hash table
1. 概述
A hash table consists of an array of ‘buckets’(吊桶), each of which stores a key-value pair. In order to locate the bucket where a key-value pair should be stored, the key is passed through a hashing function. This function returns an integer which is used as the pair’s index in the array of buckets. When we want to retrieve a key-value pair, we supply the key to the same hashing function, receive its index, and use the index to find it in the array. Array indexing has algorithmic complexity O(1), making hash tables fast at storing and retrieving data.
The hash function we choose should:
- Take a string as its input and return a number between 0 and m, our desired bucket array length.
- Return an even distribution of (平均分配)bucket indexes for an average set of inputs. If our hash function is unevenly distributed, it will put more items in some buckets than others. This will lead to a higher rate of collisions(冲突,碰撞) . Collisions reduce the efficiency of our hash table.
Hash functions map an infinitely(无限的) large number of inputs to a finite number of outputs
来自 https://github.com/jamesroutley/write-a-hash-table/tree/master/01-introduction
hash表的内部过程是将一个string类型的key映射得到一个(数组的)index,这个index内容放什么是自定义的(value)。
2. hash表实现的map和红黑树(or skiplist)实现的map
- hash表实现map查找插入删除几乎常数时间,效率极高,但占用内存一般高于实际存储的节点个数(不然冲突问题可能影响到效率),内部无序(因此无法范围查找)
- 红黑树实现map查找插入删除O(lgN)时间,和hash没法比.但占用内存少(=节点个数),内部有序(可按key排序),灵活(找不到exact key时甚至可以找一个最接近的)
- skiplist实现map效率上和红黑树相同,但查找插入删除实现都比红黑树简单,且空间占用在1/4等比递减的时候比红黑树有优势
一般而言,有序集合都是按key排序,若按插入顺序排序就简单了,再维护一个list即可
3. 一个存在问题的hash table实现
hashtable.h
#ifndef __HASH_TABLE_H
#define __HASH_TABLE_H
#define HT_PRIME_1 151
#define HT_PRIME_2 153
#define HT_INITIAL_BASE_SIZE 100
typedef struct
{
char* key;
void* value;
} ht_item;
typedef struct
{
int base_size;
int size; //size 和 count决定要不要resize hash表的大小,hash表太满不仅导致
int count; //无法插入数据,还会使插入效率大大降低!因此动态调整hash表大小是必要的
ht_item** items;
} ht_hash_table;
ht_hash_table *ht_new();
void ht_del_hash_table(ht_hash_table* ht);
void *ht_insert(ht_hash_table *ht, const char *key, void *value);
void *ht_search(ht_hash_table* ht, const char* key);
void ht_delete(ht_hash_table* ht, const char* key);
//void ht_show(ht_hash_table *ht);
void ht_map(ht_hash_table *ht,void apply(const char *key,void **value,void *cl),void *cl);
#endifhashtable.c
#include
#include
#include
#include
#include
#include "hashTable.h"
//这是要判断x是不是质数
static int is_prime(const int x)
{
int i;
if (x < 2)
return -1;
if (x < 4)
return 1;
if ((x % 2) == 0)
return 0;
for (i = 3; i <= floor(sqrt((double) x)); i += 2)
{
if ((x % i) == 0)
return 0;
}
return 1;
}
//寻找一个 >=x 的质数
static int next_prime(int x)
{
while (is_prime(x) != 1)
{
x++;
}
return x;
}
static ht_item HT_DELETED_ITEM = {NULL, NULL}; //所有被delete的item都指向这货啊
static ht_item *ht_new_item(const char *k, void *v)
{
ht_item *i = malloc(sizeof(ht_item));
if(i)
{
i->key = strdup(k); //strdup = malloc and memcpy
i->value = v;
}
return i;
}
static void ht_del_item(ht_item *i)
{
if(i)
{
if(i->key)
free(i->key);
free(i);
}
}
//哈希函数,a为给定的一个随机值吧
//s is key, a is a number(给的是个 prime), m is hash table size
static int ht_hash(const char *s, const int a, const int m)
{
long hash = 0; //index
int i;
const int len_s = strlen(s);
for (i = 0; i < len_s; i++)
{
//if strlen = 3, then s[0]*a^2 + s[1]*a^1 +s[2]*1; s[i] is ASCII value
hash += (long)pow(a, len_s - (i+1)) * s[i];
//refuce to hash tabel size scope
hash = hash % m;
}
return (int)hash;
}
//如果hash遇到冲突,将double hash, attempt 代表发生冲突的次数(初次为0其实就是hash_a)
static int ht_get_hash(const char *s, const int num_buckets, const int attempt)
{
const int hash_a = ht_hash(s, HT_PRIME_1, num_buckets);
const int hash_b = ht_hash(s, HT_PRIME_2, num_buckets);
return (hash_a + (attempt * (hash_b + 1))) % num_buckets; //加1是为了防止hash得到0且冲突的case
}
//新分配一个hash table,大小为 >=base_size 的一个质数
static ht_hash_table *ht_new_sized(const int base_size)
{
//ht_hash_table* ht = xmalloc(sizeof(ht_hash_table)); //xmalloc与malloc几乎一样,多了写log的功能
ht_hash_table *ht = (ht_hash_table *)malloc(sizeof(ht_hash_table)); //xmalloc与malloc几乎一样,多了写log的功能
if(!ht)
goto FAIL;
ht->base_size = base_size;
ht->size = next_prime(ht->base_size);
ht->count = 0;
ht->items = calloc((size_t)ht->size, sizeof(ht_item*));
if(!ht->items)
goto FAIL;
return ht;
FAIL:
if(ht)
free(ht);
return NULL;
}
//现在要resize,以新的 base_size
static void ht_resize(ht_hash_table *ht, const int base_size)
{
int i;
if (base_size < HT_INITIAL_BASE_SIZE) //hash 表维护了一个最小的size
return;
ht_hash_table *new_ht = ht_new_sized(base_size);
if(!new_ht)
return;
//将 hash table 原有内容挨个拷贝(插入)到新 table 的 桶 里面
for (i = 0; i < ht->size; i++)
{
ht_item* item = ht->items[i];
if (item != NULL && item != &HT_DELETED_ITEM)
{
ht_insert(new_ht, item->key, item->value);
}
}
ht->base_size = new_ht->base_size;
ht->count = new_ht->count;
//吧 new_ht 和 ht 的 size 交换,(旧 size 在一会释放的时候还有用所以不能丢)
const int tmp_size = ht->size;
ht->size = new_ht->size;
new_ht->size = tmp_size;
//吧 new_ht 和 ht 的 tmp_items 指针交换(然后就相当于原来的ht换到了大空间了)
ht_item** tmp_items = ht->items;
ht->items = new_ht->items;
new_ht->items = tmp_items;
//new_ht 隐退,深藏功与名
ht_del_hash_table(new_ht);
}
//此函数也只是作为 insert 时候可能使用的一个util
static void ht_resize_up(ht_hash_table *ht)
{
const int new_size = ht->base_size * 2;
ht_resize(ht, new_size);
}
//此函数也只是作为 delete 时候可能使用的一个util
static void ht_resize_down(ht_hash_table *ht)
{
const int new_size = ht->base_size / 2;
ht_resize(ht, new_size);
}
void *ht_insert(ht_hash_table *ht, const char *key, void *value)
{
void *oldvalue = NULL;
const int load = ht->count * 100 / ht->size;
if (load > 70) //>0.7 就 resize hash table
{
ht_resize_up(ht);
}
ht_item *item = ht_new_item(key, value);
if(!item)
return NULL;
int index = ht_get_hash(item->key, ht->size, 0);
ht_item *cur_item = ht->items[index];
int i = 1;
while (cur_item != NULL && cur_item != &HT_DELETED_ITEM) //这个坑已经被占了,说明发生了冲突
{
if (strcmp(cur_item->key, key) == 0) //插入相同的key被视为更新
{
oldvalue = cur_item->value;
ht_del_item(cur_item); //
ht->items[index] = item; //
return oldvalue; //如果发现返回值 非 NULL,应该立刻执行对 value 的释放操作!不然刚刚的覆盖会引起内存泄漏
}
index = ht_get_hash(item->key, ht->size, i);
cur_item = ht->items[index];
i++;
}
//走到这里说明终于找到了一个新的坑
ht->items[index] = item;
ht->count++;
return NULL;
}
void *ht_search(ht_hash_table *ht, const char *key)
{
int index = ht_get_hash(key, ht->size, 0); //首次hash拿到的index
ht_item* item = ht->items[index];
int i = 1;
while (item != NULL && item != &HT_DELETED_ITEM)
{
if (strcmp(item->key, key) == 0)
{
return item->value; //找到了,成功返回
}
index = ht_get_hash(key, ht->size, i); //没找到,那么看是否因为hash冲突被安排到了下个hash index处
item = ht->items[index];
i++;
}
return NULL;
}
//如果key-value对不在hash表中,则本函数啥也不做
void ht_delete(ht_hash_table *ht, const char *key)
{
const int load = ht->count * 100 / ht->size;
if (load < 10) //<0.1 就 resize hash table
{
ht_resize_down(ht);
}
int index = ht_get_hash(key, ht->size, 0);
ht_item* item = ht->items[index];
int i = 1;
//item本身并不会从数组中被删除(不然会影响冲突链的查找),而是指向 HT_DELETED_ITEM 即表示删除了
while (item != NULL) //这里 item==&HT_DELETED_ITEM 也应该是允许的,因为被删除的元素在 冲突链 上位置并不确定
{
if(item != &HT_DELETED_ITEM)
{
if (strcmp(item->key, key) == 0)
{
ht_del_item(item);
ht->items[index] = &HT_DELETED_ITEM; //成功删除
ht->count--;
return;
}
}
index = ht_get_hash(key, ht->size, i);
item = ht->items[index];
i++;
}
}
ht_hash_table *ht_new()
{
return ht_new_sized(HT_INITIAL_BASE_SIZE);
}
void ht_del_hash_table(ht_hash_table *ht)
{
int i = 0;
for (i = 0; i < ht->size; i++)
{
ht_item* item = ht->items[i];
if (item != NULL && item != &HT_DELETED_ITEM) //
{
ht_del_item(item);
}
}
free(ht->items);
free(ht);
}
void ht_map(ht_hash_table *ht,void apply(const char *key,void **value,void *cl),void *cl)
{
int i = 0;
for (i = 0; i < ht->size; i++)
{
ht_item* item = ht->items[i];
if (item != NULL && item != &HT_DELETED_ITEM)
{
//printf("%d (%s,%p)\n",i,item->key,item->value);
apply(item->key,&item->value,cl);
}
}
} 测试这个hash表的时候发现hash函数对插入key为有规律的string的时候性能并不好。hash表还有另一种实现是开链法,将冲突的element链成一个list。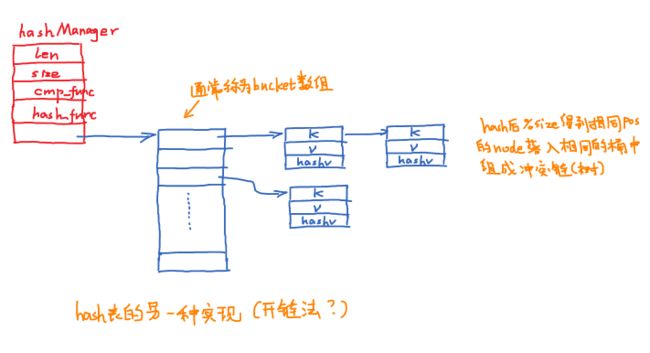
hash表的关键点:
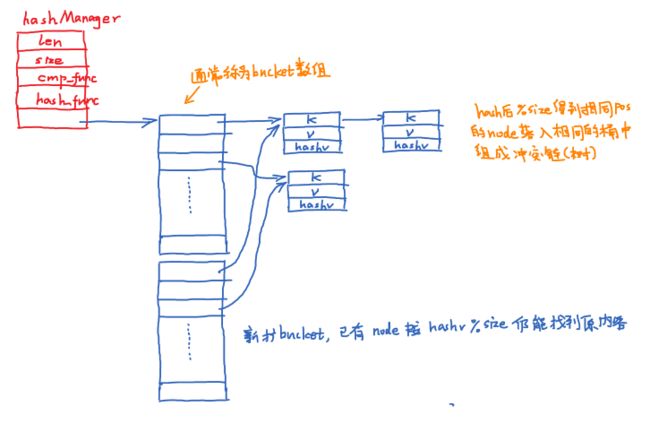
- 为了使hash取得较好的效率一般都是动态伸缩 hash表 bucket的size,即当 insert 导致size 超过某个阈值则需resize(不然冲突链过长会导致hash性能下降)。如何resize?简单粗暴的采取”再新建一个bucket表–>将原表中所有node挨个重新插入到新表中” 会出现问题:数据量巨大时,某一次节点插入耗时将很长! 一致性hash?貌似实现起来有点复杂。《redis设计与实现》提到 redis 采用两张 bucket(主bucket0,副bucket1),当需要rehash时 每次插入、删除、查找会顺带将一些主bucket0中的元素rehash 到 bucket1,同时hash manager结构体会记录主bucket0 rehash到哪个index了,总会有全部rehash完毕的时候嘛,那时候再释放bucket0,并将 bucket1–>bucket0。
- hash表数据类型的安全。k一定是string吗?hash表是将 XXX 杂糅成 hash_index,XXX 可不一定是 string。v同样可以是某个基本类型或指向某个复杂struct的指针。处理不好会crash或者内存泄漏。redis要求提供keyDup、valDup、keyDestruct、valDestruct等函数。可以很好解决这个问题。
- hash函数的选择。上面的hash表实现之所以性能出现问题和我的测试用例密不可分。我在插入数据的时候都是一些有规律的string,比如key_0, key_1, …..直接导致其冲突链表过长。redis采用的murmurhash函数,貌似这个函数被很多开源代码采用,对有规律的key表现出色。当然这个murmurhash只是最好是一个default hash函数,可以替换的。
所以我借鉴redis的思想自己实现hash表。目前测试起来性能还可以,后面有bug再修吧
目前发现一个问题:缺少一个接口:对hash表中原有(k,v)对进行 v++ 或者 v– 的操作
4. 参考redis的hash table实现
hashtable.h
#ifndef __HASH_TABLE_H
#define __HASH_TABLE_H
typedef struct htItem
{
struct htItem *next;
void *key;
void *val;
unsigned int hashVal;
} htItem;
typedef struct
{
unsigned int (*hashFunc)(const void *key); //hash 函数
int (*keyCmp)(const void *p1,const void *p2); //key 比较函数
void *(*keyDup)(const void *key); //key 复制函数
void *(*valDup)(const void *val); //val 复制函数
void (*keyDestructor)(void *key); //key 销毁
void (*valDestructor)(void *val); //val 销毁
unsigned int count;
unsigned int size0; //size = 2^i
unsigned int size1; //size = 2^i
htItem** tb0;
htItem** tb1;
int rehash_index; //非-1表示正在做rehash
} htManager;
typedef struct
{
void *key;
void *val;
} pair;
htManager *htCreate(unsigned int baseSize,
unsigned int (*hashFunc)(const void *key),
int (*keyCmp)(const void *p1,const void *p2),
void *(*keyDup)(const void *key),
void *(*valDup)(const void *val),
void (*keyDestructor)(void *key),
void (*valDestructor)(void *val));
int htInsert(htManager *pht,const void *key,const void *val,void **oldVal);
int htDelete(htManager *pht,const void *key,void **pVal);
int htSearch(htManager *pht,const void *key,void **pVal);
int htToPairArray(htManager *pht,pair **pairArray,int pairCmp(const void *p1,const void *p2));
void htDestroy(htManager *pht);
void debugHt(htManager *pht);
#endifhashtable.c
//rehash_index 表示 rehash到的index,为-1表示没有在做rehash或者rehash完成
//当正在rehash的时候,搜索、插入、删除需要tb0和tb1都要查看,
//当rehash_index>=tb0.size的时候表示rehash已经完成,此时应该
//释放tb0,使用tb1代替tb0,并 rehash_index=-1
#include
#include
#include
#include
#include
#include "hashTable.h"
//size is at least 2^HT_BASE_SIZE
#define HT_BASE_SIZE 5
static unsigned int murMurHash(const void *key,unsigned int len)
{
const unsigned int m = 0x5bd1e995;
const int r = 24;
const int seed = 97;
unsigned int h = seed ^ len;
// Mix 4 bytes at a time into the hash
const unsigned char *data = (const unsigned char *)key;
while(len >= 4)
{
unsigned int k = *(unsigned int *)data;
k *= m;
k ^= k >> r;
k *= m;
h *= m;
h ^= k;
data += 4;
len -= 4;
}
// Handle the last few bytes of the input array
switch(len)
{
case 3: h ^= data[2] << 16;
case 2: h ^= data[1] << 8;
case 1: h ^= data[0];
h *= m;
}
// Do a few final mixes of the hash to ensure the last few
// bytes are well-incorporated.
h ^= h >> 13;
h *= m;
h ^= h >> 15;
return h;
}
static unsigned int hashFuncDefault(const void *key)
{
unsigned int len = strlen((const char *)key);
return murMurHash(key,len);
}
static int keyCmpDefault(const void *p1,const void *p2)
{
//return ((unsigned int)p1 - (unsigned int)p2); //默认是按照 key 指针值排序(即key的地址值)
return strcmp((const char *)p1,(const char *)p2);
}
static void *keyDupDefault(const void *key)
{
unsigned int len = strlen((const char *)key);
char *p = (char *)malloc(len+1);
if(p)
{
memset(p,0,len+1);
memcpy(p,key,len);
}
return (void *)p;
}
static void *valDupDefault(const void *val)
{
return (void *)val;
}
static void keyDestructorDefault(void *key)
{
if(key)
free(key);
}
static void valDestructorDefault(void *val)
{
val = val; //just tell compiler not to report warning
}
static htItem *pickHeadFromCollisionList(htItem **bucketTbl,unsigned int index)
{
htItem **ppHead = &bucketTbl[index];
htItem *pCurItem = *ppHead;
if(pCurItem)
*ppHead = pCurItem->next;
return pCurItem;
}
static void linkToHeadOfCollisionList(htItem **bucketTbl,unsigned int index,htItem *pitem)
{
htItem **ppHead = &bucketTbl[index];
pitem->next = *ppHead;
*ppHead = pitem;
}
static void rehashOnTheGo(htManager *pht,unsigned int tryCnt)
{
//increase rehash index on the go.
unsigned int rehashElemCnt = 0;
htItem *pCurItem = NULL;
if(pht->rehash_index < 0 || pht->rehash_index >= pht->size0)
return;
while((pht->rehash_index < pht->size0) && rehashElemCnttb0[pht->rehash_index])
{
//rehash this collision list
while((pCurItem = pickHeadFromCollisionList(pht->tb0,pht->rehash_index)) != NULL)
{
linkToHeadOfCollisionList(pht->tb1,(pCurItem->hashVal) & (pht->size1 - 1),pCurItem);
rehashElemCnt++;
}
pht->rehash_index++;
}
else
{
pht->rehash_index++;
rehashElemCnt++;
}
}
if(pht->rehash_index >= pht->size0) //means rehash has completed!
{
//destroy tb0 and tb1->tb0
free(pht->tb0);
pht->tb0 = pht->tb1;
pht->size0 = pht->size1;
pht->tb1 = NULL;
pht->size1 = 0;
pht->rehash_index = -1; //
}
return;
}
htManager *htCreate(unsigned int baseSize,
unsigned int (*hashFunc)(const void *key),
int (*keyCmp)(const void *p1,const void *p2),
void *(*keyDup)(const void *key),
void *(*valDup)(const void *val),
void (*keyDestructor)(void *key),
void (*valDestructor)(void *val))
{
unsigned int i = 0;
htManager *pht = (htManager *)malloc(sizeof(htManager));
if(!pht)
goto FAIL_1;
pht->hashFunc = (hashFunc)?hashFunc:hashFuncDefault;
pht->keyCmp = (keyCmp)?keyCmp:keyCmpDefault;
pht->keyDup = (keyDup)?keyDup:keyDupDefault;
pht->valDup = (valDup)?valDup:valDupDefault;
pht->keyDestructor = (keyDestructor)?keyDestructor:keyDestructorDefault;
pht->valDestructor = (valDestructor)?valDestructor:valDestructorDefault;
if(keyDup && !hashFunc)
{
//如果使用 hashFuncDefault 那就最好也使用默认的 strdup
//WARNING
}
pht->count = 0;
pht->rehash_index = -1;
pht->size1 = 0;
pht->tb1 = NULL;
for(i=HT_BASE_SIZE; (unsigned int)(1<size0 = (unsigned int)(1<tb0 = (htItem **)malloc((pht->size0)*sizeof(htItem *));
if(!(pht->tb0))
goto FAIL_2;
memset(pht->tb0,0,(pht->size0)*sizeof(htItem *));
return pht;
FAIL_2:
free(pht);
FAIL_1:
return NULL;
}
int htInsert(htManager *pht,const void *key,const void *val,void **oldVal)
{
htItem *pItemNew = NULL;
htItem **ppHead = NULL;
htItem *pCurItem = NULL;
unsigned int hashVal = 0;
unsigned int indexInTb0 = 0;
unsigned int indexInTb1 = 0;
unsigned char updateFlag = 0;
if(!pht)
goto FAIL;
if(pht->rehash_index < 0) //we do expand/shrink only when we are not doing rehash
{
unsigned int load = (pht->count*100)/(pht->size0);
if(load >= 100)
{
unsigned int newi = 0;
for(newi = HT_BASE_SIZE; (unsigned int)(1<count); newi++)
;
pht->size1 = (unsigned int)(1<tb1 = (htItem **)malloc((pht->size1)*sizeof(htItem *));
if(!(pht->tb1))
goto FAIL;
memset(pht->tb1,0,(pht->size1)*sizeof(htItem *));
pht->rehash_index = 0; //a new rehash process has begun~
}
}
hashVal = (*(pht->hashFunc))(key);
if(pht->rehash_index < 0)
{
//go to tb0 to insert directly
indexInTb0 = hashVal & (pht->size0 - 1); //size mask
ppHead = &pht->tb0[indexInTb0];
pCurItem = *ppHead;
updateFlag = 0;
while(pCurItem)
{
if((pCurItem->hashVal == hashVal) && ((*(pht->keyCmp))(pCurItem->key,key) == 0))
{
if(oldVal) //here I dump for you, but you MUST free them yourself
*oldVal = pCurItem->val; //no need to *oldVal = (*(pht->valDup))(pCurItem->val);
else //you don't care old value, I free them for you.
(*(pht->valDestructor))(pCurItem->val);
pCurItem->val = (*(pht->valDup))(val); //update
updateFlag = 1;
break;
}
pCurItem = pCurItem->next;
}
if(!updateFlag)
{
pItemNew = (htItem *)malloc(sizeof(htItem));
if(!pItemNew)
goto FAIL;
pItemNew->key = (*(pht->keyDup))(key);
pItemNew->val = (*(pht->valDup))(val);
pItemNew->hashVal = hashVal;
pItemNew->next = *ppHead;
*ppHead = pItemNew; //insert to be the new head
pht->count++;
}
return (updateFlag? 0:1);
}
else
{
//1.go to tb0 to find collision list
//2.if not null, search and rehash list to tb1(then it turn to null)
//3.if null, turn to tb1 to search
//4.select one list from rehash_index and rehash (if rehash_index >= tb0.size, free tb0 and tb1->tb0,
// and change rehash_index to -1)
indexInTb0 = hashVal & (pht->size0 - 1); //size mask
pCurItem = pht->tb0[indexInTb0];
updateFlag = 0;
if(pCurItem) //means this collision list has not rehashed
{
while((pCurItem = pickHeadFromCollisionList(pht->tb0,indexInTb0)) != NULL)
{
if((pCurItem->hashVal == hashVal) && ((*(pht->keyCmp))(pCurItem->key,key) == 0))
{
if(oldVal) //here I dump for you, but you MUST free them yourself
*oldVal = pCurItem->val; //no need to *oldVal = (*(pht->valDup))(pCurItem->val);
else //you don't care old value, I free them for you.
(*(pht->valDestructor))(pCurItem->val);
pCurItem->val = (*(pht->valDup))(val); //update
updateFlag = 1;
}
indexInTb1 = (pCurItem->hashVal) & (pht->size1 - 1); //size mask
linkToHeadOfCollisionList(pht->tb1,indexInTb1,pCurItem);
}
if(!updateFlag)
{
pItemNew = (htItem *)malloc(sizeof(htItem));
if(!pItemNew)
goto FAIL;
pItemNew->key = (*(pht->keyDup))(key);
pItemNew->val = (*(pht->valDup))(val);
pItemNew->hashVal = hashVal;
indexInTb1 = (pItemNew->hashVal) & (pht->size1 - 1); //size mask
linkToHeadOfCollisionList(pht->tb1,indexInTb1,pItemNew);
pht->count++;
}
}
else //means this collision list has rehashed to tb1 already (or just a normal null collision list)
{
//go to tb1 to insert directly
indexInTb1 = hashVal & (pht->size1 - 1);
ppHead = &pht->tb1[indexInTb1];
pCurItem = *ppHead;
while(pCurItem)
{
if((pCurItem->hashVal == hashVal) && ((*(pht->keyCmp))(pCurItem->key,key) == 0))
{
if(oldVal) //here I dump for you, but you MUST free them yourself
*oldVal = pCurItem->val; //no need to *oldVal = (*(pht->valDup))(pCurItem->val);
else //you don't care old value, I free them for you.
(*(pht->valDestructor))(pCurItem->val);
pCurItem->val = (*(pht->valDup))(val); //update
updateFlag = 1;
break;
}
pCurItem = pCurItem->next;
}
if(!updateFlag)
{
pItemNew = (htItem *)malloc(sizeof(htItem));
if(!pItemNew)
goto FAIL;
pItemNew->key = (*(pht->keyDup))(key);
pItemNew->val = (*(pht->valDup))(val);
pItemNew->hashVal = hashVal;
pItemNew->next = *ppHead;
*ppHead = pItemNew; //insert to be the new head
pht->count++;
}
}
//increase rehash index on the go. try at least 100 operations
rehashOnTheGo(pht,100);
return (updateFlag ? 0:1);
}
FAIL:
return -1;
}
int htDelete(htManager *pht,const void *key,void **pVal)
{
htItem *pCurItem = NULL;
htItem **ppCurItem = NULL;
unsigned int hashVal = 0;
unsigned int indexInTb0 = 0;
unsigned int indexInTb1 = 0;
unsigned char gotDelItem = 0;
if(!pht)
goto FAIL;
//we do expand/shrink only when we are not doing rehash
//if we reached the HT_BASE_SIZE, we do not do shrink.
if(pht->rehash_index < 0 && (pht->size0 > (unsigned int)(1<count*100)/(pht->size0);
if(load <= 10)
{
unsigned int newi = 0;
for(newi = HT_BASE_SIZE; (unsigned int)(1<count; newi++)
;
pht->size1 = (unsigned int)(1<tb1 = (htItem **)malloc((pht->size1)*sizeof(htItem *));
if(!(pht->tb1))
goto FAIL;
memset(pht->tb1,0,(pht->size1)*sizeof(htItem *));
pht->rehash_index = 0; //a new rehash process has begun~
}
}
hashVal = (*(pht->hashFunc))(key);
if(pht->rehash_index < 0)
{
//go to tb0 to search and delete directly
indexInTb0 = hashVal & (pht->size0 - 1); //size mask
ppCurItem = &pht->tb0[indexInTb0];
gotDelItem = 0;
while(*ppCurItem)
{
if(((*ppCurItem)->hashVal == hashVal) && ((*(pht->keyCmp))((*ppCurItem)->key,key) == 0))
{
pCurItem = *ppCurItem;
*ppCurItem = (*ppCurItem)->next; //del from collision list
if(pVal) //here I dump for you, but you MUST free them yourself
*pVal = pCurItem->val; //no need to *pVal = (*(pht->valDup))(pCurItem->val);
else //you don't care del value, I free them for you.
(*(pht->valDestructor))(pCurItem->val);
(*(pht->keyDestructor))(pCurItem->key);
free(pCurItem);
pht->count--;
gotDelItem = 1;
break;
}
ppCurItem = &((*ppCurItem)->next);
}
return (gotDelItem ? 1:0);
}
else
{
//1.go to tb0 to find collision list
//2.if not null, search and rehash list to tb1(then it turn to null)
//3.if null, turn to tb1 to search
//4.select one list from rehash_index and rehash (if rehash_index >= tb0.size, free tb0 and tb1->tb0,
// and change rehash_index to -1)
indexInTb0 = hashVal & (pht->size0 - 1); //size mask
pCurItem = pht->tb0[indexInTb0];
if(pCurItem) //means this collision list has not rehashed
{
gotDelItem = 0;
while((pCurItem = pickHeadFromCollisionList(pht->tb0,indexInTb0)) != NULL)
{
if((pCurItem->hashVal == hashVal) && ((*(pht->keyCmp))(pCurItem->key,key) == 0))
{
if(pVal) //here I dump for you, but you MUST free them yourself
*pVal = pCurItem->val; //no need to *pVal = (*(pht->valDup))(pCurItem->val);
else //you don't care del value, I free them for you.
(*(pht->valDestructor))(pCurItem->val);
(*(pht->keyDestructor))(pCurItem->key);
free(pCurItem);
pht->count--;
gotDelItem = 1;
}
else
{
indexInTb1 = (pCurItem->hashVal) & (pht->size1 - 1); //size mask
linkToHeadOfCollisionList(pht->tb1,indexInTb1,pCurItem);
}
}
}
else //means this collision list has rehashed already
{
//go to tb1 to search and delete directly
indexInTb1 = hashVal & (pht->size1 - 1);
ppCurItem = &pht->tb1[indexInTb1];
gotDelItem = 0;
while(*ppCurItem)
{
if(((*ppCurItem)->hashVal == hashVal) && ((*(pht->keyCmp))((*ppCurItem)->key,key) == 0))
{
pCurItem = *ppCurItem;
*ppCurItem = (*ppCurItem)->next; //del from collision list
if(pVal) //here I dump for you, but you MUST free them yourself
*pVal = pCurItem->val; //no need to *pVal = (*(pht->valDup))(pCurItem->val);
else //you don't care del value, I free them for you.
(*(pht->valDestructor))(pCurItem->val);
(*(pht->keyDestructor))(pCurItem->key);
free(pCurItem);
pht->count--;
gotDelItem = 1;
break;
}
ppCurItem = &((*ppCurItem)->next);
}
}
//increase rehash index on the go. try 100 times if encounter continues null collision list
rehashOnTheGo(pht,100);
return (gotDelItem ? 1:0);
}
FAIL:
return -1;
}
int htSearch(htManager *pht,const void *key,void **pVal)
{
htItem *pCurItem = NULL;
unsigned int hashVal = 0;
unsigned int indexInTb0 = 0;
unsigned int indexInTb1 = 0;
unsigned char gotItem = 0;
if(!pht)
goto FAIL;
hashVal = (*(pht->hashFunc))(key);
if(pht->rehash_index < 0)
{
//go to tb0 to search directly
indexInTb0 = hashVal & (pht->size0 - 1); //size mask
pCurItem = pht->tb0[indexInTb0];
gotItem = 0;
while(pCurItem)
{
if((pCurItem->hashVal == hashVal) && ((*(pht->keyCmp))(pCurItem->key,key) == 0))
{
if(pVal) //here I dump for you, but you MUST free them yourself
*pVal = (*(pht->valDup))(pCurItem->val);
gotItem = 1;
break;
}
pCurItem = pCurItem->next;
}
return (gotItem ? 1:0);
}
else
{
//1.go to tb0 to find collision list
//2.if not null, search and rehash list to tb1(then it turn to null)
//3.if null, turn to tb1 to search
//4.select one list from rehash_index and rehash (if rehash_index >= tb0.size, free tb0 and tb1->tb0,
// and change rehash_index to -1)
indexInTb0 = hashVal & (pht->size0 - 1); //size mask
pCurItem = pht->tb0[indexInTb0];
gotItem = 0;
if(pCurItem) //means this collision list has not rehashed
{
while((pCurItem = pickHeadFromCollisionList(pht->tb0,indexInTb0)) != NULL)
{
if((pCurItem->hashVal == hashVal) && ((*(pht->keyCmp))(pCurItem->key,key) == 0))
{
if(pVal) //here I dump for you, but you MUST free them yourself
*pVal = (*(pht->valDup))(pCurItem->val);
gotItem = 1;
}
indexInTb1 = (pCurItem->hashVal) & (pht->size1 - 1); //size mask
linkToHeadOfCollisionList(pht->tb1,indexInTb1,pCurItem);
}
}
else
{
//go to tb1 to search and delete directly
indexInTb1 = hashVal & (pht->size1 - 1); //size mask
pCurItem = pht->tb1[indexInTb1];
while(pCurItem)
{
if((pCurItem->hashVal == hashVal) && ((*(pht->keyCmp))(pCurItem->key,key) == 0))
{
if(pVal) //here I dump for you, but you MUST free them yourself
*pVal = (*(pht->valDup))(pCurItem->val);
gotItem = 1;
break;
}
pCurItem = pCurItem->next;
}
}
rehashOnTheGo(pht,100);
return (gotItem ? 1:0);
}
FAIL:
return -1;
}
//int htPairArrayGet(htManager *pht,pair **pairArray,int pairCmp(const void *p1,const void *p2))
int htToPairArray(htManager *pht,pair **pairArray,int pairCmp(const void *p1,const void *p2))
{
unsigned int index = 0;
unsigned int count = 0;
pair *kv = NULL;
htItem *pCurItem = NULL;
if(!pht || pht->count <= 0 || !pairArray)
return -1;
kv = (pair *)malloc((pht->count)*sizeof(pair));
if(!kv)
return -1;
if(pht->tb0)
{
for(index=0; index < pht->size0 && count < pht->count; index++)
{
//search collision list
pCurItem = pht->tb0[index];
while(pCurItem)
{
kv[count].key = (*(pht->keyDup))(pCurItem->key);
kv[count].val = (*(pht->valDup))(pCurItem->val);
count++;
pCurItem = pCurItem->next;
}
}
}
//count hold ...
if(pht->tb1)
{
for(index=0; index < pht->size1 && count < pht->count; index++)
{
//search collision list
pCurItem = pht->tb1[index];
while(pCurItem)
{
kv[count].key = (*(pht->keyDup))(pCurItem->key);
kv[count].val = (*(pht->valDup))(pCurItem->val);
count++;
pCurItem = pCurItem->next;
}
}
}
if(pairCmp) //1 待排序数组首地址 2 数组中待排序元素数量 3 各元素的占用空间大小 4 指向函数的指针
qsort(kv,pht->count,sizeof(kv[0]),pairCmp);
*pairArray = kv;
return pht->count;
}
/* if this put function not provide, you MUST know how to proper free kv array!
int htPairArrayPut(htManager *pht,pair *pairArray)
{
unsigned int i=0;
if(!pht || pht->count <= 0 || !pairArray)
return -1;
for(i=0;icount;i++)
{
(*(pht->keyDestructor))(pairArray[i].key);
(*(pht->valDestructor))(pairArray[i].val);
}
free(pairArray);
return 0;
}*/
void htDestroy(htManager *pht)
{
unsigned int index = 0;
htItem *pHead = NULL;
htItem *pCurItem = NULL;
if(!pht)
return;
if(pht->tb0)
{
for(index=0; indexsize0 && pht->count > 0; index++)
{
//search collision list
pHead = pht->tb0[index];
pCurItem = pHead;
while(pCurItem)
{
pHead = pCurItem->next;
(*(pht->keyDestructor))(pCurItem->key);
(*(pht->valDestructor))(pCurItem->val);
free(pCurItem);
pht->count--;
pCurItem = pHead;
}
}
free(pht->tb0);
pht->size0 = 0;
pht->tb0 = NULL;
}
if(pht->tb1)
{
for(index=0; indexsize1 && pht->count > 0; index++)
{
//search collision list
pHead = pht->tb1[index];
pCurItem = pHead;
while(pCurItem)
{
pHead = pCurItem->next;
(*(pht->keyDestructor))(pCurItem->key);
(*(pht->valDestructor))(pCurItem->val);
free(pCurItem);
pht->count--;
pCurItem = pHead;
}
}
free(pht->tb1);
pht->size1 = 0;
pht->tb1 = NULL;
}
free(pht);
return;
}
//============== for DEBUG =================
static int collisionListLen(htItem *pHead)
{
htItem *pCurItem = pHead;
int len = 0;
while(pCurItem)
{
len++;
pCurItem = pCurItem->next;
}
return len;
}
void debugHt(htManager *pht)
{
unsigned int index = 0;
htItem *pHead = NULL;
unsigned int maxLen = 0;
unsigned int tmp = 0;
int *stat = NULL;
int sum = 0;
if(pht->tb0)
{
maxLen = 0;
for(index=0; indexsize0; index++)
{
pHead = pht->tb0[index];
if((tmp = collisionListLen(pHead)) > maxLen)
maxLen = tmp;
}
stat = (int *)malloc((maxLen+1)*sizeof(int));
for(index=0; indexsize0; index++)
{
pHead = pht->tb0[index];
stat[collisionListLen(pHead)]++;
}
printf("tb0 stat:(%u/%u),max collision len %u\n",pht->count,pht->size0,maxLen);
for(index=0;index<=maxLen;index++)
{
sum += index * stat[index];
printf("len %u (%u lists)\n",index,stat[index]);
}
printf("calculated sum = %u\n",sum);
free(stat);
}
if(pht->tb1)
{
maxLen = 0;
for(index=0; indexsize1; index++)
{
pHead = pht->tb1[index];
if((tmp = collisionListLen(pHead)) > maxLen)
maxLen = tmp;
}
stat = (int *)malloc((maxLen+1)*sizeof(int));
for(index=0; indexsize1; index++)
{
pHead = pht->tb1[index];
stat[collisionListLen(pHead)]++;
}
printf("tb1 stat:(%u/%u),max collision len %u\n",pht->count,pht->size1,maxLen);
for(index=0;index<=maxLen;index++)
printf("len %u (%u lists)\n",index,stat[index]);
free(stat);
}
} test.c
#include
#include
#include
#include
#include
#include "hashTable.h"
int hashTable_test1()
{
int i=0;
//char *v = NULL;
char k[50] = {0};
printf("======================================================\n");
for(i=0;i<200;i++)
{
sprintf(k,"key_%d",i);
printf("%s\n",k);
}
getchar();
//i=100000;
while(1)
{
htManager *pht = htCreate(0,NULL,NULL,NULL,NULL,NULL,NULL);
//printf("htCreate ..\n");
//usleep(1000000);
htDestroy(pht);
pht = NULL;
usleep(1000);
//printf("htDestroy \n");
}
return 0;
}
int hashTable_test2()
{
int del_num[]={984,23,444,678,2550,3486,23};
int reInsert_num[]={55,3905,344,2550,3486,23};
void *val_temp=0;
int i=0;
int res = 0;
htManager *pht = htCreate(0,NULL,NULL,NULL,NULL,NULL,NULL);
//char *v = NULL;
char k[50] = {0};
/* insert test */
for(i=0;i<2560;i++)
{
sprintf(k,"key_%d",i);
res = htInsert(pht,k,(const void *)i,NULL);
if(res == 1)
{
printf("ins(%s,%d)\n",k,i);
}
else if(res == 0)
{
printf("update a value ,wait for confirm\n");
getchar();
}
else
{
printf("ins fail ,wait for confirm\n");
getchar();
}
}
printf("insert ok, wait for continue\n");
getchar();
/* insert a exist element test */
for(i=0;ival) - (int)(p2->val));
}
int hashTable_test4()
{
int i=0;
int res = 0;
htManager *pht = htCreate(0,NULL,NULL,NULL,NULL,NULL,NULL);
char k[50] = {0};
int v=0;
srand(0); //生成随机种子
/* insert test */
for(i=0;i<100;i++)
{
sprintf(k,"key_%d",i);
v = rand()%100;
res = htInsert(pht,k,(const void *)v,NULL);
if(res == 1)
{
printf("ins(%s,%d)\n",k,v);
}
else if(res == 0)
{
printf("update a value key=%s,val=%d,wait for confirm\n",k,v);
getchar();
}
else
{
printf("ins fail ,wait for confirm\n");
getchar();
}
}
printf("insert ok,total %u elements, wait for continue\n",pht->count);
getchar();
pair *pKV = NULL;
unsigned int pairLen=0;
pairLen = htToPairArray(pht,&pKV,myPairCmp);
//pairLen = htToPairArray(pht,&pKV,NULL);
//then we can even destroy hash table here..,because that kv array has no relationship with hashtable any more
htDestroy(pht);
pht = NULL;
for(i=0;i 5. c++中的map
c++提供了map就不用自己造轮子了, 参考 c++map使用