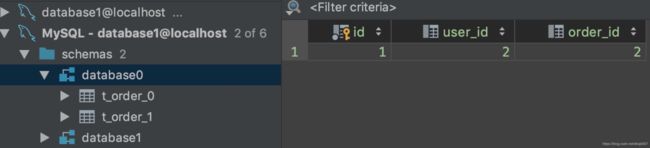
create table t_order_0
(
id int auto_increment
primary key,
user_id int null,
order_id int null
);
create table t_order_1
(
id int auto_increment
primary key,
user_id int null,
order_id int null
);
返回做IO数目最多的50条语句以及它们的执行计划。
select top 50
(total_logical_reads/execution_count) as avg_logical_reads,
(total_logical_writes/execution_count) as avg_logical_writes,
(tot
The CUDA 5 Release Candidate is now available at http://developer.nvidia.com/<wbr></wbr>cuda/cuda-pre-production. Now applicable to a broader set of algorithms, CUDA 5 has advanced fe
Essential Studio for WinRT界面控件包含了商业平板应用程序开发中所需的所有控件,如市场上运行速度最快的grid 和chart、地图、RDL报表查看器、丰富的文本查看器及图表等等。同时,该控件还包含了一组独特的库,用于从WinRT应用程序中生成Excel、Word以及PDF格式的文件。此文将对其另外一个强大的控件——网格控件进行专门的测评详述。
网格控件功能
1、
Project Euler是个数学问题求解网站,网站设计的很有意思,有很多problem,在未提交正确答案前不能查看problem的overview,也不能查看关于problem的discussion thread,只能看到现在problem已经被多少人解决了,人数越多往往代表问题越容易。
看看problem 1吧:
Add all the natural num
Adding id and class names to CMenu
We use the id and htmlOptions to accomplish this. Watch.
//in your view
$this->widget('zii.widgets.CMenu', array(
'id'=>'myMenu',
'items'=>$this-&g
Given a collection of integers that might contain duplicates, nums, return all possible subsets.
Note:
Elements in a subset must be in non-descending order.
The solution set must not conta