使用Docker搭建大数据Hadoop环境
使用Docker搭建大数据Hadoop环境
一、安装Docker
原文地址:https://www.imooc.com/article/48676、http://www.runoob.com/docker/centos-docker-install.html
这是本人第一次用Docker搭建大数据Hadoop环境的步骤,记录在这里:
1. 对于CenterOS7系统,内置Docker,可以直接安装
yum install -y docker
2、启动docker
service docker start
可能会有相关报错:
service docker startRedirecting to /bin/systemctl start docker.serviceJob for docker.service failed because the control process exited with error code. See "systemctl status docker.service" and "journalctl -xe" for details.
第一,firewalld.service没有关闭。
systemctl disable firewalld
systemctl stop firewalld
第二,selinux没有关闭。请查看本机并关闭
vi /etc/selinux/config
修改SELINUX=disabled,如下
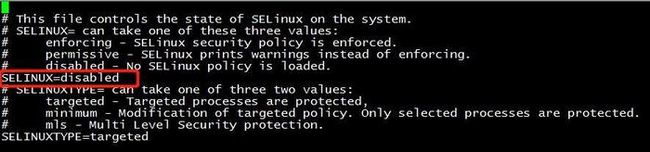
3、reboot重启并查看状态,使用命令:sestatus
启动Docker,很可能需要卸载重装Docker才能启动
yum remove docker
yum install docker
service docker start
测试运行 hello-world
docker run hello-world
这一步可选的:
4、利用Docker获取CentOS镜像,并建立一个容器
1.下载CentOS
docker pull centos #该命令会自动下载最新版本docker官方的centos,目前是7.5
2. 查看镜像
docker images
3.创建容器并启动
docker run --privileged=true -it --name=hadoop centos /bin/bash
#注意,此时你已经进入容器,你会发root@cf869bdd4561的主机名发生变化
二、镜像加速
鉴于国内网络问题,后续拉取 Docker 镜像十分缓慢,我们可以需要配置加速器来解决,我使用的是网易的镜像地址:http://hub-mirror.c.163.com。
新版的 Docker 使用 /etc/docker/daemon.json(Linux) 或者 %programdata%\docker\config\daemon.json(Windows) 来配置 Daemon。
vi /etc/docker/daemon.json
请在该配置文件中加入(没有该文件的话,请先建一个):
{
"registry-mirrors": ["http://hub-mirror.c.163.com"]
}
或者:
{
"registry-mirrors": ["https://registry.docker-cn.com"]
}
#Docker 官方中国区: https://registry.docker-cn.com
#网易: http://hub-mirror.c.163.com
#ustc: https://docker.mirrors.ustc.edu.cn
systemctl restart docker
修改保存后重启 Docker 以使配置生效。
三、搭建hadoop:
原文地址:https://kiwenlau.com/2016/06/12/160612-hadoop-cluster-docker-update/
基于Docker搭建Hadoop集群之升级版
摘要: kiwenlau/hadoop-cluster-docker是去年参加Docker巨好玩比赛开发的,得了二等奖并赢了一块苹果手表,目前这个项目已经在GitHub上获得了236个Star,DockerHub的镜像下载次数2000+。总之,项目还算很受欢迎吧,这篇博客将介绍项目的升级版。
- 作者: KiwenLau
- 日期: 2016-06-12
一. 项目介绍
将Hadoop打包到Docker镜像中,就可以快速地在单个机器上搭建Hadoop集群,这样可以方便新手测试和学习。
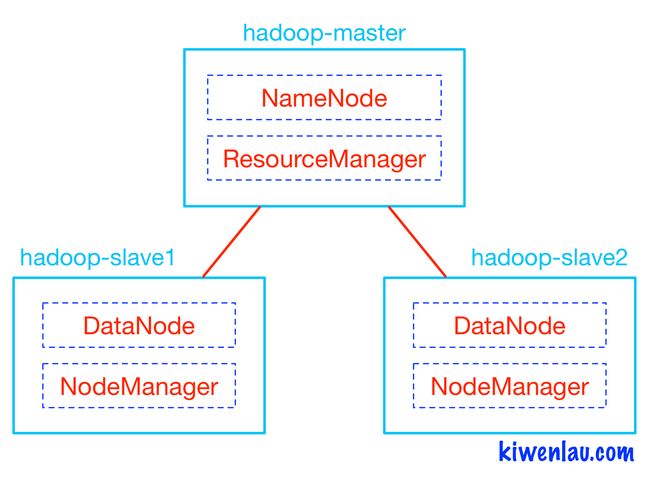
如下图所示,Hadoop的master和slave分别运行在不同的Docker容器中,其中hadoop-master容器中运行NameNode和ResourceManager,hadoop-slave容器中运行DataNode和NodeManager。NameNode和DataNode是Hadoop分布式文件系统HDFS的组件,负责储存输入以及输出数据,而ResourceManager和NodeManager是Hadoop集群资源管理系统YARN的组件,负责CPU和内存资源的调度。
之前的版本使用serf/dnsmasq为Hadoop集群提供DNS服务,由于Docker网络功能更新,现在并不需要了。更新的版本中,使用以下命令为Hadoop集群创建单独的网络:
|
然后在运行Hadoop容器时,使用”–net=hadoop”选项,这时所有容器将运行在hadoop网络中,它们可以通过容器名称进行通信。
项目更新要点:
- 去除serf/dnsmasq
- 合并Master和Slave镜像
- 使用kiwenlau/compile-hadoop项目编译的Hadoo进行安装
- 优化Hadoop配置
二. 3节点Hadoop集群搭建步骤
1. 下载Docker镜像
|
2. 下载GitHub仓库
|
3. 创建Hadoop网络
|
4. 运行Docker容器
|
运行结果
|
- 启动了3个容器,1个master, 2个slave
- 运行后就进入了hadoop-master容器的/root目录
5. 启动hadoop
|
6. 运行wordcount
|
运行结果
|
Hadoop网页管理地址:
- NameNode: http://192.168.59.1:50070/
- ResourceManager: http://192.168.59.1:8088/
192.168.59.1为运行容器的主机的IP。
注意:
如果报错,可能是主机名配置错误,参考文章:https://blog.csdn.net/shirdrn/article/details/6562292,
三. N节点Hadoop集群搭建步骤
1. 准备
- 参考第二部分1~3:下载Docker镜像,下载GitHub仓库,以及创建Hadoop网络
2. 重新构建Docker镜像
|
- 可以指定任意N(N>1)
3. 启动Docker容器
|
- 与第2步中的N保持一致。
4. 运行Hadoop
- 参考第二部分5~6:启动Hadoop,并运行wordcount。