AMD正式发布了这款采用革命性HBM显存的全球首款公版水冷显卡,这款卡实在是太过惊艳,惊艳了业界也惊艳了我。过了一年,AMD发布了采用14nm的Polaris显卡,在业界掀起了红色革命,AMD的独显市场份额也从2成上升到了3成。又过了一年,AMD终于在今年7月发布了久违的旗舰级显卡——RADEON RX VEGA 64/56,众多A饭翘首期盼的AMD卡皇终于降世了!

此时此刻,距离AMD上一代基于Fiji(斐济)核心的旗舰显卡Radeon R9 Fury X诞生已经过去了两年零一个多月的时间,这在以往是非常不可思议的。
尤其是过去一年多来,NVIDIA Pascal家族逐次推进,从高到低完整覆盖,AMD方面虽然也有全新的Polaris(北极星)核心,但毕竟是个小核心,在中低端市场上表现稳健,却没有一位老大哥带头,总是缺乏底气。
Vega核心最早的说法是2016年10月份就会登场,但在众多玩家尤其是A饭们的焦急等待中,又是十个月过去了,Vega才终于瓜熟蒂落,而此时距离其主要竞争对手GTX 1080/1070的诞生,也已经有一年零三个月之久了。
对于Vega为何迟到这么久,AMD高级副总裁兼Radeon技术事业部首席架构师Raja Koduri对我们解释说:
一是14nm工艺,这是AMD第一次同时在CPU和GPU上使用同一种工艺。
二是Vega架构是全新设计的,从底层开始都焕然一新,而如今设计一种全新的高性能计算架构,不但要做好高端游戏,还要满足图形工作站、高性能计算、机器学习等各方面的需求。
当然,AMD作为唯一一家同时拥有高性能CPU、GPU计算平台的企业,本身并不是多么财大气粗,同时面临Intel、NVIDIA两大可以分别专注一个领域的强敌,可以说相当不易,走过的每一步都值得尊重。

回来再说Vega,作为一个全新设计的高性能核心,它肩上的担子是相当重的,玩游戏也只是一个方面,它要做的事儿多着呢。
事实上在此之前,Vega家族已经逐渐开始生根发芽,甚至可以说逐渐枝繁叶茂了。
在服务器和高性能计算领域,我们见到了Radeon Instinct MI25,直面NVIDIA Tesla系列,完美搭档自家EPYC服务器处理器;
在图形工作站领域,我们有了Radeon Pro WX 9100、Radeon Pro SSG,不但竞争NVIDIA Quadro系列,后者还首创了显卡集成SSD,容量高达2TB,后续据称还有Radeon Pro 64/56;
在游戏开发领域,Radeon Vega Frontier Edition风冷版、水冷版大家也都不陌生了,这也是AMD对于NVIDIA Titan X/Xp的一个回应;
在游戏领域,AMD也是卯足了劲,首发就有三款产品(也可以说四款),而且后续还有更多惊喜!

【Vega架构解析:AMD GPU五年来最革命性进步】
不知不觉,Radeon这个显卡品牌已经诞生17年了,也伴随太多DIYer走过了青春岁月,而时代在变化,Radeon面临的需求也越发多样化。
AMD在技术白皮书中特别指出,除了传统游戏不断冲击视觉技术极限,GPU还面临着更广泛需求的挑战,从机器学习到专业视觉化,从虚拟化到虚拟现实,GPU的计算能力也在快速跟上,以满足超大数据集的需求,但是GPU存储能力并未得到显著提升。
为此,AMD全新设计了Vega架构,这也是GCN图形架构诞生五年以来,AMD GPU最革命性的变化。

不过,新核心的变化实在太多了,涉及几乎所有方面,而且很多都过于专业,所以这里我们之挑选其中几个要点和大家分享。
1、Vega 10:高集成度的大核心
Vega架构的第一个产品是“Vega 10”,一个相对大规模的芯片,面向高分辨率游戏、VR虚拟现实、高性能计算和机器学习、高负载工作站等领域。
它采用14nm LPP FinFET工艺制造,集成了125亿个晶体管,核心面积486平方毫米。
相比之下,28nm工艺的上代大核心Fiji集成了89亿个晶体管,面积却有596平方毫米,也就是说Vega 10核心晶体管规模多了整整40%,面积却缩小了18%!
另外,同样14nm工艺的Polaris 10核心集成57亿个晶体管,核心面积232平方毫米,Vega 10与之相比晶体管多了1.2倍,面积增大了1.1倍,集成度也有所提高。
Vega 10核心经过优化后,可以充分利用FinFET工艺的低漏电率优势,频率也高于以往任何Radeon显卡,官方标称最高加速频率就有1.67GHz,而实际运行中完全可以超过1.7GHz,实测中甚至见到过1.75GHz。
相比之下,上代Fiji核心最多只能加速到1GHz左右,Polaris 10最高则是超过1.3GHz。
Raja表示,14nm工艺对CPU和GPU来说都很平衡,在CPU上可以实现高频率,GPU上则可以实现高集成度,比如Vega就因此比Fiji核心要小得多,但是性能高出很多。
Vega 10核心依然有64个计算单元、4096个流处理器,规模上和Fiji是一样的,但凭借高进的架构和更高的频率,单精度浮点计算性能达到了惊人的13.7TFlops(每秒13.7万亿次计算),而且还支持16位数学计算,半精度浮点性能达27.4TFlops。
Vega 10还是AMD第一个使用了Infinity Fabric互连设计的GPU核心,也就是Zen处理器里的那一套。这种低延迟的SoC型互连总线可以在芯片的不同模块之间提供一致性通信,也使得芯片设计更加弹性灵活,可以做到模块化,能随时根据需要加入不同配置和模块。
Vega 10芯片中,Infinity Fabric连接着图形核心与其他主要逻辑模块,包括显存控制器、PCI-E控制器、显示引擎、视频加速器等等,也为未来的APU奠定了基础。

2、全新显存架构和高带宽缓存控制器(HBCC)
GPU通常需要在本地显存中保存所需要数据集或者资源的全部,因为走PCI-E等外部通道的话,将无法保证足够的带宽或延迟。
随着软件内存管理的日益复杂,这对开发者提出了越来越高的挑战,而显存成本又决定了不可能把容量做到特别大。
为此,Vega架构可以将本地显存作为末级缓存使用。如果GPU要访问的部分数据不在显存之内,可以通过PCI-E总线获取所需内存页面,并保存在高带宽缓存中,而不是让GPU停下来,等待完成全部所需资源的复制。
页面通常比整个纹理等资源小得多,复制可以迅速完成,后续访问就直接从缓存中拉取,延迟自然非常低。
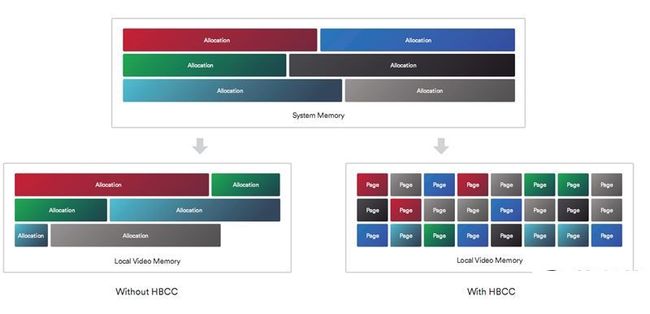
这主要得益于Vega架构新增的高带宽缓存控制器(HBCC),可以将远程内存作为本地缓存使用,同时可以将本地显存作为末级缓存使用。
HBCC支持49位寻址,最多能访问512TB虚拟寻址空间,而现代CPU的寻址空间也不过48位,同时比最多10+GB的显存也多了几个数量级。

HBCC被视为Vega架构中最大的革新,简单地说可以把整个系统内存当做显存来使用,相当于一块显卡可以拥有TB级别的高速显存,无论性能还是容量都不是事儿。
换言之,它实现了某种程度上的一体化内存池,这部分AMD称之为“HBCC内存区”(HMS)。
Radeon Pro SSG之所以能板载2TB SSD,就是得益于这种设计,消除了从GPU到SSD之间的隔阂,可以直接访问其中的数据,从而大大降低延迟和过载。
为了将这种设计发挥到极致,Vega架构其他部分也做了针对性调整,比如说二级缓存就扮演着中心角色,容量翻番到4MB,所有图形区块都直接与其相连,而以往像素引擎是有自己的缓存的。
当然,HBCC设计也需要开发者去学习适应,才能挖掘和释放其最大潜力,而且它也不是必须使用的,开发者如果对显存容量和性能没有特别高的要求,仍然可以走传统路线。
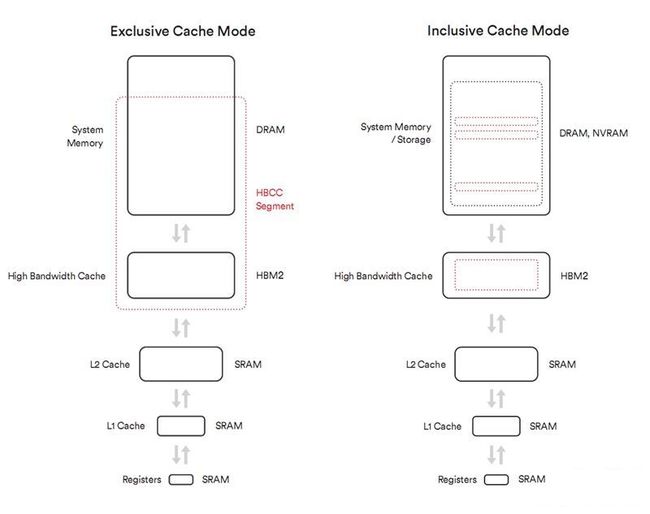
显存方面,Vega搭配了第二代高带宽显存HBM2,类似Fiji那样与GPU核心整合封装,使用硅中介层与GPU物理互连。
得益于新的技术和工艺,HBM2最多可以堆叠8个,单颗容量最大8GB,Vega专业卡就用了两颗供16GB,RX Vega家族则配备了两颗供8GB。
同时,HBM2每个堆栈的位宽达1024-bit,因此只需很低的频率,就能提供极高的带宽。
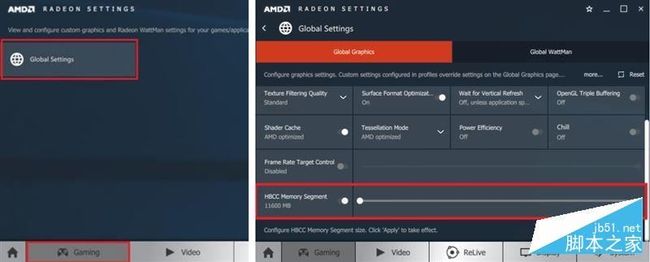
在显卡驱动控制面板中,用户可以根据自己的需要,手动调整HMS的容量范围。
3、下一代计算单元(NCU)
AMD GCN架构的核心模块是计算单元(CU),Vega也是如此,但同样做了全面翻新,官方称之为下一代计算单元(NCU)。

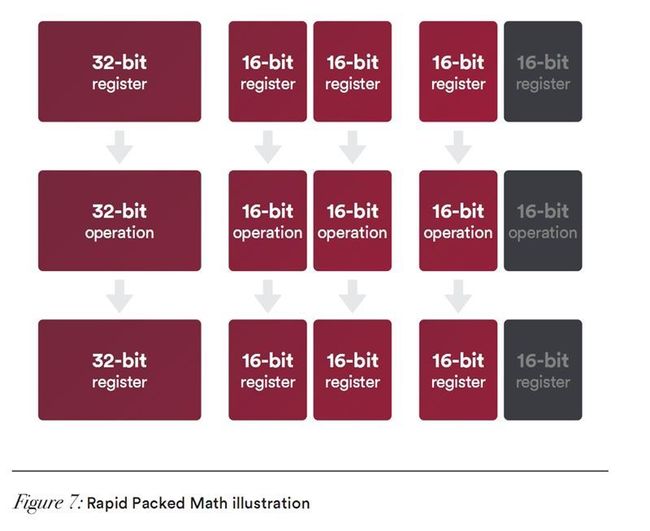
NCU的一个亮点变化就是加入了快速堆叠运算(Rapid Packed Math/RPM),允许两个FP16半精度的运算同时执行,并支持丰富的16位浮点和整数指令集,包括FMA、MUL、ADD、MIN/MAX/MED、Bit Shift等等。
一般来说,日常游戏、3D渲染对单精度FP32、双精度FP64要求比较高,而在大规模深度计算中,FP16半精度十分关键。
Vega首次支持半精度计算,每个NCU拥有64个ALU,可以灵活地执行紧缩数学操作指令,比如每个周期可执行512个8位数学计算,或者256个16位计算,或者128个32位计算。这不仅充分利用了硬件资源,也能大幅度提升Vega在深度学习上的性能。

RPM专门用于加速FP16半精度的运算速度,比如新的着色器可以利用RPM,在AMD一直引以为傲的TressFX毛发渲染中,将每秒能渲染的头发数量增加一倍,因此,RPM可以帮助GPU核心进行更快更强的的物理计算。
NCU还可以同时进行计算和图形处理,并且能够根据负载不同而变换SIMD单元宽度,结果就是以往需要多个计算单元才能完成的任务,现在只需一个就能搞定,不会造成浪费。
种种改进结合,Vega 10核心可以每秒钟执行27万亿次浮点计算,或者55万亿次整数操作。
4、下一代几何引擎
Vega的整个几何引擎针对更高三角形吞吐量做了优化,增加了新的快速硬件路径,比以往更有弹性、可编程性。
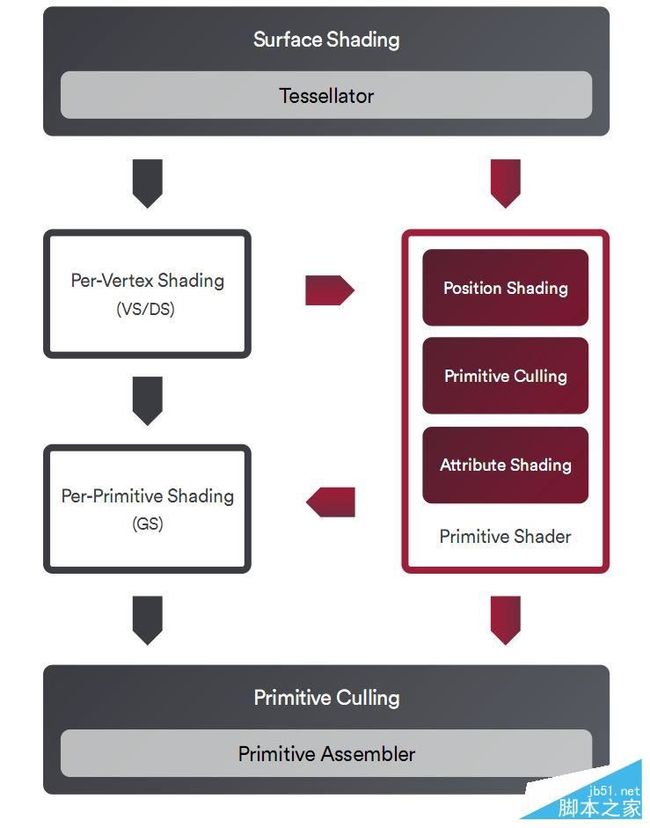
Vega几何引擎里的创新很多,最具代表性的当属新的原语着色器(Primitive Shader),可以合并部分几何处理流水线,抛弃隐藏的、没必要的原语,代之以新的高效着色类型,而且启动非常快,每时钟周期的峰值原语剔除率是以前的四倍。
Vega 10拥有四个几何引擎,加入了新的原语着色器之后,每时钟周期的最大原语吞吐量可以超过17个,而以前只能做到4个。
同时,Vega架构还加入了新的智能负载分配器(IWD),可以根据实际情况持续调整流水线设定,更好地平衡各个几何引擎之间的负载,提高利用率。
5、下一代像素引擎
随着4K/5K/8K超高分辨率和240Hz高刷新率显示器的出现和普及,以及VR虚拟现实的进一步发展,显卡像素吞吐能力也面临着越来越大的压力,Vega为此重新设计了像素引擎,加入了大量新功能。