T-SQL执行内幕(1)——简介
本文属于SQL Server T-SQL执行内幕系列
前言:
本文主体内容来自于:http://rusanu.com/2013/08/01/understanding-how-sql-server-executes-a-query/但是经常打不开,本人又在:https://www.codeproject.com/Articles/630346/Understanding-how-SQL-Server-executes-a-query 发现几乎跟原文一模一样的内容,并且网上大多收录这篇而不是原文。 不过提醒一下第二篇文章中对原文进行了少量的删减。
一开始想直译,但是看了内容之后,觉得略微有点难读,加上自己对这方面也有点想法,所以打算把它作为一个引子,在不影响作者内容跟信息准确性的前提下添加自己的看法。所以如果读者看原文的话,会发现跟原文并不完全一样。
本文不适合初学者看,除非你的学习能力很好,但是不代表所谓的初学者不能看,我只是给个忠告而已,因为内容较深入,可能会影响兴趣。
目录:
本系列内容较多,原文本身已经很多,加上个人添加的内容之后,篇幅过长,不便于阅读,过长的篇幅也容易造成阅读疲劳,所以我把它们拆分:
- T-SQL执行内幕(1)——简介
- T-SQL执行内幕(2)——Tasks、Workers、Threads、Scheduler、Sessions、Connections、Requests
- T-SQL执行内幕(3)——解析和编译
- T-SQL执行内幕(4)——优化
- T-SQL执行内幕(5)——执行
- T-SQL执行内幕(6)——返回结果
- T-SQL执行内幕(7)——内存授予
- T-SQL执行内幕(8)——数据存储
- T-SQL执行内幕(9)——数据访问
- T-SQL执行内幕(10)——读取数据
- T-SQL执行内幕(11)——Read Ahead
- T-SQL执行内幕(12)——锁、闩锁
- T-SQL执行内幕(13)——写数据
- T-SQL执行内幕(14)——DDL
- T-SQL执行内幕(15)——备份、还原和DBCC
- T-SQL执行内幕(16)——总结
SQL Server数据库引擎有两大核心:存储引擎(Storage Engine)和查询处理器(Query Processor),也叫关系引擎(Relational Engine)
- 存储引擎:负责在磁盘与内存之间以某种方式读取数据。并且在这个过程中维护数据一致性及并发性。
- 查询处理器/关系引擎:接受提交到SQL Server的所有查询,并为其选择最佳执行计划,然后把执行计划执行最后返回结果。
正文:
如果你是一个普通数据库开发人员,那了解增删改查的T-SQL写法基本上就能开始工作了,但是随着时间的推移和外界的不断变化,除非你转到别的领域,不然迟早你要面对这个问题——为什么我的SQL慢?这个问题衍生出另外三个有意思的问题:
- 怎样发现慢查询或者高开销查询?(Troubleshooting)
- 怎样改进(PerformanceTuning)
- 监控效果(Monitoring)
之所以说这些是“问题”,是因为大部分的人包括我自己在很多时候都知道要做这些,但是怎么做?要回答这些越来越深入的问题,首先必须先了解根源——TSQL的运行内幕。了解T-SQL是如何运行的,那么大部分的语句及其相关问题都能从中得到或多或少的启发。才能更好地回答“为什么我的数据库性能差”。
但是篇幅原因,本系列只是主要介绍SQLServer 的执行机制。闲话不说,先上图:

上图是一个T-SQL从发起到得到结果的流程示意图(最左下角是发起,最右下角是返回)。下面对一些后续要用到的术语和这个图进行简要介绍。图中有几个重要术语:请求(request)、任务(task)、工作线程(worker),下面将一一简介。如果觉得概念比较乱,可以直接先跳到T-SQL执行内幕(2)——Tasks、Workers、Threads、Scheduler、Sessions、Connections、Requests一节。
Requests
请求,SQL Server是一个客户端-服务器平台,与数据库交互的唯一方式就是通过发送包含有命令的请求给数据库。而客户端与服务器直接的通讯协议称为TDS(Tabular Data Stream),如果读者有兴趣可以看一下MSDN的文档:https://msdn.microsoft.com/en-us/library/dd304523.aspx,服务器的请求列表可见sys.dm_exec_requests 。
应用程序使用诸如SqlClient、OleDB、ODBC、JDBC等驱动来实现这种协议。当应用程序需要数据库完成任何事情时,都会通过TDS协议发送一个请求(request)给数据库引擎。
简单来说,每次对数据库的操作都会以“请求”的形式发送给数据库服务器。所以请求是T-SQL生命周期的开始。上图左下角绿色块。
请求的主要分类有以下三类:Batch Request、RPC Request、Bulk Load Request
Batch Request:
批请求,即一个请求中包含了一个或多个T-SQL文本(语句)。这种类型无参数,但可以包含本地变量。通常由SqlCommand.ExecuteReader()/ExecuteNonQuery()/ExecuteScalar()/ExecuteXmlReader ()等SqlCommand类并且参数列表为空的对象从客户端发起。
另外我们最常用的在SSMS中输入一些普通SQL语句并执行的方式也是批请求。过去监控Long Running Query的时候常用的Profiler/SQL Trace工具,如果要抓批请求所使用的语句,需要选择SQL:BatchStarting事件。这是批请求开始时的语句,也可以把SQL:BatchCompleted事件也包含进去以便计算运行时间。
除此之外,Batch 对应的处理速度(可以在性能计数器中找到SQLServer: SQL Statistics: Batch Requests/Sec),也从侧面看出整个系统的性能,是很重要的指标,不过不要单方面下定论,这个指标并不能单纯指出问题,通常只能直接得知系统的“繁忙程度”而已。我不想在一开始就过于深入地讨论如何优化,先沉下心来把原理搞懂了,很多问题就自然有了解决方法。
Remote Procedure Call Request:
简称RCP请求,这种类型的请求包含任意数量参数的需要执行的RPC名字或Procedure ID。比如sp_execute,第一个参数是一段要执行的T-SQL文本。每个RPC是独立的,不能混在其他SQL语句中。
最常见的RPC请求就是在客户端调用带有参数的存储过程。另外一个不严谨的区分就是RPC通常是外部应用(如Windows 服务、Web Services等发出的请求)。对这种请求的监控可以使用Profiler/Trace的RPC:Starting事件。我们可以从下图的所属类别大概看出,RPC事件归到存储过程事件中,而Batch归到TSQL事件中,但是我觉得这个并不需要过多关注,除非你想做更深入的研究:

Bulk Load Request:
Bulkload是一个特殊的请求,专用于bulk insert操作,比如使用bcp.exe或者SqlBulkcopy类进行大容量导入。跟前面两种请求不同,它是唯一一种“先执行再通过TDS协议传输请求”的请求。
小结
当请求通过TDS到达服务器之后,SQL Server会创建一个任务(Task)来处理请求,可以简单理解为,当request到达SQL Server之后,后续操作都发生在SQL Server内部。从执行流程来说,现在已经是:Requests→TDS→Tasks。
Tasks
任务,上面说过,task(任务)是请求从开始到完成的表现方式。task可以有子任务(subtask),如果有多个task,SQL Server会使用task queue(任务队列)来存放任务列表。如果请求是SQL 批,则task为整个批而不是单独语句。在SQL批中的单独语句不创建新的任务,除非语句(不是指批)以并行方式执行时会产生子任务来并行执行。一旦请求返回结果并且客户端进行数据处理完毕(如使用SqlDataReader读取数据),请求就算完成。
服务器的任务列表可见sys.dm_os_tasks。如果需要了解会话ID对应的Windows线程ID,可以使用下面语句查看,得到线程ID之后,使用Windows性能监视器来监视线程的性能。这个在查询一些服务是否有性能问题时比较有用,但是这个语句不返回正处于sleeping状态的会话:
SELECT STasks.session_id, SThreads.os_thread_id
FROM sys.dm_os_tasks AS STasks
INNER JOIN sys.dm_os_threads AS SThreads
ON STasks.worker_address = SThreads.worker_address
WHERE STasks.session_id IS NOT NULL
ORDER BY STasks.session_id;
GO- PENDING:正在等待工作线程,worker。
- RUNNABLE:可运行但正在等待接收量程。
- RUNNING:当前正在Scheduler中运行。
- SUSPENDED:拥有worker但是正在等待某些事件。sys.dm_os_schedulers
- DONE:已经完成。
- SPINLOOP:陷入自旋锁。
在这一阶段,SQL Server无法得知请求的具体内容,为了执行任务,SQL Server需要指派一个Worker用于服务这个任务。到这一步,执行流程就到了:Requests→TDS→Tasks→Workers。
Workers
工作线程,Worker是SQL Server线程池(Thread pool),当服务器启动时,根据SQL Server的max_worker_threads(下图红圈部分)按需创建。只有worker能执行代码,并且空闲的Workers会等待挂起(pending)的任务变成可用(Runnable)之后,worker才执行某个任务。从worker开始执行任务到任务完成之前,这个worker处于busy状态。当没有可用的worker时,任务(task)就会变成pending状态等待有空闲的worker执行它为止。
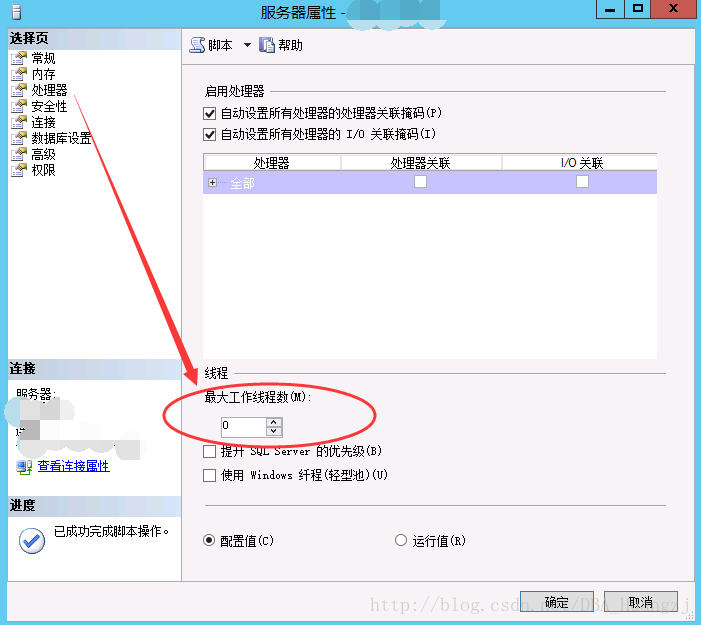
对于工作线程数,默认值为0,意味着自动配置,对绝大多数系统而言是最佳设置,但是并不代表永远最佳,一般情况下,每个查询会创建一个单独的操作系统线程来服务请求(1:1),但是如果服务器的连接达到数以百计的时候,为每个请求分配一个线程会占用大量的系统资源,此时这个配置可以使SQL Server可以为更多的查询请求创建一个工作线程(N:1),从而提高性能。官方建议如下:
CPU 数 |
32 位计算机 |
64 位计算机 |
|---|---|---|
<= 4 个处理器 |
256 |
512 |
8 个处理器 |
288 |
576 |
16 个处理器 |
352 |
704 |
32 个处理器 |
480 |
960 |
但是注意如果所有的Worker都处于活动状态,SQL Server可能出现停止响应的状态,直到有工作线程可用为止。此时需要使用专用管理员连接(Dedicated Administrator Connection,DAC)连到SQL Server进行kill操作。
对于SQL 批请求,worker会执行整个批而不是单独的SQL。这就引出一个问题“SQL批中的语句能否并行执行?”答案是否定的,因为他们是串行执行,每个Thread(worker)每次只执行批中的一个SQL,完成后继续执行批里面的下一个SQL。对于那些使用并行执行(DOP配置要>1)的语句,会创建子任务,每个子任务使用相同的方式执行:创建一个PENDING的子任务然后等待worker(由于执行这个批的worker已经标注为占用/繁忙,所以这里的worker是另外一个不同的worker)执行。Worker的清单可以查询DMV: sys.dm_os_workers。换句话说,对于一个并行执行语句,会有多个Worker来协助批处理执行,但是也是串行执行。
当分配了Worker之后,执行流程就到了:Requests→TDS→Tasks→Workers→编译/优化
小结:
本节作为本系列的开篇,介绍了一些基础概念,主要集中在从客户端发起请求到SQL Server的过程,下一节将介绍Tasks、Workers、Threads、Scheduler、Sessions、Connections、Requests这几个概念,以便更好地深入学习。