密度函数。如下图所示是一个GMM-HMM的模型框架示意图。
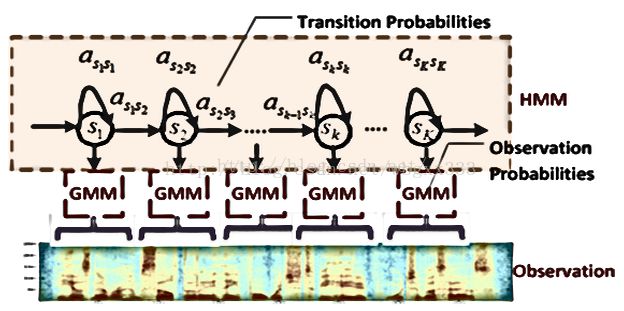
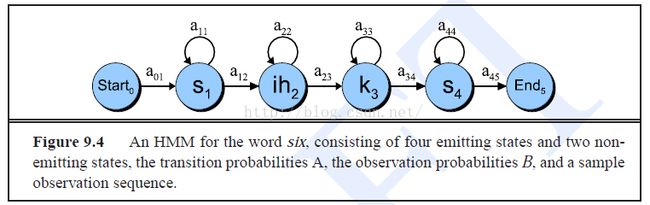
再来看一个语音识别中HMM的示意图,如下英文单词“six”所示,可以看到隐藏节点的每一个状态对应于一个单独音素,单词“six”的HMM结构由这一系列的音素状态连接而成。需要注意的是,在这里的HMM结构中,由于语音的时间序列特性,HMM不允许靠后状态到靠前状态之间的状态转换。一般地,状态转换只允许自环转换和到后一节点的转换。自环转换的存在是因为有的音素可能会持续较长时间。
如果我们得到了各个单词的HMM模型,那么识别的过程如下图所示。我们以单词“one”,“two”,“three”为例,分别计算观测数据的后验概率,并从中去概率最大的单词作为识别结果。

那么如何计算在某个HMM模型下,已知观测数据的后验概率呢?这对应的就是隐马尔科夫的第一类问题,我们采用前向算法计算这一概率值。以单词“five”为例,为了计算概率该模型下已知观测数据出现的概率P(O|M),我们对所有可能的隐状态序列的概率值进行加和。假设单词“five”由三个音素[f],[ay]和[v]组成(或者说,隐藏节点包含这三种状态),那么一个由10帧构成的观测序列可能对应如下一些隐状态序列:

对于每一种隐状态序列,根据初始概率向量,状态转移矩阵和混合高斯模型计算隐状态和观测状态同时出现的概率,然后对所有以上情形进行概率求和,便得到了P(O|M)。更具体地,《Speech and Language Processing: An introductiontonatural language processing, computational linguistics, and speechrecognition》的9.6节对前向算法和Viterbi算法的计算细节进行了展示说明。
以上部分是针对每个单词分别建立HMM,但这种思路在连续大词汇量语音识别中就不太实用,因为单词数量太多,而且连续语音中相同单词的发音也可能会有所不同。这时,我们将识别单元缩小,为每个音素建立一个HMM。连续语音识别的基本思想就是找出所有音素,并为它们分别建立HMM模型。对于每一个音素HMM,它通常由5个状态组成,其中第一个和最后一个状态没有实际意义,中间三个状态分别代表着音素开始阶段、音素稳定阶段和音素结束阶段,如下图所示。这一部分可以参考Reference 10这篇博文,讲解比较清晰易懂,另外它对embedded training的讲解也比较清晰。

3. 学习算法
E(estimate)-step: 根据当前参数 (means, variances, mixing parameters)估计P(j|x)
M(maximization)-step: 根据当前P(j|x) 计算GMM参数
而HMM也是采用的类似于EM算法的前向后向算法(Baum-Welch算法),过程为:
E(estimate)-step: 给定observation序列,估计时刻t处于状态sj的概率
M(maximization)-step: 根据该概率重新估计HMM参数aij.
具体计算公式和过程参见Reference 2和Reference 11。
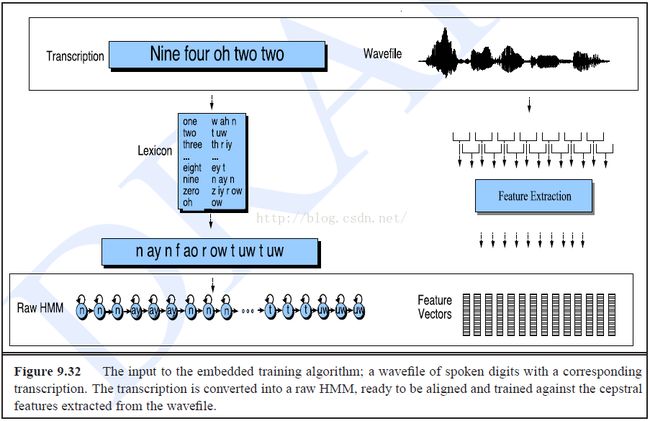
然后开始在整个训练集上对参数A和B进行迭代地更新,Baum-Welch算法是嵌入式训练中的一个组成部分。整个嵌入式训练过程如下:
给定:语音波形数据集(Wavefile),对应翻译(Transcription),单词发音词典(Pronunciation Lexicon)
Step 1:构建整个句子的HMM结构
Step 2:将A矩阵中对应于自环和后继的项初始化为0.5,其他项初始化为0
Step 3:用整个训练集的全集均值和方差对B矩阵进行初始化
Step4:运行Baum-Welch算法的迭代过程。在每一次迭代中,计算前向概率和后向概率以得到t时刻处于状态i的概率,
然后将它用于更新参数A和B。重复迭代过程,直至系统收敛。
4. 其他
至此将语音识别的皮毛(只敢说皮毛,不敢说基本框架)总结完了,对自己这几天的学习有了个交待。最后,一些博客上经常出现诸如subphone,triphone等更高级的内容,却没有做清楚的表述。对于这些内容,可以去研读相关学术论文。subphone在Reference 8的9.2节进行了介绍,triphone在Reference 8的10.3节进行了介绍。Reference 9介绍了tied-mixturetriphone,其中包含了高斯分裂,没太看懂。
Reference:
1. 语音识别的基础知识与CMUsphinx介绍(http://blog.csdn.net/zouxy09/article/details/7941585)
2. GMM-HMM语音识别模型原理篇(http://blog.csdn.net/abcjennifer/article/details/27346787)
3. 语音识别系统原理介绍---从gmm-hmm到dnn-hmm(http://blog.csdn.net/wbgxx333/article/details/18516053)
4. GMM-HMM语音识别简单理解(http://www.cnblogs.com/tornadomeet/archive/2013/08/23/3276753.html)
5. HMM学习最佳范例(http://www.52nlp.cn/hmm-learn-best-practices-one-introduction)
6. EM及高斯混合模型(http://www.cnblogs.com/zhangchaoyang/articles/2624882.html)
7. A Tutorial on Hidden MarkovModels and Selected Applications in Speech Recognition
8. Speech and Language Processing:An introduction to natural language processing, computational linguistics, andspeech recognition(2006)
9. Tree-Based State Tying for HighAccuracy Modelling
10. HMM+GMM语音识别技术详解级PMTK3中的实例(http://blog.csdn.net/fandaoerji/article/details/44853853)
11. Hidden Markov Models and Gaussian Mixture Models (http://www.inf.ed.ac.uk/teaching/courses/asr/2012-13/asr03-hmmgmm-4up.pdf)