天坑填坑
set([iterable])
| 函数 | 功能 |
|---|---|
| set() | 返回无序元素集合,①删除重复数据,可以计算②交集&、差集-、并集丨**等 |
x = set('aaaaa')
y = set('abcd')
x-->{'a'} 去掉重复的a
y-->{'abcd'}
x&y -->{'a'} 交集
y-x -->{'c', 'b', 'd'} 差集
x-y -->{} 差集
x|y -->{'c', 'b', 'a', 'd'} 并集
'无序,返回为set类型'
================================================================
eval(source[, globals[, locals]])
| 函数 | 功能 |
|---|---|
| eval() | 只能输入字符串,返回计算结果或者字符串!①去掉引号(脱掉字符串的引号);②全局变量globals(字典),局部变量locals(map),同时存在时候,局部变量做主,任意一种变量出现都是大哥,得听大哥的 |
'1' :a = "[[1,2], [3,4], [5,6], [7,8], [9,0]]"
b = eval(a)
type(b)
--><class 'str'>
'2':
x = 1 '全局变量xy'
y = 1
num1 = eval("x+y")
print ('num1',num1)
def g():
x = 2 '局部变量x,y'
y = 2
num2 = eval("x+y")
print ('num2',num2)
num3 = eval("x+y",globals())
print ('num3',num3)
num4 = eval("x+y",globals(),locals())
print ('num4',num4)
g()
num1 2 '运行结果'
num2 4
num3 2
num4 4
'num1中的x+y用的是全局变量xy,结果为1+1'
'num2中的x+y用的是局部变量xy,结果为2+2'
'num3中有全局变量,所以使用全局变量xy,结果为1+1'
'优先级=局部变量>全局变量,所以num4中进行x+y时候,调用的是局部变量xy,结果为4'
================================================================
str.strip([chars])
| .strip() | 去除头尾字符、空白符(包括\n、\r、\t、’ ') |
|---|
'.lstrip()-->去除头部位置括号内的字符'
'.rstrip()-->去除尾部位置括号内的字符'
ex = ' a b c '
r = ex.strip()
print('r', r)
-->r 'a b c' '去掉了头尾的空格,默认括号内不输入要去除的字符就会去掉空等等'
================================================================
简单美学~ ab互换~
a = 1
b = 2
a,b = b,a
a-->2
b-->1
================================================================
2 8 16进制表示转换
2:0b
8:0o
16:0x
0b10 --> 2 2进制
0o10 --> 8 8进制
0x10 --> 16 16进制
'bin()函数 括号内转换为2进制数'
bin(10) --> 0b1010 (10)
bin(0o7) --> 0b111 (7)
bin(0xE) --> 0b1110 (14)
'int()功能函数之一 转换为10进制'
int(0b11) --> 3
int(0o11) --> 9
int(0x11) --> 17
'hex()函数 转为16进制'
hex(32) --> 0x20
hex(0b11) --> 0x3
'oct() 转为8进制'
==================================================================
zip(迭代器)
一次性取出字典中多个key中所对应的value
例1
dic = {'a':['1','2','3'],'b':['4','5','6']}
for x,y in zip(dic['a'],dic['b']):
print(x)
print(y)
print(x,y)
-->
1
4
1 4
2
5
2 5
3
6
3 6
例2
dic = ['asd','qwer','zxcvb'] 各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同
for temp in zip(*dic):
print(temp)
--> 返回为元祖,可以使用 list() 转换来输出列表
('a', 'q', 'z')
('s', 'w', 'x')
('d', 'e', 'c')
==================================================================
‘XXX’.join(a列表)
将a列表中的各个元素用‘XXX’连接起来
不过每个元素必须是字符串
所以可能需要强制转换一下
a = [1,'miss','u']
''.join(a)
-->
Traceback (most recent call last):
File "" , line 1, in <module>
''.join(a)
TypeError: sequence item 0: expected str instance, int found
转换成字符串
b = [str(i) for i in a]
b
-->
['1', 'miss', 'u']
连接
c = ''.join(b)
print(c)
-->
'1missu'
==================================================================
移除列表中你想移除的一切=。=
移除列表中的所有的空白字符串
a = ['',' ','a ',' b']
b = [re.sub(r"\s*",'',i) for i in a] #正则替换所有的空白字符串
print(b)
-->
b = ['', '', 'a', 'b']
while '' in b:
b.remove('')
print(b)
-->
['a', 'b']
==================================================================
Xpath的contains和not
contains
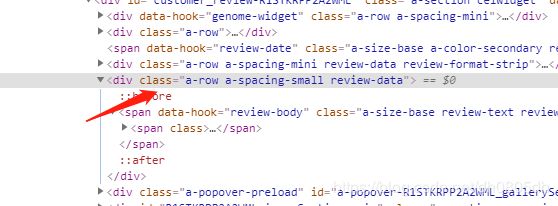
找到所有div标签中class属性为"a-row a-spacing-small review-data"的标签
//div[contains(@class,"a-row a-spacing-small review-data")]
![]()
not

不要标签下的某些标签
//div[@class="a-row"]/a[not(@class="a-link-normal")]
==================================================================
遇到独特的网页编码方式,decode帮你翻译
有时候,有些网站编写的时候会使用不一样的编码,使用requests请求之后的数据再进行.text会看到有乱码
或者直接进入网址源码发现会有一堆乱码
比如这样
这个是某东的某网页源码
所以可以试试
url = '独特编码方式的网址'
res = requests,get(url)
response = res.content,decode('utf8') #某东这里要把utf8换成gbk
返回也是字符串哦
但是如果出现错误
'utf-8' codec can't decode byte 0xbc in position 61: invalid start byte
是解码方式出现了错误。可以尝试换成其他的解码方式,比如说上面这种情况换成’gbk’就可以了。。。
因为gb2312这个里面有很多繁体字和符号是无法被识别的,但是’gbk’的话算是‘gb2312’的扩展包,可以识别很多’gb2312’识别不了的符号和文字。
使用json解码
当然解码方式还是选gbk的。。。
import json,requests
url = '某网站'
res = resquests.get(url)
r = json.loads(str(res.content,encoding='gbk'),encoding='gbk')