ThinkPHP5.0(九)PHP下载指定服务器目录下的文件(word文件),打包下载多个文件
需求
一般在ThinkPHP5.0中我们会上传文件到服务器的指定目录下(一般为public下的upload文件中),以达到必要时候对其下载的目的;
但是我们已知文件在服务器的路径怎么对其下载?
接下来一起详细探讨一下,下载文件的过程。
详细步骤:
路径: ../public/uploadDir/ 这个是.docx文件的存储路径,.docx文件是我们要进行下载的的目标文件;
对文件下载权限,路径进行基础判断:
其中:
basename:返回路径中的文件名部分。
is_dir:判断指定的文件名是否是一个目录。
scandir:函数返回指定目录中的文件和目录的数组。
注意空的dir包含两个目录当前目录. 和 上级目录 ..
public function fileReader()
{
/** 查看是否有文件下载权限 */
$downloadPower=getDownloadPower();//获得下载权限
if($downloadPower==false)return $this->error('文件暂不能下载,请联系管理员!');
$fileLocation = '../public/uploadDir/'; //文件在服务器固定路径
$UpDir= basename($fileLocation); //匹配路径中文件夹名称
/** 查看路径下是否存在存放文件的文件夹 */
//固定目录下文件夹不存在
if (is_dir($UpDir)==false) return $this->error('文件不存在,请联系管理员');
/** 判断dir文件夹中包含的文件数 */
if (count(scandir($UpDir))!=2) //固定目录文件夹下不为空,空的文件夹包含2个目录'.'和'..'
{
DocxProduceHelper::downloadDoc($fileLocation); //进行正常下载
}
}
对下载权限,路径和路径下的文件进行了基本的判断后就可以调用真正的下载函数了。
downloadDoc()函数:
opendir:
readdir:函数返回目录中下一个文件的文件名。
is_readable:判断文件是否可读。
fopen:只读( r )方式打开,将文件指针指向文件头,为移植性考虑,强烈建议在用 fopen() 打开文件时总是使用 “b” 标记。
feof:检测流上的文件结束符。
fread:读取文件(可安全用于二进制文件)。
public static function downloadDoc($fileLocation)
{
/** 打开文件夹(目录句柄) 返回目录句柄资源*/
$dir = opendir($fileLocation);//打开目录
/** 用readdir循环读出路径下文件名称,务必使用!==,防止目录下出现类似文件名“0”等情况 */
while (($file_name = readdir($dir)) !== false) {
// . 表示当前目录,..表示上一级目录 ,readdir会读取到当前的dir下的目录和文件其中.和..为目录不在读取范围
if ($file_name != "." && $file_name != "..") continue;
$filePath=$fileLocation.$file_name;//拼接要下载word文件的具体路径(之前只是文件夹路径)
//当下载文档含有中文的时候进行转码,防止出现获取不到路径
if (!is_readable($filePath)) exit('不能获取到' .$file_name);//文件不可读
$fileHandle = fopen($filePath, "rb");//打开文件
if ($fileHandle == false) exit("不能打开" .$file_name);//打开失败
// 设置HTTP header
header('Content-type:application/octet-stream; charset=utf-8');//设置MINE类型
header("Content-Transfer-Encoding: binary");//指示标识函数(即没有压缩,也没有修改)
header("Accept-Ranges: bytes");//范围的单位是字节。
header("Content-Length: " . filesize($filePath));//文件大小
header('Content-Disposition:attachment;filename="'.$file_name.'"'); //触发浏览器文件下载功能,定义下载的文件名
while (!feof($fileHandle)) echo fread($fileHandle, 10240);//读取文件
fclose($fileHandle);//关闭文件指针
}
closedir($dir);//关闭目录
}
打包下载
经过上面的步骤实现了文件的下载,其中我们用到了readdir($dir))循环遍历读取dir中的文件,其实这种方法是不可能实现多文件下载的;
大部分浏览器都不支持多文件同时下载;
也就是当存在两个以上的文件的时候基本下载的文件就会出错乱码;
这个时候就需要打包成一个压缩包进行下载:
$zip = new ZipArchive();//新建zip对象
$zipName="downLoad.zip";//zip name
//打开zip对象
if ($zip->open($zipName, ZipArchive::CREATE)==TRUE) {
while (($file_name = readdir($dir)) !== false){
//将文件遍历填充
if(file_exists($file_name)){
$zip->addFile( $file_name, basename($file_name));
}
}
}
$zip->close();
再更改HTTP header的MINE类型为
header("Content-Type: application/zip"); //zip格式的
总结:
其实对文件的下载主要分3步:
- 对文件路径和路径下文件进行判断,路径是否存在,是否为空,一般调用PHP Directory方法对目录进行判断,PHP Directory方法对具体文件进行操作;
- 遍历目录和文件进行输出,目录遍历
readdir,具体文件遍历feof; - 设置header进行下载.
————————————————————————————————————————————————————————
这里我们在 header 里定义了Content-Length为filesize($filePath)既为文件本身的大小,然后又在输出的时候定义了fread($fileHandle, 10240)既读取文件大小最大为10240个字节;
fread的定义为:
fread() 从文件指针 file 读取最多 length 个字节。该函数在读取完最多 length 个字节数,或到达 EOF 的时候,或(对于网络流)当一个包可用时,或(在打开用户空间流之后)已读取了 length 个字节时就会停止读取文件,视乎先碰到哪种情况。
我们尝试将一个超过10240字节的文件进行输出:
监控其header值:
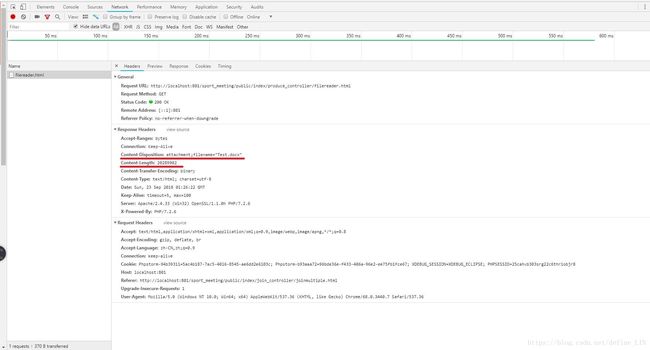
发现能够完整下载到文件,说明下载文件大小依赖于先于fread设置的header里的Content-Length属性。
————————————————————————————————————————————————————
参考:
PHP Directory 函数:http://www.w3school.com.cn/php/php_ref_directory.asp
PHP Filesystem 函数:http://www.w3school.com.cn/php/php_ref_filesystem.asp
文件类型:https://www.cnblogs.com/xiaohuochai/p/6088999.html
HTTP Header:https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers