kibana对Elasticsearch做增删改查操作,以及一些聚合查询
kibana是一个可视化平台,设计出来用于和Elasticsearch一起使用的。你可以用kibana搜索、查看、交互存放在Elasticsearch索引里的数据。
准备工作:Elasticsearch启动完毕,elasticsearch-head启动完毕 kibana 启动完毕
然后访问http://localhost:5601,点击Dev Tools,就是以下图片的界面.
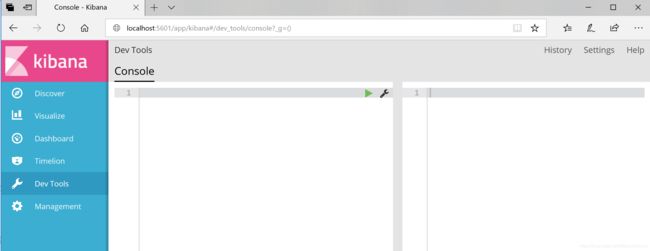
然后我们就可以对Elasticsearch做增删改查数据的操作了
1.先添加索引也就是数据库的库名
PUT test_data
{
"settings": {
"index":{
"number_of_shards":5,
"number_of_replicas":1
}
}
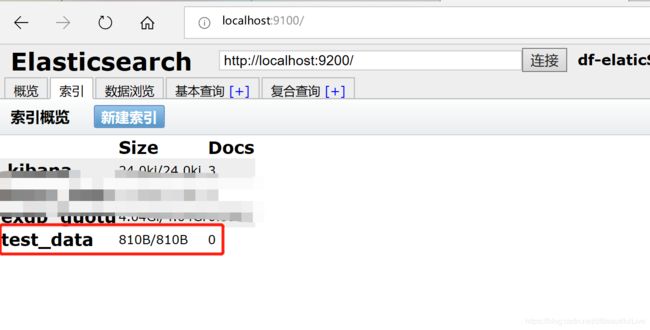
}添加成功,会在Elasticsearch-head 中查看是否多出来一个索引
2.继续添加类型和数据
#test_data索引名称,相当于数据库名称
#product 类型,相当于数据库的表名
#1就是要存储数据的id,不写的话默认给一个长字符串
PUT test_data/product/1
{
"name":"华为电脑",
"address":"深圳",
"price":9600,
"creat_time":"2019-01-02"
}Elasticsearch-head就有数据了

3.修改某个字段的数据
#修改
POST test_data/product/3/_update
{
"doc":{
"price":5835
}
}4.删除一条记录
#删除
DELETE test_data/product/35.删除index,删除整个库
#删除索引
DELETE test_data6. 获取设置信息
GET test_data/_settings7.获取所有的设置
GET _all/_settings这样一个简单的增删改查就弄好了
接下来用添加好的数据做一些简单的聚合分析,一些统计,求最大数,最小数,平均值等等
1.根据商品名称计算每个商品数量
#计算每种电脑有多少数量
GET test_data/product/_search
{
"size": 0,
"aggs": {
"group_by_name": {
"terms": {
"field": "name.keyword"
}
}
}
}
#size:只获取聚合结果,而不执行聚合原始数据
#aggs:固定语法,要对一份数据执行分组聚合操作
#group_by_name:就是对每个aggs,都要起一个名字,这个名字是随机的,你随便取什么都ok
#terms:根据字段的值进行分组
#field:根据指定的字段的值进行分组
对返回的数据分析
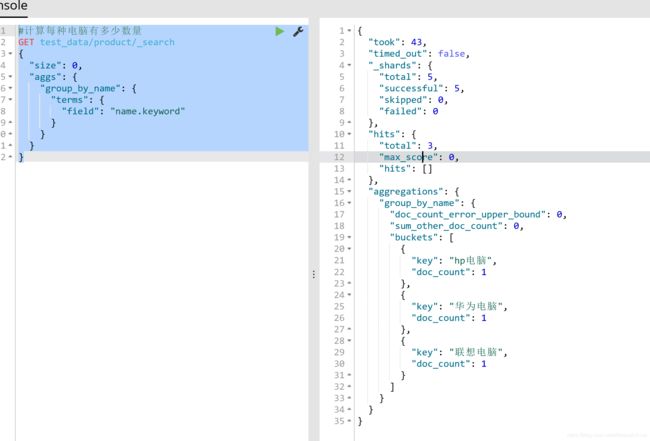
hits.hits:指定了size是0,所以hits.hits为空,否则会把执行聚合的那些原始数据给你返回回来
aggregations:聚合结果 group_by_name:我们指定的某个聚合的名称
buckets:根据我们指定的field划分出的buckets key:每个bucket对应的那个值
doc_count:这个bucket分组内,有多少个数据 默认的排序规则:按照doc_count降序排序
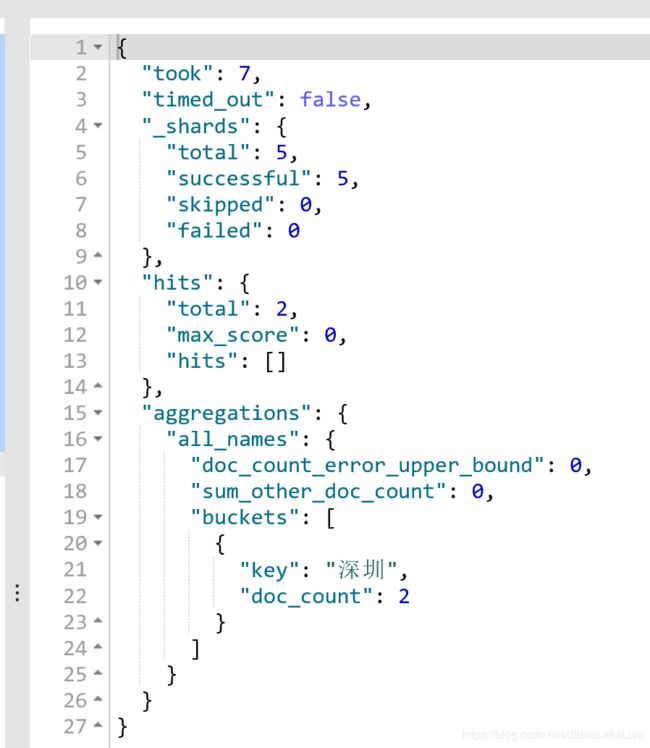
2.计算北京地区,统计地址的数量
#计算北京地区,统计地址的数量
GET test_data/product/_search
{
"size": 0,
"query": {
"match": {
"address": "深圳"
}
},
"aggs": {
"all_names": {
"terms": {
"field": "address.keyword"
}
}
}
}返回的数据
3.计算每个商品下的平均价格/最小价格/最大价格/总价
#计算北京地区,统计地址的数量
GET test_data/product/_search
{
"size": 0,
"aggs": {
"group_by_names":{
"terms": {"field": "name.keyword"},
"aggs": {
"avg_price":{"avg": {"field": "price"}},
"min_price":{"min": {"field": "price"}},
"max_price":{"max": {"field": "price"}},
"sum_price":{"sum": {"field": "price"}}
}
}
}
}
#count:buckets,terms,自动就会有一个doc_count,就相当于是count
#avg:avg aggs 求平均值
#max:求一个bucket内,指定field值最大的那个数据
#min:求一个bucket内,指定field值最小的那个数据
#sum:求一个bucket内,指定field值的总和先分组,再算每组的平均值返回结果
avg_price:我们自己取的metric aggs的名字
value:我们的metric计算的结果,每个bucket中的数据的price字段求平均值后的结果
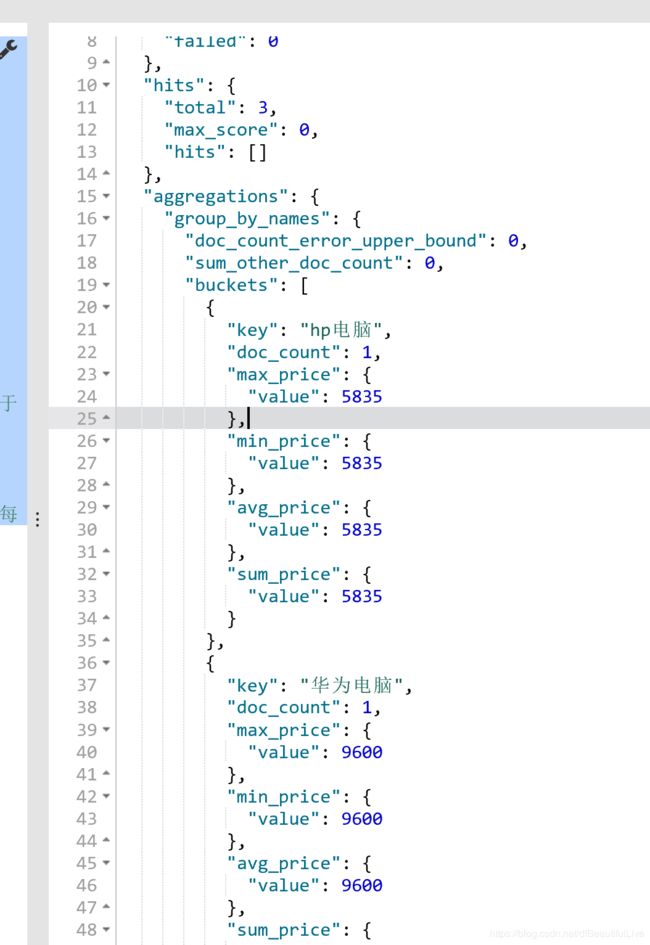
4.计算商品下的平均价格,并且按照平均价格降序排列
collect_mode
对于子聚合的计算,有两种方式:
- depth_first 直接进行子聚合的计算
- breadth_first 先计算出当前聚合的结果,针对这个结果在对子聚合进行计算。
"order": { "avg_price": "desc" }
#计算商品下的平均价格,并且按照平均价格降序排列
GET test_data/product/_search
{
"size": 0,
"aggs": {
"all_names":{
"terms": { "field": "name.keyword","collect_mode": "breadth_first","order": {
"avg_price": "desc"}},
"aggs": {
"avg_price": {
"avg": {"field": "price"}
}
}
}
}
}
返回结果

5.按照指定的价格范围区间进行分组,然后在每组内再按照name进行分组,最后再计算每组的平均价格
"ranges": [{},{}]
#按照指定的价格范围区间进行分组,然后在每组内再按照name进行分组,最后再计算每组的平均价格 ranges:[{}]
GET test_data/product/_search
{
"size": 0,
"aggs": {
"group_by_price":{
"range": {
"field": "price",
"ranges": [
{
"from": 50,
"to": 4000
}
]
},
"aggs": {
"group_by_names": {
"terms": {
"field": "name.keyword"
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
}
}
返回结果

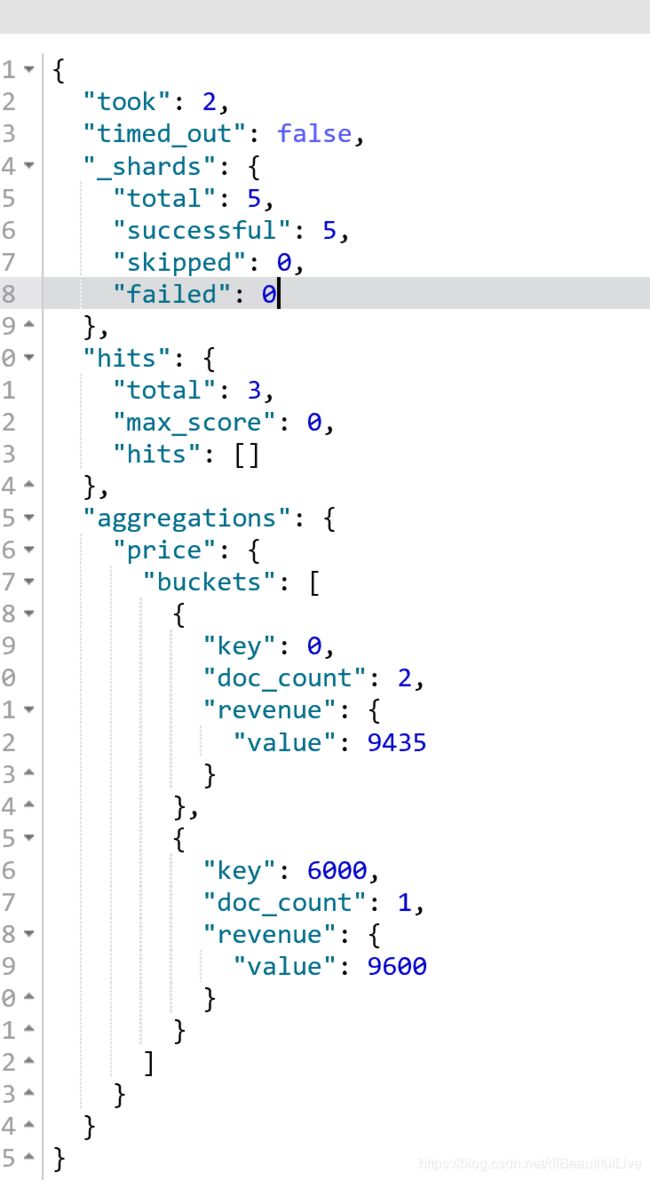
6.histogram
类似于terms,也是进行bucket分组操作,接收一个field,按照这个field的值的各个范围区间,进行bucket分组操作
interval:10,划分范围,0~10,10~20,20~30
#histogram
GET test_data/product/_search
{
"size": 0,
"aggs": {
"price":
{
"histogram": {
"field": "price",
"interval": 6000
},
"aggs": {
"revenue": {
"sum": {
"field": "price"
}
}
}
}
}
}
返回结果
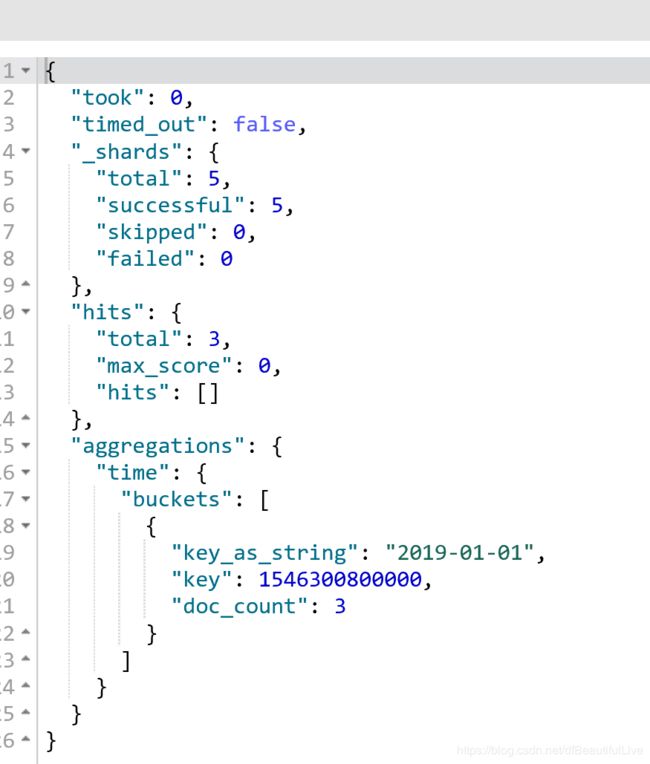
7.date histogram
按照我们指定的某个date类型的日期field,以及日期interval,按照一定的日期间隔,去划分bucket
date interval = 1m, 2017-01-01~2017-01-31,就是一个bucket 2017-02-01~2017-02-28,就是一个bucket
然后会去扫描每个数据的date field,判断date落在哪个bucket中,就将其放入那个bucket
min_doc_count:即使某个日期interval,2017-01-01~2017-01-31中,一条数据都没有,那么这个区间也是要返回的,不然默认是会过滤掉这个区间的
min_doc_count:即使某个日期interval,2017-01-01~2017-01-31中,一条数据都没有,那么这个区间也是要返回的,不然默认是会过滤掉这个区间的
GET test_data/product/_search
{
"size": 0,
"aggs": {
"time":{
"date_histogram": {
"field": "creat_time",
"interval": "month",
"format": "yyyy-MM-dd",
"min_doc_count": 0,
"extended_bounds":{
"min":"2019-01-01",
"max":"2019-01-02"
}
}
}
}
}
返回数据
8.global
就是global bucket,就是将所有数据纳入聚合的scope,而不管之前的query
GET test_data/product/_search
{
"size": 0,
"query": {
"term": {
"brand": {
"value": "华为电脑"
}
}
},
"aggs": {
"single_brand_avg_price": {
"avg": {
"field": "price"
}
},
"all":{
"global": {},
"aggs": {
"all_brand_avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
#single_brand_avg_price:就是针对query搜索结果,执行的,拿到的,就是华为电脑的平均价格
#all.all_brand_avg_price:拿到所有品牌的平均价格返回结果
