【实践】端到端的OCR:验证码识别
- 去噪+二值化
- 字符分割
- 每个字符识别
验证码的难度在这3步上都有反应。比如
- 噪声:加一条贯穿全图的曲线,比如网格线,还有图的一半是白底黑字,另一半是黑底白字。
- 分割:字符粘连,7和4粘在一起。
- 识别:字符各种扭曲,各种旋转。
但相对而言,难度最大的是第2步,分割。所以就有人想,我能不能不做分割,就把验证码给识别了。深度学习擅长做端到端的学习,因此这个不分割就想识别的事情交给深度学习是最合适的。
基于CNN的验证码识别
基于CNN去识别验证码,其实就是一个图片的多标签学习问题。比如考虑一个4个数字组成的验证码,那么相当于每张图就有4个标签。那么我们把原始图片作为输入,4个标签作为输出,扔进CNN里,看看能不能收敛就行了。
下面这段代码定义了mxnet上的一个DataIter,我们用了python-captcha这个库来自动生成训练样本,所以可以假设训练样本是无穷多的。
class OCRIter(mx.io.DataIter):
def __init__(self, count, batch_size, num_label, height, width):
super(OCRIter, self).__init__()
self.captcha = ImageCaptcha(fonts=['./data/OpenSans-Regular.ttf'])
self.batch_size = batch_size
self.count = count
self.height = height
self.width = width
self.provide_data = [('data', (batch_size, 3, height, width))]
self.provide_label = [('softmax_label', (self.batch_size, num_label))]
def __iter__(self):
for k in range(self.count / self.batch_size):
data = []
label = []
for i in range(self.batch_size):
# 生成一个四位数字的随机字符串
num = gen_rand()
# 生成随机字符串对应的验证码图片
img = self.captcha.generate(num)
img = np.fromstring(img.getvalue(), dtype='uint8')
img = cv2.imdecode(img, cv2.IMREAD_COLOR)
img = cv2.resize(img, (self.width, self.height))
cv2.imwrite("./tmp" + str(i % 10) + ".png", img)
img = np.multiply(img, 1/255.0)
img = img.transpose(2, 0, 1)
data.append(img)
label.append(get_label(num))
data_all = [mx.nd.array(data)]
label_all = [mx.nd.array(label)]
data_names = ['data']
label_names = ['softmax_label']
data_batch = OCRBatch(data_names, data_all, label_names, label_all)
yield data_batch
def reset(self):
pass
下面这段代码是网络结构:
def get_ocrnet():
data = mx.symbol.Variable('data')
label = mx.symbol.Variable('softmax_label')
conv1 = mx.symbol.Convolution(data=data, kernel=(5,5), num_filter=32)
pool1 = mx.symbol.Pooling(data=conv1, pool_type="max", kernel=(2,2), stride=(1, 1))
relu1 = mx.symbol.Activation(data=pool1, act_type="relu")
conv2 = mx.symbol.Convolution(data=relu1, kernel=(5,5), num_filter=32)
pool2 = mx.symbol.Pooling(data=conv2, pool_type="avg", kernel=(2,2), stride=(1, 1))
relu2 = mx.symbol.Activation(data=pool2, act_type="relu")
conv3 = mx.symbol.Convolution(data=relu2, kernel=(3,3), num_filter=32)
pool3 = mx.symbol.Pooling(data=conv3, pool_type="avg", kernel=(2,2), stride=(1, 1))
relu3 = mx.symbol.Activation(data=pool3, act_type="relu")
flatten = mx.symbol.Flatten(data = relu3)
fc1 = mx.symbol.FullyConnected(data = flatten, num_hidden = 512)
fc21 = mx.symbol.FullyConnected(data = fc1, num_hidden = 10)
fc22 = mx.symbol.FullyConnected(data = fc1, num_hidden = 10)
fc23 = mx.symbol.FullyConnected(data = fc1, num_hidden = 10)
fc24 = mx.symbol.FullyConnected(data = fc1, num_hidden = 10)
fc2 = mx.symbol.Concat(*[fc21, fc22, fc23, fc24], dim = 0)
label = mx.symbol.transpose(data = label)
label = mx.symbol.Reshape(data = label, target_shape = (0, ))
return mx.symbol.SoftmaxOutput(data = fc2, label = label, name = "softmax")
上面这个网络要稍微解释一下。因为这个问题是一个有顺序的多label的图片分类问题。我们在fc1的层上面接了4个Full Connect层(fc21,fc22,fc23,fc24),用来对应不同位置的4个数字label。然后将它们Concat在一起。然后同时学习这4个label。目前用上面的网络训练,4位数字全部预测正确的精度可以达到95%左右(因为是无穷多的训练样本,所以只要能不断训练下去,精度还是可以提高的,只是我训练到95%左右就停止训练了)。
用CNN解决验证码识别有个问题,就是必须针对固定长度的验证码去做。如果长度不固定,或者是手写一行字的识别这种长度肯定不固定的问题,CNN就没办法了。这个时候就需要引入序列学习的模型了。
基于LSTM+CTC的验证码识别
LSTM+CTC被广泛的用在语音识别领域把音频解码成汉字,从这个角度说,OCR其实就是把图片解码成汉字,并没有太本质的区别。而且在整个过程中,不需要提前知道究竟要解码成几个字。
这个算法的思路是这样的。假设要识别的图片是80x30的图片,里面是一个长度为k的数字验证码。那么我们可以沿着x轴对图片进行切分,切成n个图片,作为LSTM的n个输入。在最极端的例子里,n=80。那么就是把图片的每一列都作为输入。LSTM有n个输入就会有n个输出,而这n个输出可以通过CTC计算和k个验证码标签之间的Loss,然后进行反向传播。
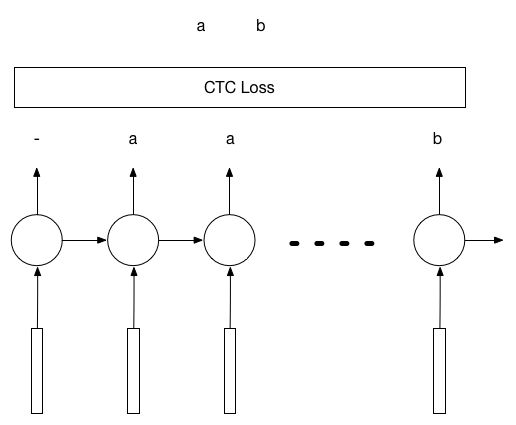 我们同样用python-captcha自动生成验证码作为训练样本,用如下的代码来定义网络结构:
我们同样用python-captcha自动生成验证码作为训练样本,用如下的代码来定义网络结构:
def lstm_unroll(num_lstm_layer, seq_len,
num_hidden, num_label):
param_cells = []
last_states = []
for i in range(num_lstm_layer):
state = LSTMState(c=mx.sym.Variable("l%d_init_c" % i),
h=mx.sym.Variable("l%d_init_h" % i))
last_states.append(state)
assert(len(last_states) == num_lstm_layer)
# embeding layer
data = mx.sym.Variable('data')
label = mx.sym.Variable('label')
wordvec = mx.sym.SliceChannel(data=data, num_outputs=seq_len, squeeze_axis=1)
hidden_all = []
for seqidx in range(seq_len):
hidden = wordvec[seqidx]
for i in range(num_lstm_layer):
next_state = lstm(num_hidden, indata=hidden,
prev_state=last_states[i],
param=param_cells[i],
seqidx=seqidx, layeridx=i)
hidden = next_state.h
last_states[i] = next_state
hidden_all.append(hidden)
hidden_concat = mx.sym.Concat(*hidden_all, dim=0)
pred = mx.sym.FullyConnected(data=hidden_concat, num_hidden=11)
label = mx.sym.Reshape(data=label, target_shape=(0,))
label = mx.sym.Cast(data = label, dtype = 'int32')
sm = mx.sym.WarpCTC(data=pred, label=label, label_length = num_label, input_length = seq_len)
return sm
这里有2点需要注意的:
- 在一般的mxnet的lstm实现中,label需要转置,但是在warpctc的实现中不需要。
- label需要是int32的格式,需要cast。
关于CTC Loss的重要性,我试过不用CTC的两个不同想法:
- 用encode-decode模式。用80个输入做encode,然后decode成4个输出。实测效果很差。
- 4个label每个copy20遍,从而变成80个label。实测也很差。
用ctc loss的体会就是,如果input的长度远远大于label的长度,比如我这里是80和4的关系。那么一开始的收敛会比较慢。在其中有一段时间cost几乎不变。此刻一定要有耐心,最终一定会收敛的。在ocr识别的这个例子上最终可以收敛到95%的精度。