学习爬虫基础7-动态的去获取-json数据
动态的获取豆瓣电影的json数据
- 进入豆瓣电影 查看源码,源码中并没有我们需要的数据,通过浏览器的检查功能中的 network ,可以看到页面上的数据是通过前端发送ajax请求,动态的获取的.这样我们就不能直接在html页面中获取到想要的数据了.
- 解决的办法: 直接发送请求去后台获取到返回的json数据
- 地址栏中的请求路径:

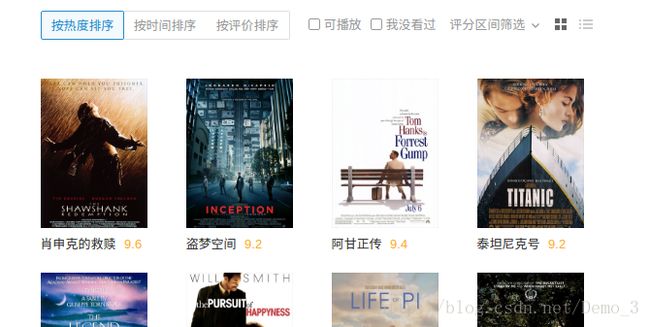
- 根据需求检索的电影

- 检索的结果
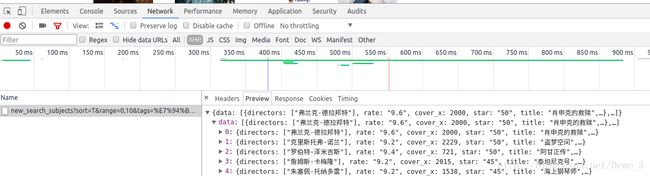
- 前段发送的ajax请求 和返回的数据
- 在header 消息头中的一栏的 最下边是我们的检索方式 也就是我们发送请求需携带的参数
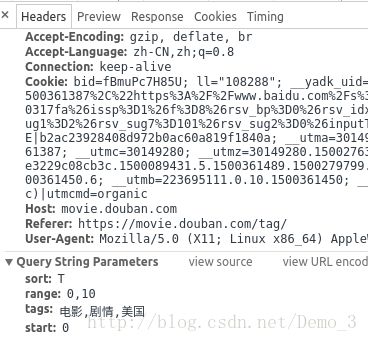
- 基于以上的条件我们就可以采用代码去发送我们的请求
- 代码演示:
# coding=utf-8
# https://movie.douban.com/j/new_search_subjects?
# sort=T&range=0,10&tags=%E5%89%A7%E6%83%85&start=0
# 分析:
# 请求需要带去的参数
# sort:T 排序
# range:0,10 评分范围
# tags:电影,剧情 标签(电影类型)
# start:0 数据的起始位置 从0 开始 每页20条数据
import urllib
import urllib2
import os
def load_page(url):
"""发送请求加载页面"""
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'}
# 构造请求
request = urllib2.Request(url, headers=headers)
try:
# 发送请求
response = urllib2.urlopen(request)
if response.getcode() == 200:
json_data = response.read()
if not os.path.exists('./数据'):
os.mkdir('./数据')
file_path = os.path.join('./数据', 'douban.json')
with open(file_path, 'w') as fp:
fp.write(json_data)
else:
print '请求出错'
except Exception as err:
print err
def spider():
"""爬虫程序"""
base_url = 'https://movie.douban.com/j/new_search_subjects?'
# 构造关键字 请求需要带上的参数
key_words = {
"sort": "T", # 排序的方式
"range": "0,10", # 电影评分的范围
"tags": "电影,剧情,美国", # 检索的标签
"playable": "1", # 是否可以播放
"start": "0" # 检索的开始位置 (这里可以去改变的 从0 开始 一个电影代表的是一条数据)
}
# 编码
key_words = urllib.urlencode(key_words)
url = base_url + key_words
# 调用函数
load_page(url)
def main():
"""程序主函数"""
spider()
if __name__ == "__main__":
main()
返回的结果:
{
"data": [
{
"directors": [
"弗兰克·德拉邦特"
],
"rate": "9.6",
"cover_x": 2000,
"star": "50",
"title": "肖申克的救赎",
"url": "https:\/\/movie.douban.com\/subject\/1292052\/",
"casts": [
"蒂姆·罗宾斯",
"摩根·弗里曼",
"鲍勃·冈顿",
"威廉姆·赛德勒",
"克兰西·布朗"
],
"cover": "https://img3.doubanio.com\/view\/movie_poster_cover\/lpst\/public\/p480747492.jpg",
"id": "1292052",
"cover_y": 2963
},
{
"directors": [
"克里斯托弗·诺兰"
],
"rate": "9.2",
"cover_x": 2229,
"star": "50",
"title": "盗梦空间",
"url": "https:\/\/movie.douban.com\/subject\/3541415\/",
"casts": [
"莱昂纳多·迪卡普里奥",
"约瑟夫·高登-莱维特",
"艾伦·佩吉",
"渡边谦",
"汤姆·哈迪"
],
"cover": "https://img3.doubanio.com\/view\/movie_poster_cover\/lpst\/public\/p513344864.jpg",
"id": "3541415",
"cover_y": 3300
},
{
"directors": [
"罗伯特·泽米吉斯"
],
"rate": "9.4",
"cover_x": 721,
"star": "50",
"title": "阿甘正传",