用Python实现一个细粒度hadoop作业监控分析工具
在使用或者管理维护hadoop集群的时候,监控工具是必不可少的,hadoop集群相关的监控工具有ganglia,chukwa,功能强大,可以监控整个集群的资源使用状况。但是面对一些问题,比如具体到单个job,mapper,ruducer粒度的测试,profiling,性能调优等,ganglia,chukwa等集群监控工具的监控粒度似乎有些大,好像没有提供针对单个job->task->task-attempt级别的性能数据采集与监控(对它们了解比较少,可能有这个功能我没找到?)
正好最近在尝试优化mapreduce的单机计算部分,需要一个粒度到task_attempt级别的监控工具来收集CPU,内存等性能相关的信息。需求如下:
1. 收集集群中每个mapreduce task相关的进程的动态运行信息(CPU, RSS, VM等, 可扩充), 按照job-> task_attempt->process的层次组织;
2. 使用streaming/bistreaming的job每个task_attempt由多个进程组成,这种多进程task也需要识别;
3. 用户可以以web方式浏览每个提交的任务的细粒度运行信息,这些信息通过文本和图表方式展示。
简单分析下需求后,发现可以拿python很快的实现一个:
1. 每个task tracker node部署一个monitor负责收集信息,并将信息通过http POST方式实时发送给server
2. Server负责将收集到的信心组织成job->task_attempt->process->value_seq的层次形式,并提供web接口供用户浏览
所以这个工具就两个模块,monitor和server,使用python丰富的工具库后代码很少,每个模块一个数百行的py文件即可:
1. Monitor的监控数据采集使用psutil(http://code.google.com/p/psutil ),与server的通信使用httplib,数据以json方式编码;
2. Server的web server使用webpy(http://webpy.org/),将数据转化成图表使用matplotlib(http://matplotlib.sourceforge.net, 在前两篇文章中也有介绍)
由于代码不多,下面会详细介绍实现,网络,多线程,web,图形,系统编程都有些涉及,对学习python或者了解上述几个工具类库的使用来说算是一个不错入门例子吧。
先来介绍monitor模块,分成数据收集和数据发送两块,各实现为一个线程。
数据收集线程 -> buffer -> 数据发送线程, 典型的生产-消费模型
1. 收集线程:
识别新的attempt进程将之放入usefull_processes中
遍历usefull_processes,收集进程信息并封装成json string,append到buffer中
2. 发送线程:
定时检查buffer是否有内容,并批量发送给server
相关代码:
import sys import traceback import time import socket import threading import json import psutil hostname = socket.gethostname() def get_attempt_id(pid): current = pid while (True): if current <= 1000: return None p = psutil.Process(current) cmd = " ".join(p.cmdline) pos = cmd.find(" attempt_") if pos > 0: end = cmd.find(" ", pos+1) if end == -1: return cmd[pos+1] return cmd[pos+1:end] current = p.ppid def get_event(pid, attempt_id, t): p = attempt_id[1] meminfo = p.get_memory_info() timeinfo = p.get_cpu_times() info = {"attempt":attempt_id[0], "pid": pid, "cmd": " ".join(p.cmdline), "start":p.create_time, "current":t, "tuser":timeinfo[0], "tsystem":timeinfo[1], "rss":meminfo[0], "vms":meminfo[1], "cpu":p.get_cpu_percent(0.0), "threads":p.get_num_threads(), "host":hostname} ret = json.dumps(info) #print ret return ret +"/n"; usefull_pids = {} rubbish_pids = {} event_buffer = [] event_buffer_lock = threading.Lock() def check_processes(): global event_buffer # check for new process pids = psutil.get_pid_list() #print pids for pid in pids: if usefull_pids.has_key(pid): continue if rubbish_pids.has_key(pid): continue # try: attempt_id = get_attempt_id(pid) if attempt_id: sys.stderr.write("Get new process [%d] for hadoop task attempt [%s]/n" % (pid, attempt_id)) usefull_pids[pid] = (attempt_id, psutil.Process(pid)) else: rubbish_pids[pid] = pid # except: # sys.stderr.write("Get attemp id for %d failed/n" % pid) # sys.stderr.flush() # continue for pid in usefull_pids.keys(): if pid not in pids: del usefull_pids[pid] for pid in rubbish_pids.keys(): if pid not in pids: del rubbish_pids[pid] # update old process t = int(time.time()) for pid, attempt_id in usefull_pids.iteritems(): try: event_str = get_event(pid, attempt_id, t) with event_buffer_lock: event_buffer.append(event_str) except: sys.stderr.write("Get event info error, pid=%d, attempt_id=%s" % (pid, attempt_id[0])) sys.stderr.flush() def loop(): global event_buffer while (True): try: check_processes() except: traceback.print_exc() time.sleep(1.5) if len(event_buffer) > 1024*32: with event_buffer_lock: event_buffer = event_buffer[1024*4:] read_thread_run = True def local_read_thread(): global event_buffer global read_thread_run while read_thread_run: if len(event_buffer)>0: with event_buffer_lock: ready = event_buffer event_buffer = [] for e in ready: print e time.sleep(1.5); import httplib import urllib def http_send_thread(post_url): global event_buffer global read_thread_run if post_url.startswith("http://"): post_url = post_url[7:] try: host,path = post_url.split('/',1) path = '/'+path except: host = post_url path = '/' while read_thread_run: while len(event_buffer) <= 0 and read_thread_run: time.sleep(2) if not read_thread_run: break try: # print "Host: %s, path: %s" % (host, path) conn = httplib.HTTPConnection(host) length = len(event_buffer) params = urllib.urlencode({"content":"".join(event_buffer[:length])}) conn.request("POST", path, params) rep = conn.getresponse() if rep.status/100 == 2: with event_buffer_lock: #print "[%d/%d] send" % (length, len(event_buffer)) event_buffer = event_buffer[length:] else: print "HTTP post error: %s" % rep.status time.sleep(10) except: traceback.print_exc() time.sleep(10)
该模块作为daemon运行在多台机器上,所以最好能实现daemon运行,这里使用网上流传比较广的python daemon实现:fork()->setsid()->fork()->run(),具体原理可以参考APUE的相关章节,相关代码:
import sys, os, time, atexit from signal import SIGTERM class Daemon: """ A generic daemon class. Usage: subclass the Daemon class and override the run() method """ def __init__(self, pidfile, stdin='/dev/null', stdout='/dev/null', stderr='/dev/null'): self.stdin = stdin self.stdout = stdout self.stderr = stderr self.pidfile = pidfile def daemonize(self): """ do the UNIX double-fork magic, see Stevens' "Advanced Programming in the UNIX Environment" for details (ISBN 0201563177) http://www.erlenstar.demon.co.uk/unix/faq_2.html#SEC16 """ try: pid = os.fork() if pid > 0: # exit first parent sys.exit(0) except OSError, e: sys.stderr.write("fork #1 failed: %d (%s)/n" % (e.errno, e.strerror)) sys.exit(1) # decouple from parent environment # os.chdir("/") os.setsid() os.umask(0) # do second fork try: pid = os.fork() if pid > 0: # exit from second parent sys.exit(0) except OSError, e: sys.stderr.write("fork #2 failed: %d (%s)/n" % (e.errno, e.strerror)) sys.exit(1) # redirect standard file descriptors sys.stdout.flush() sys.stderr.flush() si = file(self.stdin, 'r') so = file(self.stdout, 'a+') se = file(self.stderr, 'a+', 0) os.dup2(si.fileno(), sys.stdin.fileno()) os.dup2(so.fileno(), sys.stdout.fileno()) os.dup2(se.fileno(), sys.stderr.fileno()) # write pidfile atexit.register(self.delpid) pid = str(os.getpid()) file(self.pidfile,'w+').write("%s/n" % pid) def delpid(self): os.remove(self.pidfile) def start(self): """ Start the daemon """ # Check for a pidfile to see if the daemon already runs try: pf = file(self.pidfile,'r') pid = int(pf.read().strip()) pf.close() except IOError: pid = None if pid: message = "pidfile %s already exist. Daemon already running?/n" sys.stderr.write(message % self.pidfile) sys.exit(1) # Start the daemon self.daemonize() self.run() def stop(self): """ Stop the daemon """ # Get the pid from the pidfile try: pf = file(self.pidfile,'r') pid = int(pf.read().strip()) pf.close() except IOError: pid = None if not pid: message = "pidfile %s does not exist. Daemon not running?/n" sys.stderr.write(message % self.pidfile) return # not an error in a restart # Try killing the daemon process try: while 1: os.kill(pid, SIGTERM) time.sleep(0.1) except OSError, err: err = str(err) if err.find("No such process") > 0: if os.path.exists(self.pidfile): os.remove(self.pidfile) else: print str(err) sys.exit(1) def restart(self): """ Restart the daemon """ self.stop() self.start() def run(self): """ You should override this method when you subclass Daemon. It will be called after the process has been daemonized by start() or restart(). """ class mon_daemon(Daemon): def run(self): read_thread_run = True t = threading.Thread(target=http_send_thread,args=[sys.argv[1]]) t.start() try: loop() finally: read_thread_run = False t.join() if __name__ == "__main__": dm = mon_daemon('./decmon.pid', stdout="./mon.log", stderr="./mon.log.wf") if len(sys.argv) == 3: if 'start' == sys.argv[2]: dm.start() elif 'stop' == sys.argv[2]: dm.stop() elif 'restart' == sys.argv[2]: dm.restart() else: print "Unknown command"
一些说明:
get_attempt_id函数用来判断一个进程不是不是属于一个task_attempt的,如果是就返回task_attemp id,否则返回None,原理就是不停的取其父进程,看其cmd是否包含” attempt_xxxx_xxx”格式的字符串
local_read_thread用来本地测试
Deamon工具类中# os.chdir("/")这一行被注释掉,因为这个py执行需要当前路径下的一些类库和pid,日志文件,不能改变路径
模块需要部署在集群的多台机器上,还好只是个py文件加psutil类库,很方便部署。使用hadoop的slaves.sh:
./slaves.sh scp xxx /tmp/client
./slaves.sh /tmp/client/run.sh
这里run.sh只是对py的简单封装,让其在运行前保证pwd在py所在的路径
接下来是server模块,其实就是个非常简洁的web server,使用webpy 的内置web server不需要apache,nginx啥的,另外收集的数据使用python内置数据结构保存在内存,不持久保存(感觉profiling数据没啥必要),但是也支持将数据dump到磁盘以后再load,

相关代码:
import traceback import sys import os import time import json import logging import web import urllib import cStringIO as StringIO def get_jobid_by_attempid(attempt_id): try: last_ = attempt_id.find('_') last_ = attempt_id.find('_', last_+1) last_ = attempt_id.find('_', last_+1) return attempt_id[8:last_] except: traceback.print_exc() return None class Job(object): def __init__(self, jobid, parent): # print "Job %s" % jobid self.id = jobid self.attempts = {} self.time = 0 self.parent = parent def settime(self, t): self.time = t def get(self,id,host=None): ret = self.attempts.get(id) if ret == None: ret = Attempt(id, host, self) self.attempts[id] = ret return ret class Attempt(object): def __init__(self, attemptid, host, parent): # print "Attempt %s" % attemptid self.id = attemptid self.exes = {} self.time = 0 self.host = host self.parent = parent def settime(self, t): self.time = t self.parent.settime(t) def get(self,id, exe=None): ret = self.exes.get(id) if ret == None: ret = Exe(id, exe, self) self.exes[id] = ret return ret class Exe(object): def __init__(self, pid, exe, parent): # print "Exe %s" % exe self.id = pid self.exe = exe self.seqs = {} self.time = 0 self.parent = parent def settime(self, t): self.time = t self.parent.settime(t) def get(self,id): ret = self.seqs.get(id) if ret == None: ret = Seq(id, self) self.seqs[id] = ret return ret class Seq(object): def __init__(self, name, parent): # print "Seq %s" % name self.id = name self.vs = [] self.time = 0 self.parent = parent def appendtime(self, t): self.time = t self.vs.append(t) self.parent.settime(t) def add_record(rec, d): try: attempt_id = rec['attempt'] job_id = get_jobid_by_attempid(attempt_id) if job_id == None: return cmd = rec['cmd'] pid = rec['pid'] exename = os.path.basename(cmd.split()[0]) if cmd else "None" rss = rec['rss'] vms = rec['vms'] cpu = rec['cpu'] current = rec['current'] host = rec['host'] jobobj = d.get(job_id) if not jobobj: jobobj = Job(job_id, d) d[job_id] = jobobj attempt = jobobj.get(attempt_id, host) exe = attempt.get(pid, exename) seqt = exe.get('t') seqt.appendtime(current) exe.get('c').vs.append(cpu) exe.get('r').vs.append(rss) exe.get('v').vs.append(vms) except: traceback.print_exc() def time_to_string(t, full=False): return time.strftime("%Y-%m-%d %H:%M:%S" if full else "%H:%M:%S", time.localtime(t)) urls = ( r'/', 'jobs_view', r'/jobs', 'jobs_view', r'/job_([_/d]+)', 'job_view', r'/(attempt_[^/s]+)', 'attempt_view', r'/text/(attempt_[^/s]+)', 'attempt_text_view', r'/fig/(attempt_[^/s]+).png', 'attempt_fig', r'/submit', 'submit_service', r'/save', 'save_service', r'/load', 'load_service', r'/clean', 'clean_service', ) #web.config.debug = False app = web.application(urls, locals()) all = {} # all jobs traced class jobs_view(object): def GET(self): out = StringIO.StringIO() out.write('List of all monitoring jobs:
') have = False for jobid,job in all.iteritems(): have = True out.write('No Jobs Found
/n') out.write('/n') return out.getvalue() class job_view(object): def GET(self, job_id): out = StringIO.StringIO() out.write('JobID: %s
/n' % job_id) job = all.get(job_id) if not job: out.write('Not Found!') else: out.write('Time: %s
' % time_to_string(job.time, True)) out.write('List of task attempts:
') have = False for attempt, obj in job.attempts.iteritems(): have = True out.write('No Jobs Found
/n') out.write('/n') return out.getvalue() def output_seq(name, seq, out, t=False): out.write('') out.write(' ') def output_exeinfo(exe, out): out.write('%s /n' % name) for v in seq: out.write(' %s /n' % (time_to_string(v) if t else str(v))) out.write('%s - %s
/n' % (exe.id, exe.exe) ) out.write('') output_seq("Time:", exe.seqs['t'].vs,out,True) output_seq("CPU:", exe.seqs['c'].vs,out) output_seq("RSS:", exe.seqs['r'].vs,out) output_seq("VM:", exe.seqs['v'].vs,out) out.write('
') class attempt_view(object): def GET(self, attempt_id): out = StringIO.StringIO() out.write('Attempt run on %s, %s last update: %s
/n' % (attempt.host, attempt_id, time_to_string(attempt.time))) out.write('Text Detail
/n' % attempt_id) out.write('%s last update: %s
/n' % (attempt_id, time_to_string(attempt.time))) for exe in attempt.exes.itervalues(): output_exeinfo(exe, out) out.write('/n') return out.getvalue() import matplotlib.pyplot as plt class attempt_fig(object): def GET(self, attempt_id): jobid = get_jobid_by_attempid(attempt_id) job = all.get(jobid) if not job: return web.notfound attempt = job.attempts.get(attempt_id) if not attempt: return web.notfound exes = attempt.exes fig = plt.figure(figsize=(18,12)) ax = fig.add_subplot(211) for exe in exes.itervalues(): pn = "%s(%s)" % (exe.exe, exe.id) ax.plot(exe.seqs['t'].vs, [x/(1024*1024) for x in exe.seqs['r'].vs], label=pn+' RSS') #ax.plot(exe.seqs['t'].vs, exe.seqs['v'].vs, label=pn+' VM') plt.ylim(0, 1024) ax.legend() ax.grid(True) ax2 = fig.add_subplot(212) for exe in exes.itervalues(): pn = "%s(%s)" % (exe.exe, exe.id) ax2.plot(exe.seqs['t'].vs, exe.seqs['c'].vs, label=pn+' CPU') plt.ylim(-5, 150) ax2.legend() ax2.grid(True) web.header("Content-Type", "image/png") buff = StringIO.StringIO() fig.savefig(buff, format='png') return buff.getvalue() class submit_service(object): def POST(self): c = web.input().get('content') records = c.split('/n') for r in records: if len(r) < 4: continue add_record(json.loads(r), all) import cPickle as pickle class save_service(object): def GET(self): global all c = web.input().get('pass') if c == 'DEC': fout = open('temp.data', 'w') pickle.dump(all, fout) fout.close() return "SAVE OK" else: return web.notfound def POST(self): self.GET() class load_service(object): def GET(self): global all c = web.input().get('pass') if c == 'DEC': fin = open('temp.data', 'r') all = pickle.load(fin) fin.close() return "LOAD OK" else: return web.notfound class clean_service(object): def GET(self): global all c = web.input().get('pass') if c == 'DEC': all = {} fout = open('temp.data', 'w') pickle.dump(all, fout) fout.close() return "SAVE OK" else: return web.notfound if __name__ == "__main__": app.run()
截图:
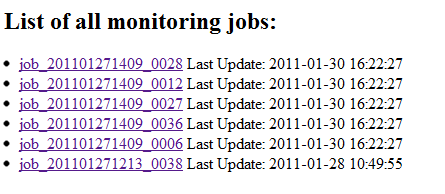
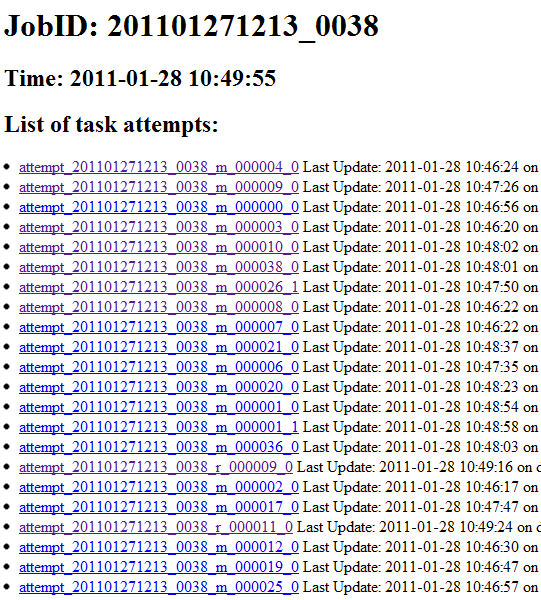
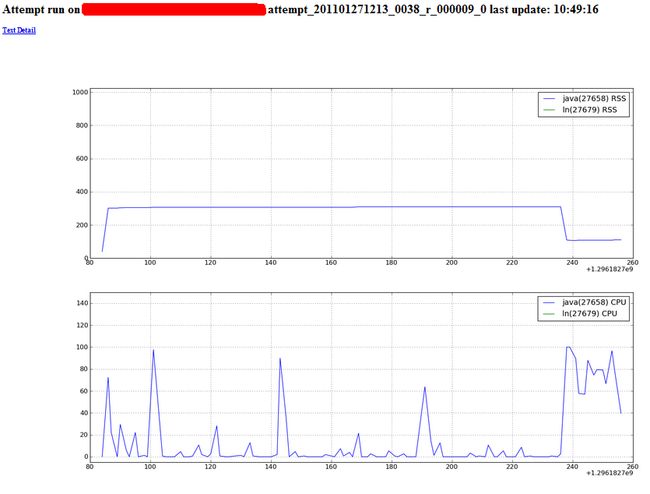
一些改进和想法:
代码里面还是有不少问题;
在开发过程中,每次修改monitor端的代码就要重新部署,比较麻烦,其实可以将monitor的py代码放在server端,提供http方式下载,这样监控端实现个从server端下载代码运行的逻辑,并且定时检查是否有新版本的monitor可供更新,这样每次在服务端修改代码后,就会自动更新不必重新部署了;
目前仅对单个attempt的所有process有个统计的图表,凭借目前收集到得数据,其实是可以把job的整个运行过程可视化展示出来的,这样应该会为mapreduce应用开发者提供一个优化作业的工具;
刨去daemon部分的代码,整个工具也就400来行,证明python不论是在系统编程,web开发还是图表生成方面都是简洁而强大的:)