PixelLink 翻译理解
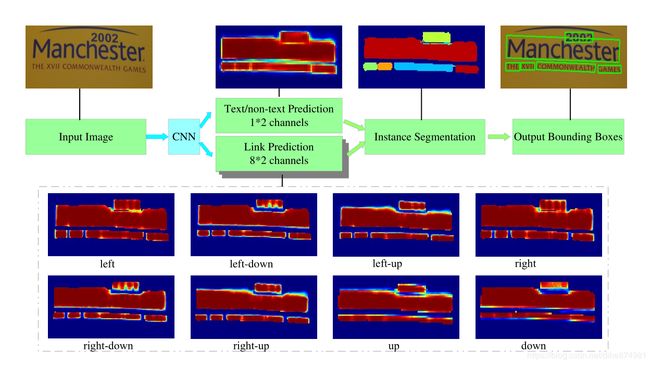
PixelLink
Most state-of-the-art scene text detection algorithms are deep learning based methods that depend on bounding box regression and perform at least two kinds of predictions: text/non-text classification and location regression. Regression plays a key role in the acquisition(获得、收获) of bounding boxes in these methods, but it is not indispensable because text/non-text prediction can also be considered as a kind of semantic segmenta- tion that contains full location information in itself. However, text instances in scene images often lie very close to each other, making them very difficult to separate via semantic seg- mentation. Therefore, instance segmentation is needed to ad- dress this problem. In this paper, PixelLink, a novel scene text detection algorithm based on instance segmentation, is pro- posed. Text instances are first segmented out by linking pixels within the same instance together. Text bounding boxes are then extracted directly from the segmentation result without location regression. Experiments show that, compared with regression-based methods, PixelLink can achieve better or comparable performance on several benchmarks, while re- quiring many fewer training iterations and less training data.
大多数最先进的场景文本检测算法是基于深度学习的方法,其依赖于边界框回归并且执行至少两种预测:文本/非文本分类和位置回归。回归在这些方法中获取边界框中起着关键作用,但它并不是必不可少的,因为文本/非文本预测也可以被视为一种包含完整位置信息的语义分割。。但是,场景图像中的文本实例通常彼此非常接近,这使得它们很难通过语义分割来分离。因此,需要实例分割来解决这个问题。本文提出了一种基于实例分割的新型场景文本检测算法PixelLink。
首先,通过将相同实例的像素link在一起,文本实例被分割 。然后直接从分割结果中提取文本边界框而不进行位置回归,实验表明,与基于回归的方法相比,PixelLink可以在几个基准测试中实现更好或相当的性能,同时需要更少的训练迭代次数和更少的训练数据。
PixelLink初步介绍
In PixelLink, a Deep Neural Network (DNN) is trained to do two kinds of pixel- wise predictions, text/non-text prediction, and link prediction. Pixels within text instances are labeled as positive (i.e., text pixels), and otherwise are labeled as negative (i.e., non- text pixels). The concept of link here is inspired by the
link design in SegLink, but with significant difference. Ev- ery pixel has 8 neighbors. For a given pixel and one of its neighbors, if they lie within the same instance, the link be- tween them is labeled as positive, and otherwise negative. Predicted positive pixels are joined together into Connected Components (CC) by predicted positive links. Instance segmentation is achieved in this way, with each CC representing a detected text. Methods like minAreaRect in OpenCV (Its 2014) can be applied to obtain the bounding boxes of CCs as the final detection result.
在PixelLink中,深度神经网络(DNN)经过训练,可以进行两种像素预测,文本/非文本预测和 link预测。文本实例内的像素被标记为正(即,文本像素),否则被标记为负(即,非文本像素)。这里link的概念受到SegLink 的link设计的启发,但有很大差异。每个像素有8个neighbors。对于给定像素及其neighbors之一,如果它们位于同一实例中,则它们之间的link标记为正,否则为负。预测的正像素通过预测的正link连接在一起成为连接组件(CC)。以这种方式实现实例分割,每个CC代表检测到的文本。像OpenCV中的minAreaRect(2014)这样的方法可用于获取CC的边界框作为最终检测结果(用最小外接矩框出来)
相关工作
2.1 Semantic&Instance Segmentation
最近的方法严重依赖于目标检测系统
2.2 Segmentation-based Text Detection
TextBlocks are found from a saliency map predicted by FCN, and character candidates are ex- tracted using MSER
In CCTN (He et al. 2016), a coarse network is used to detect text regions roughly by generating a text region heat-map
3 Detecting Text via Instance Segmentation
3.1 Network Architecture
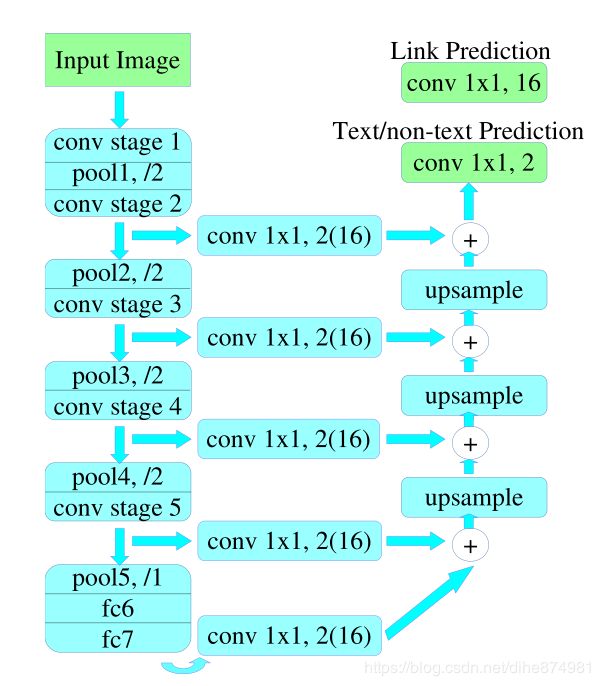
Following SSD and SegLink, VGG16 (Simonyan and Zis- serman 2014) is used as the feature extractor, with fully connected layers, i.e., fc6 and fc7, being converted into convolutional layers. The fashion(名词:时尚,方式,方法 动词:塑造,塑) of feature fusion and pixel- wise prediction inherits(继承) from (Long, Shelhamer, and Darrell 2015). As shown in Fig. 3, the whole model has two separate headers, one for text/non-text prediction, and the other for link prediction. Softmax is used in both, so their outputs have 12=2 and 82=16 channels, respectively.
vgg16 为主干网络进行特征提取,全连接层fc6 and fc7转换为卷积层,特征融合与像素预测的方式继承自xxx ,如图3所示,整个模型有两个单独的headers,一个用于文本/非文本预测,另一个用于link预测。Softmax用于两者,因此它们的输出分别具有 1×2 = 2 和 8×2 = 16个通道。
3.2 Linking Pixels Together
Given predictions on pixels and links, two different thresholds can be applied on them separately. Positive pixels are then grouped together using positive links, resulting in a col- lection of CCs, each representing a detected text instance. Thus instance segmentation is achieved. It is worth noting that, given two neighboring positive pixels, their link are predicted by both of them, and they should be connected when one or both of the two link predictions are positive. This linking process can be implemented using disjoint-set data structure.
使用正link将正像素分组在一起,从而产生CC的集合,每个CC表示检测到的文本实例,因此实现了实例分割。值得注意的是,给定两个相邻的正像素,它们的link由它们两者预测,并且当两个link预测中的一个或两个为正时它们应该连接,可以使用不相交集数据结构来实现该link过程。
3.3 Extraction of Bounding Boxes
This step leads to the key difference between PixelLink
and regression-based methods, i.e., bounding boxes are ob- tained directly from instance segmentation other than loca- tion regression.
分割完就检测完了,最后用最小外接矩画框
3.4 Post Filtering after Segmentation
后处理比较复杂
Since PixelLink attempts to group pixels together via links, it is inevitable to have some noise predictions, so a post- filtering step is necessary. A straightforward yet efficient solution is to filter via simple geometry features of detected boxes, e.g., width, height, area and aspect ratio, etc.
由于PixelLink尝试通过link将像素分组在一起,因此不可避免地要进行一些噪声预测,因此需要进行后滤波步骤。一种简单而有效的解决方案是通过检测到的boxs的简单几何特征进行过滤,例如宽度,高度,面积和纵横比等。
4 Optimization
4.1 Ground Truth Calculation
暂略
4.2 Loss Function
The training loss is a weighted sum of loss on pixels and loss on links:
L = λLpixel + Llink. (1)
Since Llink is calculated on positive pixels only, the classi- fication task of pixel is more important than that of link, and λ is set to 2.0 in all experiments
由于Link仅在正像素上计算,因此像素的分类任务比link更重要,并且在所有实验中λ都设置为2.0。.
Loss on Pixels
Sizes of text instances might vary a lot. For example, in Fig. 1, the area of ‘Manchester’ is greater than the sum of all the other words. When calculating loss, if we put the same weight on all positive pixels, it’s unfair to in- stances with small areas, and may hurt the performance. To deal with this problem, a novel weighted loss for segmenta- tion, Instance-Balanced Cross-Entropy Loss, is proposed. In detail, for a given image with N text instances, all instances are treated equally by giving a same weight to everyone of them, denoted as Bi in Equ. 2. For the i-th instance with area = Si, every positive pixels within it have a weight of wi = Bi/si
Loss on Links
Losses for positive and negative links are calculated separately and on positive pixels only:
着重理解Link
这里要参考seglink的论文
The link design is important because it converts semantic segmentation into instance segmentation
seglink