NIO--字符集
字符集基础
术语
- Character Set(字符集)
字符的集合,也就是带有特殊语义的符号。字母“A”是一个字符。“%”也是一个字符。没有内在数字价值,与ASCII,Unicode,甚至是电脑也没有任何的直接联系。在电脑产生前的很长一段时间内,符号就已经存在了。
- Coded Character Set(编码字符集)
一个数值赋给一个字符的集合。把代码赋值给字符,这样它们就可以用特定的字符编码集表达数字的结果。其他的编码字符集可以赋不同的数值到同一个字符上。字符集映射通常是由标准组织确定的,例如USASCII,ISO 8859-1,Unicode (ISO 10646-1),以及JIS X0201。
- Character-encoding scheme(字符编码方案)
编码字符集成员到八位字节(8bit字节)的映射。编码方案定义了如何把字符编码的序列表达为字节序列。字符编码的数值不需要与编码字节相同,也不需要是一对一或一对多个的关系。原则上,把字符集编码和解码近似视为对象的序列化和反序列化。
通常字符数据编码是用于网络传输或文件存储。编码方案不是字符集,它是映射;但是因为它们之间的紧密联系,大部分编码都与一个独立的字符集相关联。例如,UTF-8,仅用来编码Unicode字符集。尽管如此,用一个编码方案处理多个字符集还是可能发生的。例如,EUC可以对几个亚洲语言的字符进行编码。
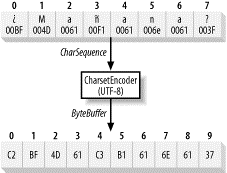
图6-1是使用UTF-8编码方案将Unicode字符序列编码为字节序列的图形表达式。UTF-8把小于0x80的字符代码值编码成一个单字节值(标准ASCII)。所有其他的Unicode字符都被编码成2到6个字节的多字节序列(http://www.ietf.org/rfc/rfc2279.txt)。
- Charset(字符集)
术语charset是在RFC2278(http://ietf.org/rfc/rfc2278.txt)中定义的。它是编码字符集和字符编码方案的集合。java.nio.charset包的锚类是Charset,它封装字符集抽象。
 字符编码成UTF-8
字符编码成UTF-8
字符集
字符集名称不区分大小写,也就是,当比较字符集名称时认为大写字母和小写字母相同。
UTF-8
8-位UCS转换格式。由RFC2279以及Unicode标准3.0(修正版)指定。这是字位导向的字符编码。小于0x80的ASCII字符被编码为单字节。其他字符被编码为两个或多个字节。对于多个序列,用首字节的高序位编码下面字节的数量。(见http://www.ietf.org/rfc/rfc2279.txt。)UTF-8与ASCII的互操作良好,因为简单的ASCII文件就是良好的UTF-8编码,而小于0x80的字符的UTF-8编码就是ASCII文件。
UTF-8是一种变长字节编码方式。对于某一个字符的UTF-8编码,如果只有一个字节则其最高二进制位为0;如果是多字节,其第一个字节从最高位开始,连续的二进制位值为1的个数决定了其编码的位数,其余各字节均以10开头。UTF-8最多可用到6个字节。
如表:
1字节 0xxxxxxx
2字节 110xxxxx 10xxxxxx
3字节 1110xxxx 10xxxxxx 10xxxxxx
4字节 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
5字节 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
6字节 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
因此UTF-8中可以用来表示字符编码的实际位数最多有31位,即上表中x所表示的位。除去那些控制位(每字节开头的10等),这些x表示的位与UNICODE编码是一一对应的,位高低顺序也相同。
实际将UNICODE转换为UTF-8编码时应先去除高位0,然后根据所剩编码的位数决定所需最小的UTF-8编码位数。
因此那些基本ASCII字符集中的字符(UNICODE兼容ASCII)只需要一个字节的UTF-8编码(7个二进制位)便可以表示。
UTF-16
字节序
根据字节序的不同,UTF-16可以被实现为UTF-16LE或UTF-16BE,UTF- 32可以被实现为UTF-32LE或UTF-32BE。例如:
| Unicode编码 | UTF-16LE | UTF-16BE | UTF32-LE | UTF32-BE |
| 0x006C49 | 49 6C | 6C 49 | 49 6C 00 00 | 00 00 6C 49 |
| 0x020C30 | 43 D8 30 DC | D8 43 DC 30 | 30 0C 02 00 | 00 02 0C 30 |
那么,怎么判断字节流的字节序呢?Unicode标准建议用BOM(Byte Order Mark)来区分字节序,即在传输字节流前,先传输被作为BOM的字符"零宽无中断空格"。这个字符的编码是FEFF,而反过来的FFFE(UTF- 16)和FFFE0000(UTF-32)在Unicode中都是未定义的码位,不应该出现在实际传输中。下表是各种UTF编码的BOM:
| UTF编码 | Byte Order Mark |
| UTF-8 | EF BB BF |
| UTF-16LE | FF FE |
| UTF-16BE | FE FF |
| UTF-32LE | FF FE 00 00 |
| UTF-32BE | 00 00 FE FF |
- UTF-16BE,其后缀是 BE 即 big-endian,大端的意思。大端就是将高位的字节放在低地址表示。
- UTF-16LE,其后缀是 LE 即 little-endian,小端的意思。小端就是将高位的字节放在高地址表示。
- UTF-16,没有指定后缀,即不知道其是大小端,所以其开始的两个字节表示该字节数组是大端还是小端。即FE FF表示大端,FF FE表示小端。
字符集类
Charset类封装特定字符集的信息。Charset是抽象。通过调用静态工厂方法forName()获得具体实例,导入所需字符集的名称。所有的Charset方法都是线程安全的;单一实例可以在多个线程中共享。
可以调用布尔类(boolean class)方法isSupported()来确定在JVM运行中当前指定的字符集是否可用。通过Charset SPI机制可以动态安装新的字符集,所以给定字符集名称的答案可以随时间变化。
一个字符集可以有多个名称。通常它有一个规范名称但是也有零个或多个别名。规范名称或别名都可以通过forName()和isSupported()进行使用。
一些字符集也有历史遗留的名称,它们用于之前的Java平台版本并且向后兼容。字符集的历史名称是由InputStreamReader和OutputStream-Writer类的getEncoding()返回。如果字符集有历史名称,那么它将是规范名称或者Charset的别名之一。Charset类不提供历史名称的标示。静态类方法的最后一个,availableCharsets(),将返回在JVM中当前有效的所有字符集的java.util.SortedMap。正如isSupported(),如果安装新的字符集返回的值会随着时间改变。返回映射的成员将是用它们的规范名称作为密钥的Charset对象。迭代时,映射将根据规范名称按字母顺序排列。
package java.nio.charset;
public abstract class Charset implements Comparable
{
public static boolean isSupported (String charsetName)
public static Charset forName (String charsetName)
public static SortedMap availableCharsets()
public final String name()
public final Set aliases()
public String displayName()
public String displayName (Locale locale)
public final boolean isRegistered()
public boolean canEncode()
public abstract CharsetEncoder newEncoder();
public final ByteBuffer encode (CharBuffer cb)
public final ByteBuffer encode (String str)
public abstract CharsetDecoder newDecoder();
public final CharBuffer decode (ByteBuffer bb)
public abstract boolean contains (Charset cs);
public final boolean equals (Object ob)
public final int compareTo (Object ob)
public final int hashCode()
public final String toString()
}
字符集比较
public abstract class Charset implements Comparable
{
// This is a partial API listing
public abstract boolean contains (Charset cs);
public final boolean equals (Object ob);
public final int compareTo (Object ob);
public final int hashCode();
public final String toString();
}
字符集是由字符的编码集与该字符集的编码方案组成的。与普通的集合类似,一个字符集可能是另一个字符集的子集。一个字符集(C1)包含另一个(C2),表示在C2中表达的每个字符都可以在C1中进行相同的表达。每个字符集都被认为是包含其本身。如果这个包含关系成立,那么您在C2(被包含的子集)中编码的任意流在C1中也一定可以编码,无需任何替换。
contains()实例方法显示作为参数传入的Charset对象是否被该Charset对象封装的字符集所包含。该方法不能在运行时动态比较字符集;只有当具体的Charset类确定给出的字符集被包含的情况下才返回true。如果contains()返回false,表示包含关系不存在或未知的包含关系。
如果一个字符集被另一个包含,这不意味着产生的编码字节序列将会等同于给定的输入字符序列。
Charset类明确地覆盖了Object.equals()方法。如果Charset的实例拥有相同的规范名称(由name()返回),它们就被认为是相同的。在JDK1.4.0版本中,由equals()实现的比较是规范名称串的简单比较,这意味着在测试过程中区分大小写。这是在未来的版本中应该更正的错误程序。由于Charset.equals()方法覆盖了Object类中的默认方法,它必须声明为接受一个Object类的参数,而不是Charset类。Charset类的对象永远不会与其他任意类的对象相等。
字符集编码器
这里有用的第一个API方法是canEncode()。该方法表示这个字符集是否允许编码。几乎所有的字符集都支持编码。主要的例外情况是带有解码器的字符集,它们可以自检测字节序列是如何编码并且之后会选择一个合适的解码方案。这些字符集通常只支持解码并且不创建自己的编码。
如果该Charset对象能够编码字符序列,canEncode()方法返回true。如果为false,上面列出的其他三个方法不应该在那个对象上被调用。这样做将引发UnsupportedOperationException。
调用newEncoder()返回CharsetEncoder对象,可以使用和字符集相关的编码方案把字符序列转化为字节序列。之后我们将在本节中学习CharsetEncoder类的API,但是首先我们要快速浏览一下Charset余下的两个方法。
Charset的两个encode()方法使用方便,用默认值针对和字符集相关的编码器实现编码。两个都返回新ByteBuffer对象,包含符合给定的String或CharBuffer字符的一个编码字节序列。解码器通常都在CharBuffer对象上运行。encode()的形式采用String参数自动的为您创建一个临时的CharBuffer,等同于下面这个:
charset.encode (CharBuffer.wrap (string));
在Charset对象上调用encode()使用编码器的默认设置,等同于下列代码:
charset.newEncoder( )
.onMalformedInput (CodingErrorAction.REPLACE)
.onUnmappableCharacter (CodingErrorAction.REPLACE)
.encode (charBuffer);CharsetEncoder:
package java.nio.charset;
public abstract class CharsetEncoder
{
public final Charset charset()
public final float averageBytesPerChar()
public final float maxBytesPerChar()
public final CharsetEncoder reset()
public final ByteBuffer encode (CharBuffer in) throws
CharacterCodingException
public final CoderResult encode (CharBuffer in, ByteBuffer out,
boolean endOfInput)
public final CoderResult flush (ByteBuffer out)
public boolean canEncode (char c)
public boolean canEncode (CharSequence cs)
public CodingErrorAction malformedInputAction()
public final CharsetEncoder onMalformedInput (CodingErrorAction
newAction)
public CodingErrorAction unmappableCharacterAction()
public final CharsetEncoder onUnmappableCharacter (
CodingErrorAction newAction)
public final byte [] replacement()
public boolean isLegalReplacement (byte[] repl)
public final CharsetEncoder replaceWith (byte[] newReplacement)
}CharsetEncoder对象是一个状态转换引擎:字符进去,字节出来。一些编码器的调用可能需要完成转换。编码器存储在调用之间转换的状态。
这里列出的首个方法组提供跟CharsetEncoder对象有关的永恒信息。每个编码器和一个Charset对象相关联,而charset()方法返回一个备份参考。
averageBytesPerChar()方法返回一个浮点值,表示编码集合的字符所需的平均字节数量。注意该值可以是分数值。当编码字符时,编码运算法则可以选择调节字节边界,或者一些字符可以编码成大于其他字节的字节(UTF-8就是这样工作的)。该方法作为一个程序的探索很有用,用来确定ByteBuffer的近似尺寸,ByteBuffer需要包含给定字符的编码字节。
最后,maxBytesPerChar()方法表示在集合中编码单字符需要的最大字节数。这也是一个浮点值。与averageBytesPerChar()类似,该方法被用来按大小排列ByteBuffer。用maxBytesPerChar()返回的值乘以被编码的字符数量将得出最坏情况输出缓冲区大小。
越简单的encode()形式越方便,在重新分配的ByteBuffer中您提供的CharBuffer的编码集所有的编码于一身。这是当您在Charset类上直接调用encode()时最后调用的方法。
当使用CharsetEncoder对象时,在编码之前或编码期间有设置错误处理参数的选项。(本节的后半段将讨论处理编码错误。)调用encode()的单参数形式实现完整的编码循环(复位,编码以及清理),所以编码器之前的内状态将丢失。
让我们详细了解一些编码处理的工作原理。CharsetEncoder类是一个状态编码引擎。实际上,编码器有状态意味着它们不是线程安全的:CharsetEncoder对象不应该在线程中共享。编码可以在一个简单的步骤中完成,如上面提到的encode()的首个形式,或者重复调用encode()的第二个形式。编码过程如下:
1. 通过调用reset()方法复位编码器的状态。让编码引擎准备开始产生编码字节流。新建的CharsetEncoder对象不需要复位,但是这么做也无妨。
2. 不调用或多次调用encode()为编码器提供字符,endOfInput参数false表示后面可能有更多的字符。给定的CharBuffer将消耗字符,而编码字节序列将被添加到提供的ByteBuffer上。
返回时,输入CharBuffer可能不是全部为空。可能输出ByteBuffer会填入,或者编码器可能需要更多的输入来完成多字符转化。编码器本身可能也保留可以影响序列转化实现的状态。在重新填入前紧凑输入缓冲区。
3. 最后一次调用encode(),针对endOfInput参数导入true。提供的CharBuffer可能包含额外的需要编码的字符或为空。重要的是endOfInput在最后的调用上为true。这样就通知编码引擎后面没有输入了,允许它探测有缺陷的输入。
4. 调用flush()方法来完成未完成的编码并输出所有剩下的字节。如果在输出ByteBuffer中没有足够的空间,需要多次调用该方法。
当消耗了所有的输入时,当输出ByteBuffer为满时,或者当探测到编码错误时,encode()方法返回。无论如何,将会返回CoderResult对象,来表示发生的情况。结果对象可表示下列结果条件之一:
- Underflow(下溢)
正常情况,表示需要更多的输入。或者是输入CharBuffer内容不足;或者,如果它不为空,在没有额外的输入的情况下,余下的字符无法进行处理。更新CharBuffer的位置解决被编码器消耗的字符的问题。
在CharBuffer中填入更多的编码字符(首先在缓冲区上调用compact(),如果是非空的情况)并再次调用encode()继续。如果结束了,用空CharBuffer调用encode()并且endOfInput为true,之后调用flush()确保所有的字节都被发送给ByteBuffer。
下溢条件总是返回相同的对象实例:名为CharsetEncoder.UNDERFLOW的静态类变量。这就使您可以使用返回的对象句柄上的等号运算符(==)来对下溢进行检测。
- Overflow(上溢)
表示编码器充满了输出ByteBuffer并且需要产生更多的编码输出。输入CharBuffer对象可能会或可能不会被耗尽。这是正常条件,不表示出错。您应该消耗ByteBuffer但是不应该扰乱CharBuffer,CharBuffer将更新它的位置,之后再次调用encode()。重复进行直到得到下溢结果。
与下溢类似的,上溢返回一致的实例,CharsetEncoder.OVERFLOW,它可直接用于等式比较。
- Malformed input(有缺陷的输入)
编码时,这个通常意味着字符包含16-位的数值,不是有效的Unicode字符。对于解码来说,这意味着解码器遭遇了不识别的字节序列。
返回的CoderResult实例将不是单一的参数,因为它是针对下溢和上溢的。见CoderResult的API。
- Unmappable character(无映射字符)
表示编码器不能映射字符或字符的序列到字节上—例如,如果您正在使用ISO-8859-1编码但您的输入CharBuffer包含非-拉丁Unicode字符。对于解码,解码器知道输入字节序列但是不了解如何创建相符的字符。
编码时,如果编码器遭遇了有缺陷的或不能映射的输入,立即返回结果对象。您也可以检测独立的字符,或者字符序列,来确定它们是否能被编码。下面是检测能否进行编码的方法:
package java.nio.charset;
public abstract class CharsetEncoder
{
// This is a partial API listing
public boolean canEncode (char c)
public boolean canEncode (CharSequence cs)
}canEncode()的两个形式返回boolean结果,表示编码器是否能将给出的输入编码。两种方法都在一个临时的缓冲区内实现输入的编码。这将引起编码器内部状态的改变,所以当编码处理正在进行中时不应调用这些方法。开始编码处理前,使用这些方法检测您的输入。
canEncode()的第二个形成采用类型CharSequence的一个参数,。任何实现CharSequence(当前CharBuffer, String, 或StringBuffer)的对象都可以导入到canEncode()中。
CharsetEncoder的剩下的方法包含在处理编码错误中:
public abstract class CharsetEncoder
{
// This is a partial API listing
public CodingErrorAction malformedInputAction()
public final CharsetEncoder onMalformedInput (CodingErrorAction
newAction)
public CodingErrorAction unmappableCharacterAction()
public final CharsetEncoder onUnmappableCharacter (
CodingErrorAction newAction)
public final byte [] replacement()
public boolean isLegalReplacement (byte[] repl)
public final CharsetEncoder replaceWith (byte[] newReplacement)
}如之前提到的,CoderResult对象可以从encode()中返回,表示编码字符序列的问题。有两个已定义的代码错误条件:malformed和unmappable。在每一个错误条件上都可以配置编码器实例来采取不同的操作。当这些条件之一发生时,CodingErrorAction类封装可能采取的操作。CodingErrorAction是无有用的方法的无价值的类。它是简单的,安全类型的列举,包含了它本身的静态、已命名的实例。CodingErrorAction定义了三个公共域:
- REPORT(报告)
创建CharsetEncoder时的默认行为。这个行为表示编码错误应该通过返回CoderResult对象报告,前面提到过。
- IGNORE(忽略)
表示应忽略编码错误并且如果位置不对的话任何错误的输入都应中止。
- REPLACE(替换)
通过中止错误的输入并输出针对该CharsetEncoder定义的当前的替换字节序列处理编码错误。