抓取百度手机市场、应用宝、360手机市场应用
这几天想根据apk应用名去几个市场上搜索应用,并下载这些apk。查看了下这个3个市场的apk检索结果,都有一个好处是在检索页面就可以得到这些apk的下载链接。腾讯应用宝是使用ajax查询并返回json数据,所以处理起来更方便些。
下面是三个应用市场的获取下载链接的html结构:
百度手机助手:
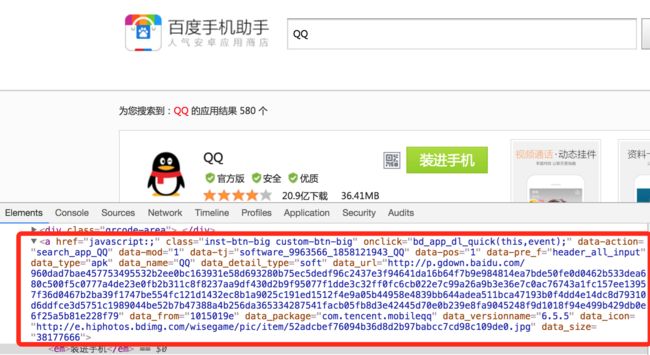
腾讯应用宝:
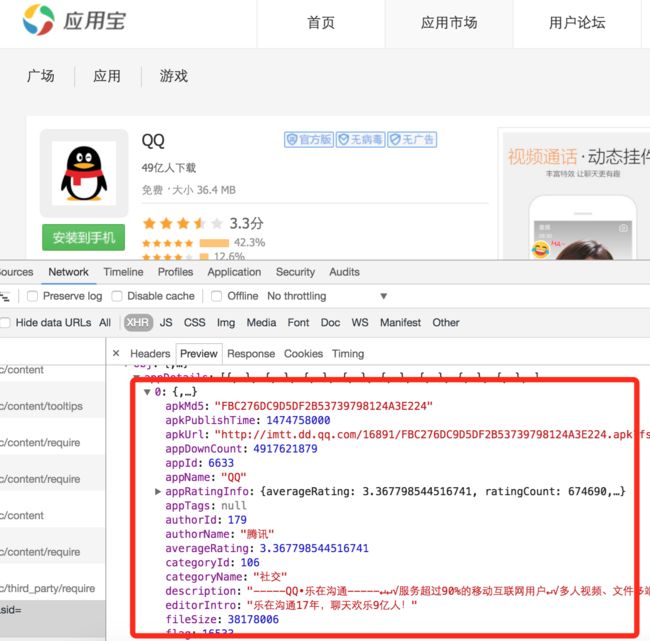
360手机助手:

所以这抓取这三个网页的流程是一致的,所不同的只是解析的功能有所差异。
抓取的代码:
import json
import logging
import os
import requests
from bs4 import BeautifulSoup
STORE_APP_BASE = "/app/stored/path/"
logging.basicConfig(filename="crawler.log", level=logging.DEBUG)
class Crawler(object):
QUERY_URL = ""
USER_AGENT = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36"
CRAWLER_TYPE = ""
def __init__(self, app_name):
self.app_name = app_name
def build_headers(self):
return {
"user-agent": self.USER_AGENT
}
headers = property(build_headers)
@property
def store_folder(self):
return os.path.join(STORE_APP_BASE, self.CRAWLER_TYPE)
def _get_content(self, url):
try:
resp = requests.get(url, headers=self.headers)
content = resp.content
except:
content = ""
return content
def search(self):
url = self.QUERY_URL % self.app_name
return self._get_content(url)
def parse(self, content):
pass
def download(self, url):
try:
resp = requests.get(url, headers=self.headers)
content = resp.content
path = os.path.join(self.store_folder, u"%s.apk" % self.app_name)
with open(path, 'wb') as f:
f.write(content)
except:
logging.error("download for %s url %s error", self.app_name, url)
def run(self):
search_content = self.search()
download_url = self.parse(search_content)
self.download(download_url)
class BaiduCrawler(Crawler):
QUERY_URL = u"http://shouji.baidu.com/s?wd=%s&data_type=app&f=header_software@input@btn_search"
CRAWLER_TYPE = "baidu"
def parse(self, content):
soup = BeautifulSoup(content, "html.parser")
try:
special_res = soup.find("div", attrs={"class": "s-special-type"})
if special_res:
a_link = special_res.find("a", attrs={"class": "inst-btn-big"})
download_link = a_link['data_url']
else:
a_link = soup.select("ul[class=app-list] > li > div > div[class=little-install] > a")[0]
download_link = a_link['data_url']
except:
download_link = ""
return download_link
class TencentCrawler(Crawler):
QUERY_URL = "http://android.myapp.com/myapp/searchAjax.htm?kw=%s&pns=&sid="
CRAWLER_TYPE = "tencent"
def parse(self, content):
try:
content = json.loads(content)
app_details = content['obj']['appDetails']
obj = app_details[0]
download_url = obj['apkUrl']
except:
download_url = ""
return download_url
class QihooCrawler(Crawler):
QUERY_URL = "http://zhushou.360.cn/search/index/?kw=%s"
CRAWLER_TYPE = "360"
def parse(self, content):
try:
soup = BeautifulSoup(content, "html.parser")
a_link = soup.select(
"div[class=SeaCon] > ul > li > div > div > a")[0]
download_url = a_link.attrs['href']
except:
download_url = ""
return download_url
CRAWLER_LIST = [
BaiduCrawler,
TencentCrawler,
QihooCrawler
]当想要下载的apk比较多的时候,需要考虑并发下载。我采用线程池的方式实现多并发搜索和下载。
线程池是从网上找的示例代码,在这个例子中可用,直接借用。原文章地址暂时找不到了。
线程池代码如下:
class Worker(threading.Thread):
def __init__(self, tasks):
threading.Thread.__init__(self)
self.tasks = tasks
self.daemon = True
self.start()
def run(self):
while 1:
func, args, kwargs = self.tasks.get()
logging.debug('getting tasks: %s - %s', func, args[0])
try:
func(*args, **kwargs)
except Exception, exp:
logging.error("executing %s error %s", func, exp)
finally:
self.tasks.task_done()
class ThreadPool(object):
def __init__(self, size=5):
self.tasks = Queue(size)
for _ in range(size):
Worker(self.tasks)
def add_task(self, func, *args, **kwargs):
logging.debug('adding tasks: %s - %s', func, args[0])
self.tasks.put((func, args, kwargs))
def map(self, func, args_list):
for args in args_list:
self.add_task(func, args)
def wait_completion(self):
self.tasks.join()最后,调度代码如下:
def main():
def download(prod):
for klass in CRAWLER_LIST:
logging.info("start crawling %s, using crawler %s", prod, klass.CRAWLER_TYPE)
crawler = klass(prod)
crawler.run()
products = ["QQ", "WeChat", u"贴吧"] # very long list
pool = ThreadPool(5)
pool.map(download, products)
pool.wait_completion()