dpdk 代码分析 : 内存初始化
转自http://www.cnblogs.com/jiayy/p/3429725.html
一 前言
http://www.dpdk.org/ dpdk 是 intel 开发的x86芯片上用于高性能网络处理的基础库,业内比较常用的模式是linux-app模式,即利用该基础库,在用户层空间做数据包处理,有了这个基础库,可以方便地在写应用层的网络包处理高性能程序,目前该库已经开源。
Main libraries
multicore framework:多核框架,dpdk库面向intel i3/i5/i7/ep 等多核架构芯片,内置了对多核的支持
huge page memory:内存管理,dpdk库基于linux hugepage实现了一套内存管理基础库,为应用层包处理做了很多优化
ring buffers:共享队列,dpdk库提供的无锁多生产者-多消费者队列,是应用层包处理程序的基础组件
poll-mode drivers:轮询驱动,dpdk库基于linux uio实现的用户态网卡驱动
下面分几个模块说明上述组件的功能和实现。
二 内存管理
1 hugepage技术
hugepage(2M/1G..)相对于普通的page(4K)来说有几个特点,a hugepage 这种页面不受虚拟内存管理影响,不会被替换出内存,而普通的4kpage 如果物理内存不够可能会被虚拟内存管理模块替换到交换区。 b 同样的内存大小,hugepage产生的页表项数目远少于4kpage.举一个例子,用户进程需要使用 4M 大小的内存,如果采用4Kpage, 需要1K的页表项存放虚拟地址到物理地址的映射关系,而采用hugepage 2M 只需要产生2条页表项,这样会带来两个后果,一是使用hugepage的内存产生的页表比较少,这对于数据库系统等动不动就需要映射非常大的数据到进程的应用来说,页表的开销是很可观的,所以很多数据库系统都采用hugepage技术。二是tlb冲突率大大减少,tlb 驻留在cpu的1级cache里,是芯片访问最快的缓存,一般只能容纳100多条页表项,如果采用hugepage,则可以极大减少tlb miss 导致的开销:tlb命中,立即就获取到物理地址,如果不命中,需要查 rc3->进程页目录表pgd->进程页中间表pmd->进程页框->物理内存,如果这中间pmd或者页框被虚拟内存系统替换到交互区,则还需要交互区load回内存。。总之,tlb miss是性能大杀手,而采用hugepage可以有效降低tlb miss
linux 使用hugepage的方式比较简单:
/sys/kernel/mm/hugepages/hugepages-2048kB/ 通过修改这个目录下的文件可以修改hugepage页面的大小和总数目
mount -t hugetlbfs nodev /mnt/huge linux将hugepage实现为一种文件系统hugetlbfs,需要将该文件系统mount到某个文件
mmap /mnt/huge 在用户进程里通过mmap 映射hugetlbfs mount 的目标文件,这个mmap返回的地址就是大页面的了
2 多进程共享
mmap 系统调用可以设置为共享的映射,dpdk的内存共享就依赖于此,在这多个进程中,分为两种角色,第一种是主进程(RTE_PROC_PRIMARY),第二种是从进程(RTE_PROC_SECONDARY)。主进程只有一个,必须在从进程之前启动,负责执行DPDK库环境的初始化,从进程attach到主进程初始化的DPDK上,主进程先mmap hugetlbfs 文件,构建内存管理相关结构
将这些结构存入hugetlbfs 上的配置文件rte_config,然后其他进程mmap rte_config文件,获取内存管理结构,dpdk采用了一定的技巧,使得最终同样的共享物理内存在不同进程内部对应的虚拟地址是完全一样的,意味着一个进程内部的基于dpdk的共享数据和指向这些共享数据的指针,可以在不同进程间通用。
内存全局配置结构rte_config

rte_config 是每个程序私有的数据结构,这些东西都是每个程序的私有配置。
lcore_role:这个DPDK程序使用-c参数设置的它同时跑在哪几个核上。
master_lcore:DPDK的架构上,每个程序分配的lcore_role 有一个主核,对使用者来说影响不大。
lcore_count:这个程序可以使用的核数。
process_type:DPDK多进程:一个程序是主程序,否则初始化DPDK内存表,其他从程序使用这个表。RTE_PROC_PRIMARY/RTE_PROC_SECONDARY
mem_config:指向设备各个DPDK程序共享的内存配置结构,这个结构被mmap到文件/var/run/.rte_config,通过这个方式多进程实现对mem_config结构的共享。
Hugepage页表数组
这个是struct hugepage数组,每个struct hugepage 都代表一个hugepage 页面,存储的每个页面的物理地址和程序的虚拟地址的映射关系。然后,把整个数组映射到文件/var/run /. rte_hugepage_info,同样这个文件也是设备共享的,主/从进程都能访问它。

file_id: 每个文件在hugepage 文件系统中都有一个编号,就是数组1-N
filepath:%s/%smap_%file_id mount 的hugepage文件系统中的文件路径名
size:这个hugepage页面的size,2M还是1G
socket_id:这个页面属于那个CPU socket 。
Physaddr:这个hugepage 页面的物理地址
orig_va:它和final_va一样都是指这个huagepage页面的虚拟地址。这个地址是主程序初始化huagepage用的,后来就没用了。
final_va:这个最终这个页面映射到主/从程序中的虚拟地址。
首先因为整个数组都映射到文件里面,所有的程序之间都是共享的。主程序负责初始化这个数组,首先在它内部通过mmap把所有的hugepage物理页面都映射到虚存空间里面,然后把这种映射关系保存到这个文件里面。从程序启动的时候,读取这个文件,然后在它内存也创建和它一模一样的映射,这样的话,整个DPDK管理的内存在所有的程序里面都是可见,而且地址都一样。
在对各个页面的物理地址份配虚拟地址时,DPDK尽可能把物理地址连续的页面分配连续的虚存地址上,这个东西还是比较有用的,因为CPU/cache/内存控制器的等等看到的都是物理内存,我们在访问内存时,如果物理地址连续的话,性能会高一些。
至于到底哪些地址是连续的,那些不是连续的,DPDK在这个结构之上又有一个新的结构rte_mem_config. Memseg来管理。因为rte_mem_config也映射到文件里面,所有的程序都可见rte_mem_config. Memseg结构。
rte_mem_config

这个数据结构mmap 到文件/var/run /.rte_config中,主/从进程通过这个文件访问实现对这个数据结构的共享。
在每个程序内,使用rte_config .mem_config 访问这个结构。
memseg
memseg 数组是维护物理地址的,在上面讲到struct hugepage结构对每个hugepage物理页面都存储了它在程序里面的虚存地址。memseg 数组的作用是将物理地址、虚拟地址都连续的hugepage,并且都在同一个socket,pagesize 也相同的hugepage页面集合,把它们都划在一个memseg结构里面,这样做的好处就是优化内存。

Rte_memseg这个结构也很简单:
phys_addr:这个memseg的包含的所有的hugepage页面的起始地址
addr:这些hugepage页面的起始的虚存地址
len:这个memseg的包含的空间size
hugepage_sz: 这些页面的size 2M /1G?
这些信息都是从hugepage页表数组里面获得的。
free_memseg
上面memseg是存储一个整体的这种映射的映射,最终这些地址是要被分配出去的。free_memseg记录了当前整个DPDK内存空闲的memseg段,注意,这是对所有进程而言的。初始化等于memseg表示所有的内存都是free的,后面随着分配内存,它越来越小。
必须得说明,rte_mem_config结构在各个程序里面都是共享的,所以对任何成员的修改都必须加锁。
mlock :读写锁,用来保护memseg结构。
rte_memzone_reserve
一般情况下,各个功能分配内存都使用这个函数分配一个memzone
const struct rte_memzone *
rte_memzone_reserve(const char *name, size_t len, int socket_id,
unsigned flags)
{
1、这里就在free_memseg数组里面找满足socket_id的要求,最小的memseg,从这里面划出来一块内存,当然这时候free_memseg需要更新把这部分内存刨出去。
2、把这块内存记录到memzone里面。
}
上面提到rte_memzone_reserve分配内存后,同时在rte_mem_config.memzone数组里面分配一个元素保存它。对于从memseg中分配内存,以memzone为单位来分配,对于所有的分配情况,都记录在memzone数组里面,当然这个数组是多进程共享,大家都能看到。
在rte_mem_config结构里面memzone_idx 变量记录当前分配的memzone,每申请一次这个变量+1。

这个rte_memzone结构如下:
Name:给这片内存起个名字。
phys_addr:这个memzone 分配的内存区的物理地址
addr:这个memzone 分配的内存区的虚拟地址
len:这个zone的空间长度
hugepage_sz:这个zone的页面size
socket_id:页面的socket号
rte_memzone 是dpdk内存管理最终向客户程序提供的基础接口,通过 rte_memzone_reverse 可以获取基于
dpdk hugepage 的属于同一个物理cpu的物理内存连续的虚拟内存也连续的一块地址。rte_ring/rte_malloc/rte_mempool等
组件都是依赖于rte_memzone 组件实现的。
3 dpdk 内存初始化源码解析
入口:
rte_eal_init(int argc,char ** argv) dpdk 运行环境初始化入口函数
—— eal_hugepage_info_init 这4个是内存相关的初始化函数
——rte_config_init
——rte_eal_memory_init
——rte_eal_memzone_init
3.1 eal_hugepage_info_init
这个函数比较简单,主要是从 /sys/kernel/mm/hugepages 目录下面读取目录名和文件名,从而获取系统的hugetlbfs文件系统数,以及每个 hugetlbfs 的大页面数目和每个页面大小,并保存在一个文件里,这个函数,只有主进程会调用。存放在internal_config结构里
3.2 rte_config_init
构造 rte_config 结构
rte_config_init
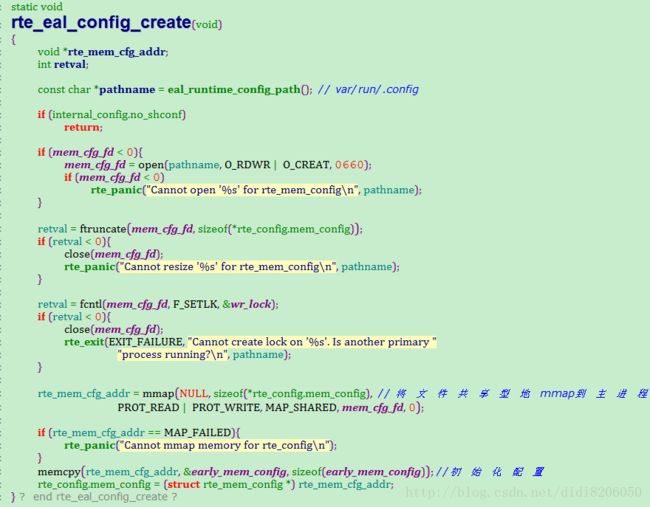
——rte_eal_config_create 主进程执行
——rte_eal_config_attach 从进程执行
rte_eal_config_create 和 rte_eal_config_attach 做的事情比较简单,就是将 /var/run/.config 文件shared 型
mmap 到自己的进程空间的 rte_config.mem_config结构上,这样主进程和从进程都可以访问这块内存,
rte_eal_config_attach

3.3 rte_eal_memory_init
rte_eal_memory_init
——rte_eal_hugepage_init 主进程执行,dpdk 内存初始化核心函数
——rte_eal_hugepage_attach 从进程执行
rte_eal_hugepage_init 函数分几个步骤:
/*
* Prepare physical memory mapping: fill configuration structure with
* these infos, return 0 on success.
* 1. map N huge pages in separate files in hugetlbfs
* 2. find associated physical addr
* 3. find associated NUMA socket ID
* 4. sort all huge pages by physical address
* 5. remap these N huge pages in the correct order
* 6. unmap the first mapping
* 7. fill memsegs in configuration with contiguous zones
*/

函数一开始,将rte_config_init函数获取的配置结构放到本地变量 mcfg 上,然后检查系统是否开启hugetlbfs,如果
不开启,则直接通过系统的malloc函数申请配置需要的内存,然后跳出这个函数。

接下来主要是构建 hugepage 结构的数组 tmp_hp(上图)
下面就是重点了。。
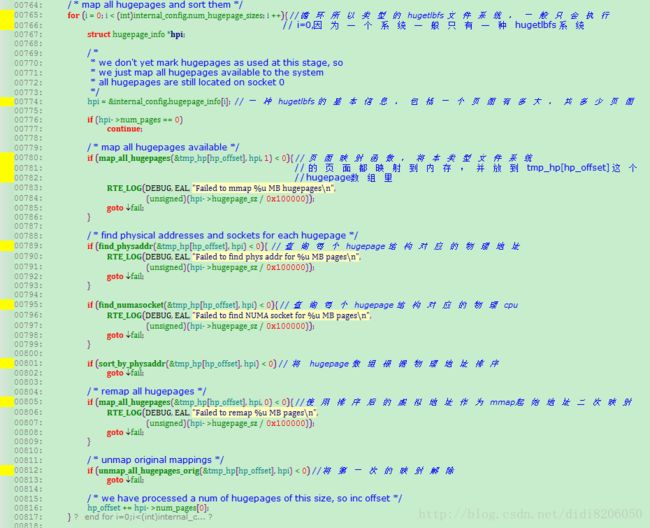
构建hugepage 结构数组分下面几步
首先,循环遍历系统所有的hugetlbfs 文件系统,一般来说,一个系统只会使用一种hugetlbfs ,所以这一层的循环可以认为没有作用,一种 hugetlbfs 文件系统对应的基础数据包括:页面大小,比如2M,页面数目,比如2K个页面
其次,将特定的hugetlbfs的全部页面映射到本进程,放到本进程的 hugepage 数组管理,这个过程主要由 map_all_hugepages函数完成,第一次映射的虚拟地址存放在 hugepage结构的 orig_va变量
第三,遍历hugepage数组,找到每个虚拟地址对应的物理地址和所属的物理cpu,将这些信息也记入 hugepage数组,物理地址记录在hugepage结构的phyaddr变量,物理cpu号记录在 hugepage结构的socket_id变量
第四,跟据物理地址大小对hugepage数组做排序
第五,根据排序结果重新映射,这个也是由函数 map_all_hugepages完成,重新映射后的虚拟地址存放在hugepage结构的final_va变量
第六,将第一次映射关系解除,即将orig_va 变量对应的虚拟地址空间返回给内核
下面看 map_all_hugepages的实现过程


这个函数是复用的,共有两次调用。
对于第一次调用,就是根据hugetlbfs 文件系统的页面数m,构造m个文件名称并创建文件,每个文件对应一个大页面,然后通过mmap系统调用映射到进程的一块虚拟地址空间,并将虚拟地址存放在hugepage结构的orig_va地址上。如果该hugetlbfs有1K个页面,最终会在hugetlbfs 挂载的目录上生成 1K 个文件,这1K 个文件mmap到进程的虚拟地址由进程内部的hugepage数组维护
对于第二次调用,由于hugepage数组已经基于物理地址排序,这些有序的物理地址可能有2种情况,一种是连续的,另一种是不连续的,这时候的调用会遍历这个hugepage数组,然后统计连续物理地址的最大内存,这个统计有什么好处?
因为第二次的映射需要保证物理内存连续的其虚拟内存也是连续的,在获取了最大连续物理内存大小后,比如是100个页面大小,会调用 get_virtual_area 函数向内涵申请100个页面大小的虚拟空间,如果成功,说明虚拟地址可以满足,然后循环100次,每次映射mmap的首个参数就是get_virtual_area函数返回的虚拟地址+i*页面大小,这样,这100个页面的虚拟地址和物理地址都是连续的,虚拟地址存放到final_va 变量上。
下面看 find_physaddr的实现过程
这个函数的作用就是找到hugepage数组里每个虚拟地址对应的物理地址,并存放到 phyaddr变量上,最终实现由函数rte_mem_virt2phy(const void * virt)函数实现,其原理相当于页表查找,主要是通过linux的页表文件 /proc/self/pagemap 实现/proc/self/pagemap 页表文件记录了本进程的页表,即本进程虚拟地址到物理地址的映射关系,主要是通过虚拟地址的前面若干位定位到物理页框,然后物理页框+虚拟地址偏移构成物理地址,其实现如下

下面看 find_numasocket的实现过程
这个函数的作用是找到hugepage数组里每个虚拟地址对应的物理cpu号,基本原理是通过linux提供的 /proc/self/numa_maps 文件,/proc/self/numa_maps 文件记录了本 进程的虚拟地址与物理cpu号(多核系统)的对应关系,在遍历的时候将非huge page的虚拟地址过滤掉,剩下的虚拟地址与hugepage数组里的orig_va 比较,实现如下

sort_by_physaddr 根据hugepage结构的phyaddr 排序,比较简单
unmap_all_hugepages_orig 调用 mumap 系统调用将 hugepage结构的orig_va 虚拟地址返回给内核
上面几步就完成了hugepage数组的构造,现在这个数组对应了某个hugetlbfs系统的大页面,数组的每一个节点是一个hugepage结构,该结构的phyaddr存放着该页面的物理内存地址,final_va存放着phyaddr映射到进程空间的虚拟地址,socket_id存放着物理cpu号,如果多个hugepage结构的final_va虚拟地址是连续的,则其 phyaddr物理地址也是连续的。
下面是rte_eal_hugepage_init函数的余下部分,主要分两个方面,一是将hugepage数组里 属于同一个物理cpu,物理内存连续的多个hugepage 用一层 memseg 结构管理起来。 一个memseg 结构维护的内存必然是同一个物理cpu上的,虚拟地址和物理地址都连续的内存,最终的memzone 接口是通过操作memseg实现的;2是将 hugepage数组和memseg数组的信息记录到共享文件里,方便从进程获取;

遍历hugepage数组,将物理地址连续的hugepage放到一个memseg结构上,同时将该memseg id 放到 hugepage结构的 memseg_id 变量上
下面是创建文件 hugepage_info 到共享内存上,然后hugepage数组的信息拷贝到这块共享内存上,并释放hugepage数组,其他进程通过映射 hugepage_info 文件就可以获取 hugepage数组,从而管理hugepage共享内存
