《李宏毅机器学习》-task4
《李宏毅机器学习》-task4
- 1.贝叶斯公式
- 2.先验概率
- 3.后验概率
- 4.逻辑回归和线性回归的联系与区别
- 参考文献
1.贝叶斯公式

(1)条件概率公式
设A,B是两个事件,且P(B)>0,则在事件B发生的条件下,事件A发生的条件概率(conditional probability)为:
P(A|B)=P(AB)/P(B)
(2)乘法公式
1.由条件概率公式得:
P(AB)=P(A|B)P(B)=P(B|A)P(A)
上式即为乘法公式;
2.乘法公式的推广:对于任何正整数n≥2,当P(A1A2...An-1) > 0 时,有:
P(A1A2...An-1An)=P(A1)P(A2|A1)P(A3|A1A2)...P(An|A1A2...An-1)
(3)全概率公式
1. 如果事件组B1,B2,.... 满足
1.B1,B2....两两互斥,即 Bi ∩ Bj = ∅ ,i≠j , i,j=1,2,....,且P(Bi)>0,i=1,2,....;
2.B1∪B2∪....=Ω ,则称事件组 B1,B2,...是样本空间Ω的一个划分
设 B1,B2,...是样本空间Ω的一个划分,A为任一事件,则:

上式即为全概率公式(formula of total probability)
(4)贝叶斯公式
1.与全概率公式解决的问题相反,贝叶斯公式是建立在条件概率的基础上寻找事件发生的原因(即大事件A已经发生的条件下,分割中的小事件Bi的概率),设B1,B2,...是样本空间Ω的一个划分,则对任一事件A(P(A)>0),有
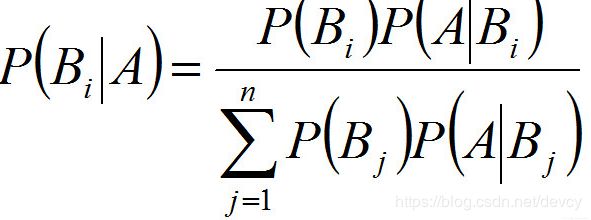
上式即为贝叶斯公式(Bayes formula),Bi 常被视为导致试验结果A发生的”原因“,P(Bi)(i=1,2,...)表示各种原因发生的可能性大小,故称先验概率;P(Bi|A)(i=1,2...)则反映当试验产生了结果A之后,再对各种原因概率的新认识,故称后验概率。
2.实例:发报台分别以概率0.6和0.4发出信号“∪”和“—”。由于通信系统受到干扰,当发出信号“∪”时,收报台分别以概率0.8和0.2受到信号“∪”和“—”;又当发出信号“—”时,收报台分别以概率0.9和0.1收到信号“—”和“∪”。求当收报台收到信号“∪”时,发报台确系发出“∪”的概率。
解:设...., P(B1|A)= (0.6*0.8)/(0.6*0.8+0.4*0.1)=0.923
2.先验概率
先验(Apriori;又译:先天)在拉丁文中指“来自先前的东西”,或稍稍引申指“在经验之前”。近代西方传统中,认为先验指无需经验或先于经验获得的知识。它通常与后验知识相比较,后验意指“在经验之后”,需要经验。这一区分来自于中世纪逻辑所区分的两种论证,从原因到结果的论证称为“先验的”,而从结果到原因的论证称为“后验的”。
先验概率:是指根据以往经验和分析得到的概率
意思是说我们人有一个常识,比如骰子,我们都知道概率是1/6,而且无数次重复实验也表明是这个数,这是一种我们人的常识,也是我们在不知道任何情况下必然会说出的一个值.而所谓的先验概率是我们人在未知条件下对事件发生可能性猜测的数学表示!*
3.后验概率
后验概率是在考虑了一个事实之后的条件概率. 先验概率通常是经验丰富的专家的纯主观的估计.
后验概率:事情已经发生,要求这件事情发生的原因是由某个因素引起的可能性的大小
举个栗子:
首先我想问一个问题,桌子上如果有一块肉喝一瓶醋,你如果吃了一块肉,然后你觉得是酸的,那你觉得肉里加了醋的概率有多大?你说:80%可能性加了醋.OK,你已经进行了一次后验概率的猜测.没错,就这么简单.
我们设A为加了醋的概率,B为吃了之后是酸的概率.C为肉变质的概率


4.逻辑回归和线性回归的联系与区别
1.逻辑回归和线性回归都是广义的线性回归
2.线性回归中使用的是最小化平方误差损失函数,对偏离真实值越远的数据惩罚越严重。逻辑回归使用对数似然函数进行参数估计,使用交叉熵作为损失函数,对预测错误的惩罚是随着输出的增大,逐渐逼近一个常数。正是因为使用的参数估计的方法不同,线性回归模型更容易受到异常值(outlier)的影响。
3.LR在线性回归的实数范围输出值上施加sigmoid函数将值收敛到0~1范围, 其目标函数也因此从差平方和函数变为对数损失函数, 以提供最优化所需导数(sigmoid函数是softmax函数的二元特例, 其导数均为函数值的f*(1-f)形式)。请注意, LR往往是解决二元0/1分类问题的, 只是它和线性回归耦合太紧, 不自觉也冠了个回归的名字(马甲无处不在). 若要求多元分类,就要把sigmoid换成大名鼎鼎的softmax了。
4.线性回归的输出是时域上的连续值,逻辑回归的输出被sigmoid函数映射到[0, 1],通过设置阈值转换成分类类别。
附:LR和SVM的关系
1、LR和SVM都可以处理分类问题,且一般都用于处理线性二分类问题(在改进的情况下可以处理多分类问题)
2、两个方法都可以增加不同的正则化项,如l1、l2等等。所以在很多实验中,两种算法的结果是很接近的。
区别:
1、LR是参数模型,SVM是非参数模型。
2、从目标函数来看,区别在于逻辑回归采用的是logistical loss,SVM采用的是hinge loss,这两个损失函数的目的都是增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重。
3、SVM的处理方法是只考虑support vectors,也就是和分类最相关的少数点,去学习分类器。而逻辑回归通过非线性映射,大大减小了离分类平面较远的点的权重,相对提升了与分类最相关的数据点的权重。
4、逻辑回归相对来说模型更简单,好理解,特别是大规模线性分类时比较方便。而SVM的理解和优化相对来说复杂一些,SVM转化为对偶问题后,分类只需要计算与少数几个支持向量的距离,这个在进行复杂核函数计算时优势很明显,能够大大简化模型和计算。
5、logic 能做的 svm能做,但可能在准确率上有问题,svm能做的logic有的做不了。
5.推导sigmoid公式
参考文献
https://blog.csdn.net/jiaoyangwm/article/details/81139362
https://www.cnblogs.com/ohshit/p/5629581.html