R-CNN: Rich feature hierarchies for accurate object detection and semantic segmentation Tech report
Abstract
Region with CNN = R-CNN
datasets: PASCAL VOC
创新点:
(1) 将大容量的CNN应用于定位和检测任务中
(2) 对于训练数据缺乏时, 监督预训练作为辅助任务, 接着进行特别域的微调
1. Introduction
简述CNN发展
问分类任务中的CNN多大程度可以应用于目标检测?
我们通过缩小图像分类和目标检测之间的差距来回答这个问题。本文首次表明,与基于简单HOG-lile特征的系统相比,cnn在Pascal voc上具有更高的目标检测性能. 为了得到这个结论, 集中在两个问题上: 深度网络定位目标和用少量的带有注释的数据训练一个高容量的模型.
目标检测需要在一张图片中定位很多的目标, 一种方法是作为一个回归问题求解. 但是效果不好. 另一个可替换的方法是滑动窗口检测.
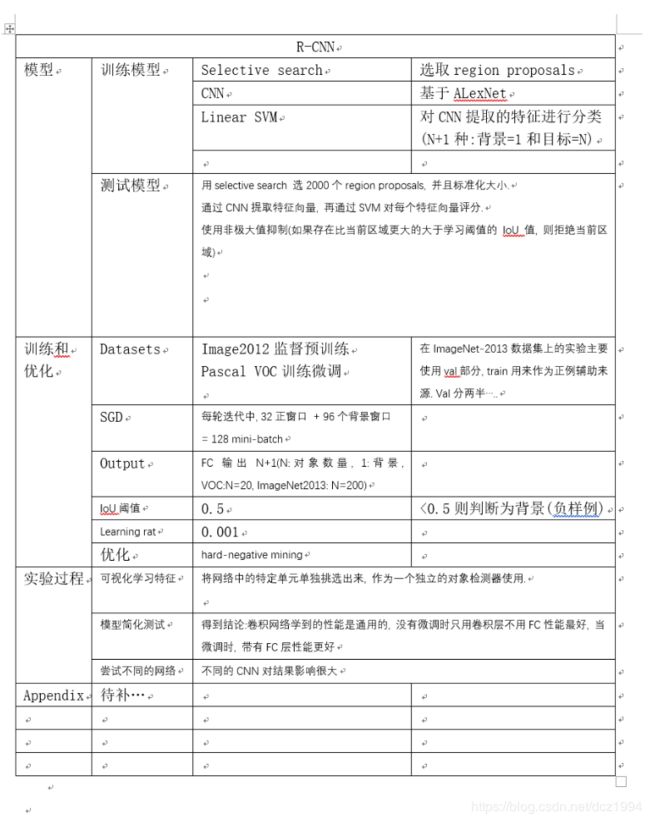
通过"recognition using regions"模型解决了CNN定位问题, 成功的应用于目标检测和语义分割.测试时, (1)在输入图片上提取大约2000个独立的region proposal. (2)CNN对于每一个region proposal提取一个固定长度的特征向量, (3)在每一个区域用SVM分类. 使用单一的方法(affine image warping), 从每一个region proposal中, 计算CNN的固定长度的输入, 不管区域的形状.
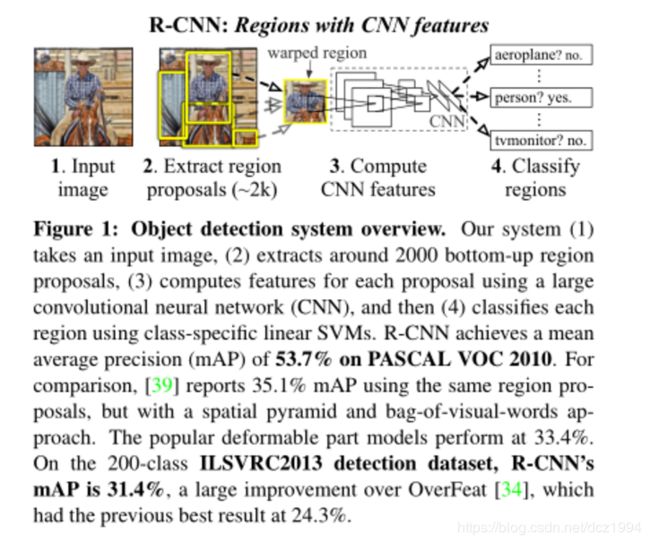
论文的更新版中提供了一个R-CNN和OverFeat端到端的对比, R-CNN在200-class ILSVRC2013 detection datase中的执行精准度超过了OverFeat
另一个问题: 标签数量不足, 当前所获取的总是不足够训练一个大得CNN. 传统的发方法是使用无监督预训练, 然后再使用监督微调. 这篇轮的第二个贡献是在大的辅助数据集(ILSVEC)上运用监督预训练, 然后通过小的数据集(PASCAL)进行domain-specific精调, 实验中, 精调对于检查的改善mAP8%点. 后来在包括场景分类、细粒度子分类和域自适应在内的多个识别任务上获得优异的性能。
系统也非常高效。唯一的特定类计算是合理的矩阵向量积和贪婪的非最大抑制。该计算属性遵循在所有类别之间共享的特征,并且还比先前使用的区域特征低两个数量级.
报告了Hoiem等人的检测分析工具的结果。作为此分析的直接结果,我们证明了一种简单的边界框回归方法可以显着减少错误定位,这是主要的错误模式.
因为R-CNN在regions上操作的技术细节, 所以扩展到了语义分割任务上.
2. Object detection with R-CNN
分类系统由三个大的模型组成,
(1) generates category-independent region proposals.
(2) a large convolutional neural network that extracts a fixed-length feature vector from each region
(3) a set of class specific linear SVMs
2.1. Module design
Region proposals.
各种生成category-independent region proposals的方法:
(1)objectness[1]
(2)selective search[38]
(3)category-independent object proposals [14]
(4)constrained parametric min-cuts (CPMC) [5],
(5)multi-scale combinatorial grouping [3]
(5) detect mitotic cells by applying a CNN to regularly-spaced square crops[6], 这是个特别的proposals提取方法.
虽然R-CNN不知道particular region proposal方法, 但是使用了方法(2)与之前检测工作比较
Feature extraction.
从每个region proposal中使用AlexNet提取了4096维特征, 特征是通过零均值化的227X227RGB图经过5个conv2个FC计算得来的.
为了计算region proposal特征, 先把图region转化成一个CNN可以计算的形式(227X227大小).我们的方法是:不管区域的大小和高宽比, 我们将围绕它的紧密边界框中的所有像素扭曲到所需的大小. 在扭曲之前,我们扩展紧密的边界框,以便在扭曲的尺寸上,在原始框周围有正好p像素的扭曲图像上下文(我们使用p = 16)
2.2. Test-time detection
在测试时, 用方法(2)提取大约2000个region proposal.扭曲每一个region proposal并且通过CNN去计算特征. 然后,对于每个类,我们使用针对该类训练的svm对每个提取的特征向量进行评分。给定图像中的所有得分区域,我们使用贪心非最大抑制(对于每个类别独立)如果这个regiont 存在一个比他更高的(intersection-over-union (IoU)分数且大于学习阈值的区域,则拒绝当前区域。
Run-Time anlysis.
2.3. Training
Supervised pre-training
在数据集ILSVRC2012上预训练, 仅仅使用 image-level annotations(这个数据集没有获取bounding-box labels) 用caffe实现AlexNet来做预训练.
Domain-specific fine-tuning
为了使我们的CNN适应新的任务(检测)和新的域(扭曲的建议窗口),我们仅使用扭曲区域方案,继续对CNN参数进行随机梯度下降(SGD)训练。除了将CNN的ImageNet特定的1000路分类层替换为一个随机的内部化(N+1)路径分类层(其中n是对象类的数量,加上背景1)之外,CNN的体系结构也没有改变。对于VOC, N=20, 对于ILSVRC2013, N=200. 对所有region proposals与真实box有 >=0.5IoU 覆盖在归类于对箱子分类积极, 否则为消极. learning rate = 0.001,允许微调在不破坏初始化的情况下取得进展。在每个SGD迭代中, 我们都对32个正窗口(包括所有类)和96个背景窗口进行统一的采样, 以构造一个大小为128的mini-batch. 我们将采样偏向正窗口, 因为与背景相比, 他们非常罕见.
object category classifiers
考虑训练二进制分类器来检测汽车。很明显,一个紧紧包围汽车的图像区域应该是一个积极的例子。很明显,一个与汽车无关的背景区域应该是一个负面的例子。不太清楚的是如何给部分重叠的区域贴上标签。解决这个问题用IoU覆盖阈值, 如何设置阈值是非常重要的. 阈值=0.5, mAP下降5点. 相似的 阈值=0, mAP下降4点. 正面的例子被简单地定义为每个类的真实的包围盒。
一旦提取了特征并使用了训练标签,我们就会对每类的线性svm进行优化。由于训练数据太大,无法适应内存,所以采用了标准的 hard negative mining method。hard negative mining method快速收敛,在实践中,地图在所有图像上只经过一次就停止增长。我们讨论了为什么在微调和svm训练中,正负两个例子的定义是不同的。
In Appendix B 我们还讨论了在训练检测svms中所涉及的权衡,而不是简单地使用最后的微调cnn的Softmax层的输出。
2.4. Results on PASCAL VOC 2010-12
遵循Pascal voc最佳实践[15],我们验证了voc 2007数据库上的所有设计决策和超参数。对于voc 2010-12数据集的最终结果,我们对voc 2012训练上的cnn进行了微调,并在voc 2012 trainval上优化了我们的检测svms。我们只向评估服务器提交了一次两种主要算法变体(有和不带边界框回归)的测试结果.

表1显示了2010年VOC的完整结果。我们将我们的方法与四个强基线进行对比。包括SefDpm. which合并DPM检测器和语义分割系统的输出. 并且用附加的传统分类器上下文和图片分类器恢复.
最相关的比较是Uijings等人的UVA系统。[39],由于我们的系统使用相同的region proposal算法。为了对区域进行分类,他们的方法构建了一个四层空间金字塔,并用密集采样的SIFT、扩展的OpponentSIFT和rGBSIFT描述符填充它,每个矢量用4000字码本量化。分类使用直方图交叉核svm执行。对比多重特征,非线核SVM, 我们获取一个大的改进在mAP, 而且也变得更快. 获取一个相似的性能在VOC2011/12test.
2.5. Results on ILSVRC2013 detection
和使用VOC中的参数一样, 把R-CNN运行在ILSVRC-2013上面. 也仅仅提交两次结果, 一次有边界框一次没有边界框.
为了给出AP在类中分布的意义,还提出了方框图,并在表8的最后给出了每类AP的表。大多数相互竞争的提交材料(OverFeat、NEC-MU、UvAEuvision、TorontoA和UIUC-IFP)使用卷积神经网络,表明CNN在如何应用于目标检测方面存在重大差别,导致结果大不相同。
在第四节中,我们概述了ILSVRC 2013检测数据集,并详细介绍了我们在其上运行R-CNN时所做的选择。
3. Visualization, ablation, and modes of error
3.1. Visualizing learned features
第一层滤波器可以直接视觉化并且容易理解. 它捕获原图的边际和对立的颜色. 理解接下来的层则更有挑战.泽勒和费格斯在[42]中提出了一种视觉上的反卷积方法。我们提出了一种简单的(互补的)非参数方法,它直接显示了网络学到的东西。
其思想是将网络中的一个特定单元(特性)单独挑选出来,并将其作为一个独立的对象检测器来使用. 也就是说,我们计算单位在大量保留region proposal(大约1000万)上的激活,从最高到最低激活对提案进行排序,执行非最大抑制,然后显示得分最高的区域。我们的方法通过准确显示它所触发的输入,让所选单元“说出自己”。 我们避免求平均值以便查看不同的视觉模式并深入了解由单元计算的不变性。
我们从layer pool 5中可视化单元,这是网络的第五个也是最后一个卷积层的最大集合输出。The pool5 特征映射是6X6X256=9216维. 忽略边界影响, 每一个pool5单元有一个195X195的滤波器在原始227X227像素的输入中. 一个central pool 5单元几乎有一个全局视图,而在边缘附近的一个单元有一个更小的,剪裁的支持。

图4中的每一行显示了我们根据VOC 2007 trainval进行微调的CNN池5单元的前16次激活。256个功能独特单元中的六个可视化(附录D包括更多)。选择这些单元以显示网络学习的代表性样本。在第二行中,我们看到一个在狗脸和点阵列上发射的单位。 对应于第三行的单元是红色斑点检测器. 还有人脸探测器和更抽象的图案,如文字和带窗户的三角形结构。该网络似乎学习了一种表示,该表示将少量的类调整特征与形状,纹理,颜色和材料属性的分布式表示相结合。随后的完全连接层fc 6具有对这些丰富特征的大量组合进行建模的能力。
3.2. Ablation studies
Performance layer-by-layer, without fine-tuning
为了理解哪一个层对于检测性能至关重要的, 分类VOC 2007数据集上的结果对于每一个CNN的最后三层. Pool5如3.1所描述. 最后两层总结如下:
fc6是对pool5的全连接, 为了计算特征, 它用一个4096X9216的矩阵XPool5, 然后增加一个特征偏置. 最后用ReLu调整(x←max(0,x).
Fc7是4096X4096 Fc6. 相似的增加偏置和应用half-wave调整
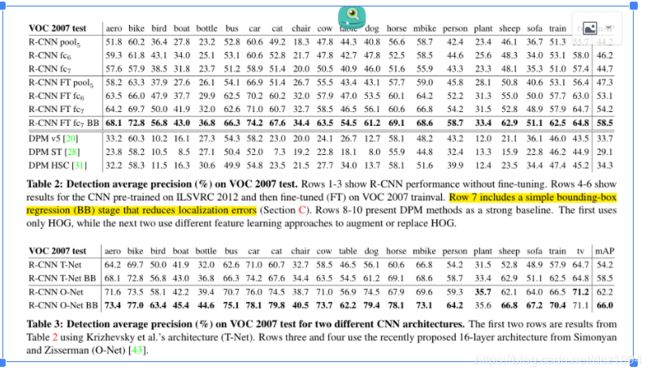
我们首先看看CNN的结果,没有微调对PASCAL,所有的CNN参数仅仅在ILSVRC 2012上预训练。逐层分析性能(表2行1-3)显示,FC 7的特性比FC 6的特性概括得更差。这意味着CNN参数的29%(约1680万)可以在不降低地图质量的情况下被删除。更令人惊讶的是,删除FC 7和FC 6会产生相当好的效果,即使只使用CNN参数的6%计算pool5特征。CNN的代表性力量很大程度上来自于它的卷积层,而不是大得多的密集连接层。这一发现为仅使用cnn的卷积层计算任意大小图像的密集特征图提供了潜在的实用价值。这种表示方式将允许在池5功能之上进行滑动窗口测试器(包括dpm)的实验。
Performance layer-by-layer, with fine-tuning.
性能的提升更多的来自于微调fc6,7比pool5, 这意味着pool5从ImageNet中学到的特性是通用的,并且大部分改进都是从学习领域特定的非线性分类器中获得的。
Comparison to recent feature learning methods.
我们看了两种最近建立在可变形区域模型上的方法。为了参考, 也包括标准的HOG-based DPM的结果.
第一个DPM特征学习方法 DPM ST, 用sketch token概率扩张HOG特征. 直觉上, 一个sketch token是通过图像块中心的轮廓的紧密分布。 通过随机森林在每个像素处计算sketch token概率,该森林经过训练以将35×35像素斑块分类为150个sketch token或背景之一。
方法二是DPM HSC, sparse codes直方图(HSC)取代HOG. 为了计算HSC, 使用100×7×7像素(灰度)原子的学习字典在每个像素处求解稀疏码激活。激活结果调整通过三种方式(full and both half-waves), 空间池化, L2正则化 和 转换

所有R-CNN变体性能超出三个DPM baselines, 包括两个用特征学习. 相比于 仅仅使用HOG最新的DPM版本, 我们mAP是超过20%于他们. HOG和“sketch tokens”的组合比单独的HOG产生2.5 mAP点,而HSC比HOG提高了4 mAP点(当在内部与其私有DPM基线进行比较时 - 两者都使用了执行开源版本的DPM的非公开实现[20])。这些方法分别实现了29.1%和34.3%的mAP。
3.3. Network architecture
这篇论文中大量的结果使用的网络结构是AlexNet. 然后, 我们发现不同结构的选择对R-CNN的决策有很大的影响. 在表3中我们展示了杂VOC 20007test 使用VGG的结果. The network has a homogeneous structure consisting of 13 layers of 3 × 3 convolution kernels, with five max pooling layers interspersed, and topped with three fully-connected layers. We refer to this network as “O-Net” for OxfordNet and the baseline as “T-Net” for TorontoNet.
为了在R-CNN中使用O-Net, 先吓着了预训练的VGG模型(caffe写的), 用和调节T-Net一样的方法调节O-Net, 只不过由于GPU内存的限制, minibatch选择24, 表3展示了用O-Net的R-CNN执行能力比Y-Net的要优越. 然后计算时间也是需要考虑的, o-net的正向通过的时间比T-net长7倍.
3.4. Detection error analysis
我们应用了Hoiem等人的优秀检测分析工具。 [23]为了揭示我们方法的错误模式,了解微调如何改变它们,以及了解我们的错误类型与DPM的比较。分析工具的完整摘要超出了本文的范围,我们鼓励读者参考[23]以了解一些更精细的细节(例如“规范化AP”)。由于分析最好在相关图的背景下被吸收,因此我们在图5和图6的标题中进行讨论。
3.6. Qialitative results
ILSVRC2013的定性检测结果如本文末尾的图8和图9所示。从val 2组中随机采样每个图像,并且显示来自所有检测器的所有检测,精度大于0.5。请注意,这些都不是策划的,并给出了实际的探测器的实际印象. 更多定性结果如图10和图11所示,但这些结果已经过策划。我们选择了每张图片,因为它包含有趣,令人惊讶或有趣的结果。此外,还显示了精度大于0.5的所有检测。
4. The ILSVRC2013 detection dataset
4.1. Dataset overview
ILSVRC2013检测数据集分为三组:train(395,918),val(20,121)和test(40,152).val和test分割是从相同的图像分布中提取的。这些图像是类似场景的,并且与PASCALVOC图像的复杂性(对象数量,杂波量,姿势可变性等)相似。val和test拆分被详尽地注释,这意味着在每个图像中,来自所有200个类的所有实例都用边界框标记。相反,训练来自ILSVRC2013分类图像分布。这些图像具有更多变化的复杂性,并且偏向于单个中心对象的图像。与val和test不同,train图像(由于它们的数量很大)没有被详尽地注释。在任何给定的trian图像中,来自200个类的实例可以标记或不标记。除了这些图像集之外,每个类还有一组额外的负像. 手动检查负图像以验证它们不包含其关联类的任何实例。在这项工作中没有使用负片图像集。在这项工作中没有使用负片图像集。
这些分裂的性质为训练R-CNN提供了许多选择。train图像不能用于hard-negative mining,因为注释并非详尽无遗。负面例子应该从哪里来?此外,train图像具有与val和测试不同的统计数据。是否应该使用train图像,如果使用,在何种程度上?虽然我们还没有彻底评估大量的选择,但我们根据之前的经验提出了看似最明显的路径。
我们的总体策略是严重依赖val集并使用一些train图像作为正例的辅助来源。要使用val进行训练和验证,我们将其分成大致相同大小的“val 1”和“val 2”集。由于某些类在val中的示例非常少(最小的只有31而一半只有少于110),因此生成近似类平衡的分区非常重要。为此,生成了大量候选分割,并选择了具有最小最大相对类不平衡的分割. 每个候选分割是通过使用类别计数作为特征聚类val图像,然后是可以改善分割平衡的随机本地搜索来生成的。这里使用的特定分裂具有约11%的最大相对不平衡和4%的中值相对不平衡。val 1 / val 2分割和用于生成它们的代码将公开提供,以允许其他研究人员比较他们在本报告中使用的val分裂的方法.
4.2. Region proposals
使用相似的region proposal方法检测PASCAL. Selective search[39]在val 1,val 2和test中的每个图像上以“快速模式”运行. 一个小的调整是需要处理selective search不是一个尺度不变的事实, 所以regions生成的数量以来与图片分辨率. ILSVRC图片大小范围从很小到很大, 所以我们在执行selective search之前调整每个图像到固定的大小(500宽度). 在val上, selective search在一个每张图片平均2403region proposals上得到结果, 所有真实边界框为91.6%recall(0.5个阈值), 这个recall比在PASCAL上显著低的, 接近98%, 在region proposals阶段有很大的改进空间。
4.3. Training data
对于训练数据, 规范化一个图片和boxs集合that包含来自val1的全部selective search和真实boxes, 并且train中每个类别最多N个真实boxes(如果一个类的训练中的真实boxs少于n个,那么我们就把它们全部取出来). 称这个datasets为图片和boxes val1+trainN. 在一个模型简化测试中, 我们展示了mAP 在val2 for N属于(0, 500, 1000).
在R-CNN中, 训练数据需要3个预处理:(1) CNN 微调. (2) SVM训练. (3). 边界框回归训练. CNN微调是在val1+trainN上提取像之前用在PASCAL上一样的setting进行50KSGD迭代. 对于SVM训练, val1+trainN的所有真实边界框用作对他们接受域的正样例. Hard negative mining是对Val 1中5000幅图像的随机选择子集进行的. 经验指示mining negative全部来自val1. 最初的一项实验表明,从所有val1中挖掘负数而不是5000个图像子集(大约一半),导致mAP仅下降0.5个百分点,同时将SVM训练时间缩短一半。没有从train中采用负样例是因为没有彻底的解释. 已经核实的负面图片的额外结合是没有使用的. 边界框回归是在val1上训练的.
4.4. Validation and evaluation
在对于评估提交结果之前, 我们使用上面描述的训练数据验证了数据使用的选择以及微调和包围盒回归对vall 2集的影响.所有系统超参数(例如,SVM C超参数,区域扭曲中使用的填充,NMS阈值,边界框回归超参数)被固定在用于PASCAL的相同值处。毫无疑问,这些超参数选择中的一些对于ILSVRC来说略微不理想,但是这项工作的目的是在没有大量数据集调整的情况下在ILSVRC上产生初步的R-CNN结果。在val 2上选择最佳选择后,我们将两个结果文件提交给ILSVRC2013评估服务器。第一次提交没有边界框回归,第二次提交是边界框回归。对于这些提交,我们扩展了SVM和边界框回归训练集,分别使用val + train 1k和val。我们使用了在val 1 + train 1k上进行微调的CNN,以避免重新运行微调和特征计算。
4.5. Ablation study
表4显示了不同量训练数据,微调和边界框回归效果的消融研究。第一个观察结果是,val 2上的mAP与测试中的mAP非常接近。这让我们相信,val 2上的mAP是测试集性能的良好指标。第一个结果,20.9%,是R-CNN使用在ILSVRC2012分类数据集上预训练的CNN(无微调)实现的,并且可以访问val 1中的少量训练数据(回想一下val中的一半类1有15到55个例子)。将训练集扩展到val 1 + train N可将性能提高到24.1%,N = 500和N = 1000之间基本没有差异。使用来自val 1的示例微调CNN给出了适度的改进,达到26.5%,但是由于少量的正训练示例,可能存在显着的过度拟合。将微调集扩展到val 1 + train 1k,从列车组中每班增加1000个正例,有助于显着提高mAP至29.7%。边界框回归将结果改善至31.0%,这是在PASCAL中观察到的较小的相对增益
4.6. Relationship to OverFeat
R-CNN和OverFeat之间有一个有趣的关系, OverFeat可以看做是R-NN的一个特别版本. 如果用常规方形区域的多尺度金字塔替换selective search region proposal, 并将每类边界框回归量更改为当个边界框回归量, 那么系统非常相似. 值得醉意的是OverFeat比R-CNN有一个速度优势: 大约9倍, 基于[34]引用的每张图像2秒的数字。该速度来自OverFeat的滑动窗口(即,区域提议)在图像级别没有扭曲的事实,因此可以在重叠窗口之间容易地共享计算。通过在任意大小的输入上以卷积方式运行整个网络来实现共享。
5. Semantic segmentation
区域分类是一个语义分割的基础技术, R-CNN对于PASCAL-VOC语义分割挑战如下. 为了和当前语义分割系统 (called O2P for “second-order pooling”)有一个直接的对比, 我们在他们的开源框架中工作. O2P使用CPMC去生成150region proposals每个图像, 并且预测每个region的质量, 对于每一个类,使用SVR(support vector regression). 他们的优势在于CPMC regions的质量和功能强大的多个特性类型的二阶池。我们也注意到Farabel团队最近通过作为多尺度每个像素的分类器的CNN, 在多个dense scene labeling数据集上得到了好的结果.
我们遵循[2,4]并扩展PASCAL分段训练集以包括Hariharan等人提供的额外注释。[22]。设计决策和超参数在VOC 2011验证集上进行了交叉验证。最终测试结果仅评估一次。
CNN features for segmentation.
我们评估了三种在CPMC区域上计算特征的策略,所有这些策略都是通过将区域周围的矩形窗口扭曲到227×227来开始的。第一个策略(完整)忽略了区域的形状,并直接在扭曲的窗口上计算CNN特征,就像我们检测的那样。但是,这些功能会忽略该区域的非矩形形状。两个区域可能具有非常相似的边界框,同时具有非常小的重叠。因此,第二个策略(fg)仅在区域的前景掩码上计算CNN特征
我们用平均输入替换背景,以便在平均牵引后背景区域为零。第三种策略(full+ fg)简单地连接完整和fg功能;我们的实验验证了它们的互补性.

Results on VOC 2011.
表5显示了我们在VOC 2011验证集上与O 2 P相比的结果摘要(有关完整的每类别结果,请参阅附录E.)在每个特征计算策略中,层fc 6总是优于fc 7,并且以下讨论涉及fc 6特征。fg策略稍微优于完整,表明屏蔽区域形状提供了更强的信号,与我们的直觉相匹配。然而,full + fg实现了47.9%的平均准确度,我们的最佳结果是4.2%的边缘(也略微优于O 2 P),表明即使给出fg特征,完整特征提供的上下文也是高度信息的。值得注意的是,在我们的full+fg功能上训练20个SVR在单个核心上花费一个小时,而在O 2 P功能上训练需要10个小时。
在表6中,我们提供了VOC 2011测试集的结果,将我们表现最佳的方法fc 6(full+ fg)与两个强基线进行比较。我们的方法对21个类别中的11个进行了最高的分割准确度,并且最高的整体分割准确率为47.9%,在各类别之间取平均值(但可能与任何合理误差范围内的O 2 P结果相关)。

6. Conclusion
近年来,物体检测性能停滞不前。表现最佳的系统是复杂的集合,将多个低级图像特征与来自物体探测器和场景分类的高级环境相结合。本文介绍了一种简单且可扩展的物体检测算法,与PASCAL VOC 2012上的最佳结果相比,可提供30%的相对改进。
我们通过两个见解实现了这一表现。第一种方法是将高容量卷积神经网络应用于自下而上的区域提议,以便对对象进行本地化和分割。第二个是在标记的训练数据稀缺时训练大型CNN的范例。我们表明,对于具有丰富数据(图像分类)的辅助任务,通过监督对网络进行预训练是非常有效的,然后针对数据稀缺(检测)的目标任务微调网络。我们推测,“监督的预训练/领域特定微调”范例对于各种数据稀缺的视觉问题将非常有效。
最后,我们指出通过结合使用计算机视觉和深度学习(自下而上区域提议和卷积神经网络)的经典工具来实现这些结果是很重要的。这两者不是反对科学探究的对象,而是自然而不可避免的合作伙伴。