Java+Jsoup实现最基本的网页爬虫功能
Java+Jsoup实现最基本的网页爬虫功能
Jsoup简介
Jsoup是一款Java的HTML解析器,可直接解析某个URL地址,HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于Jquery的操作方法取出和操作数据。
Jsoup的主要功能如下
- 从一个URL,文件或字符串中解析HTML;
- 使用DOM或CSS选择器来查找,取出数据;
- 可操作性HTML元素,属性,文本;
Jsoup是基于MIT协议发布的,可放心适用于商业项目。
最近在写项目的时候正好需要使用爬虫功能,所以就先学习了一下。目标是爬一个学校网站的新闻首页,然后保存在本地数据库,本片文章先介绍第一步,如何使用Java语言爬去静态网页上的信息。
第一步 导入Jsoup jar包
我自己建的项目是Maven项目,直接在pom文件中加入以下依赖就ok了。不是Maven项目需要jar包的可以评论以下我私发给你。
org.jsoup
jsoup
1.9.2
第二步 获取网页,通过Jsoup解析网页内容
Jsoup处理HTML文件,是将用户输入的HTML文档,解析转换成一个Document对象进行处理。Jsoup一般支持一下几种来源内容的转换。全部代码在最下方。
- 解析一个HTML字符串
- 解析一个Body片段
- 根据一个url地址加载Document对象
- 根据一个文件加载Document对象
我们有URL地址,所以采用URL来加载Document对象。
//通过Jsoup的Connect方法获取document类
Document document = Jsoup.connect("http://www.haie.edu.cn/xyxw.htm").get();
System.out.println(document.title());//控制台打印网页标题
我们可以根据URL获取一个Document对象,然后我们可以对这个Document对象进行操作,网页解析。这时候就需要对你想爬取的网站进行分析了,我要爬取的是一个较为规范的校园新闻网页,如下图:
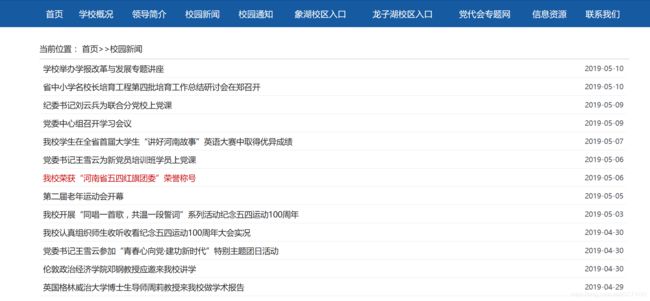
单击右键,选择检查选项,就我的这个网页来说,我想取的信息是校园新闻的标题,新闻URL以及后边的标题。检查网页,看看这些html标签有没有相同的标识,如:
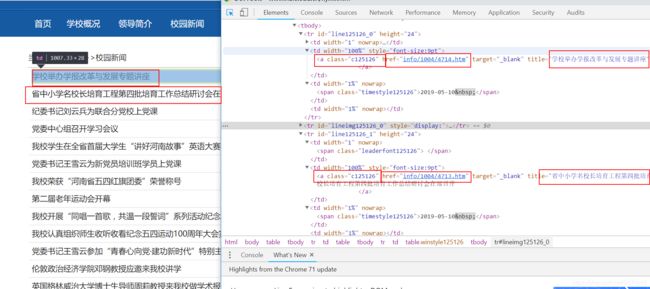
图上可以看到,网页新闻标题的a标签统一使用 class = “c125126” 这个样式,同理的我们也可以取到后面的时间标签。
Document类有很多方法可以用来获取内容,常用的方法如下:
查找元素:
- getElementById(String id)
- getElementsByTag(String tag)
- getElementsByClass(String className)
- getElementsByAttribute(String key)
元素数据:
- attr(String key)获取属性attr(String key, String value)设置属性
- attributes()获取所有属性
- id() , className() and classNames()
- text() 获取文本内容
用的比较多的就是这些,我们刚刚知道了新闻a标签都具有相同的class,可以使用getElementsByClass 方法获取Elements。
//根据class获取Elements类
Elements titleElement = document.getElementsByClass("c125126");//标题
Elements timeElement = document.getElementsByClass("timestyle125126");//时间
我们可以根据获取的Element类来取到我们想要的文字内容。输出到控制台看起来不是很舒服,我把它写入到指定的txt文件里,这样看起来比较舒服。
//指定文件名及路径
File file = new File("D:\\Jsoup\\title.txt");
File contentFile = new File("D:\\Jsoup\\content.txt");
if(!file.exists()){
file.createNewFile();
}
if(!contentFile.exists()){
contentFile.createNewFile();
}
//写入本地
PrintWriter pw = new PrintWriter("D:\\Jsoup\\title.txt");
PrintWriter contentPw = new PrintWriter("D:\\Jsoup\\content.txt");
for (int i = 0; i < titleElement.size(); i++) {
pw.println(titleElement.get(i).text());
pw.println(titleElement.get(i).attr("href"));
pw.println(timeElement.get(i).text());
pw.println("---------------------------");
}
pw.close();
这里我们取到了新闻的标题和URL,把它输入到了指定的文件中,然后我们根据每个新闻的URL,再次重复第一步动作,打开这个URL,连接到新闻详细信息网页,抓取新闻的详细信息,和作者时间等信息。

分析了页面之后,操作和上面一样,取出作者和文章详细内容。
for (int i = 0; i < titleElement.size(); i++) {
String href = titleElement.get(i).attr("href");//取出新闻标题的url
String schoolHref = "http://www.haie.edu.cn/";
//因为取出来的新闻url不规范,直接访问不了,需要将其拼接成正常的网页url
String contentHref = schoolHref+href;
//重复第一步的内容,根据URL取Documet类
Document contentDoc = Jsoup.connect(contentHref).get();
//继续观察网页,取出新闻详细页面的文字。
Elements contentElement = contentDoc.getElementsByClass("contentstyle125127");
Elements authorElement = contentDoc.getElementsByClass("authorstyle125127");
String content = contentElement.text();
String author = authorElement.text();
//打印出作者,新闻详细内容
contentPw.println(author);
contentPw.println(content);
contentPw.println("---------------------------");
}
contentPw.close();
注意一下,一些url很可能不是很规范,譬如我爬取的这个页面,新闻列表页去的URL需要在前方加网页的网址,拼接成新闻真正的URL。就是下面的地方:

如果你需要全部代码,下方是全部代码~
package com.zhangsmile.work;
import java.io.File;
import java.io.IOException;
import java.io.PrintWriter;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
public class JsoupDemo {
public static void main(String[] args) {
try {
//通过Jsoup的Connect方法获取document类
Document document = Jsoup.connect("http://www.haie.edu.cn/xyxw.htm").get();
System.out.println(document.title());//控制台打印网页标题
//根据class获取Elements类
Elements titleElement = document.getElementsByClass("c125126");//标题
Elements timeElement = document.getElementsByClass("timestyle125126");//时间
//指定文件名及路径
File file = new File("D:\\Jsoup\\title.txt");
File contentFile = new File("D:\\Jsoup\\content.txt");
if(!file.exists()){
file.createNewFile();
}
if(!contentFile.exists()){
contentFile.createNewFile();
}
//写入本地
PrintWriter pw = new PrintWriter("D:\\Jsoup\\title.txt");
PrintWriter contentPw = new PrintWriter("D:\\Jsoup\\content.txt");
for (int i = 0; i < titleElement.size(); i++) {
pw.println(titleElement.get(i).text());
pw.println(titleElement.get(i).attr("href"));
pw.println(timeElement.get(i).text());
pw.println("---------------------------");
}
pw.close();
for (int i = 0; i < titleElement.size(); i++) {
String href = titleElement.get(i).attr("href");//取出新闻标题的url
String schoolHref = "http://www.haie.edu.cn/";
//因为取出来的新闻url不规范,直接访问不了,需要将其拼接成正常的网页url
String contentHref = schoolHref+href;
//重复第一步的内容,根据URL取Documet类
Document contentDoc = Jsoup.connect(contentHref).get();
//继续观察网页,取出新闻详细页面的文字。
Elements contentElement = contentDoc.getElementsByClass("contentstyle125127");
Elements authorElement = contentDoc.getElementsByClass("authorstyle125127");
String content = contentElement.text();
String author = authorElement.text();
//打印出作者,新闻详细内容
contentPw.println(author);
contentPw.println(content);
contentPw.println("---------------------------");
}
contentPw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
输出结果
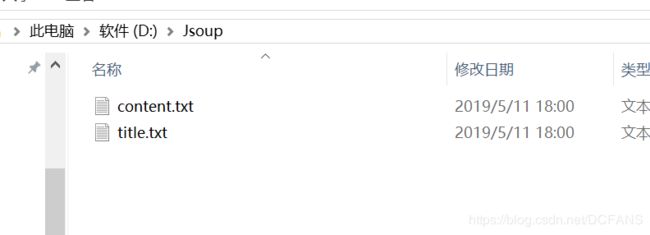


这是很简单的例子,爬下来的数据还可以存到数据库里,我还用了一个很好用的爬虫框架,下一篇再说~