scrapy爬取图片详细步骤
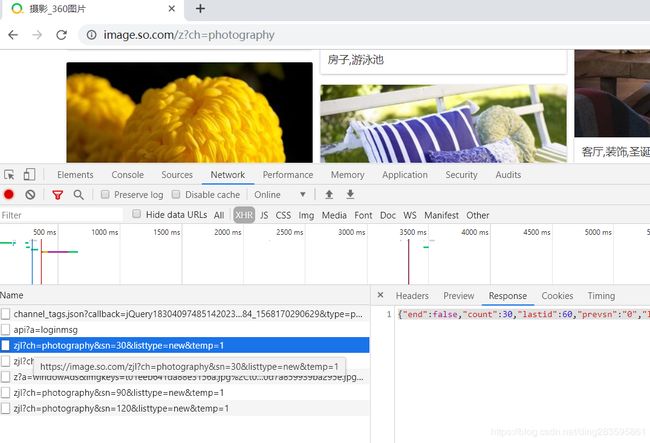
1.爬取https://image.so.com/z?ch=photography图片,用谷歌浏览器打开开发者工具,选中XHR选项, 由于使用了AJAX ,可以看到页面的刷新情况. 待会附上的源码就有拼接url:https://image.so.com/zj?key=value&key1=value2…
以及json字段解析


1 . images.py 源码
import scrapy
from urllib.parse import urlencode
from scrapy import Spider,Request
import json
from images360.items import Images360Item
class ImagesSpider(scrapy.Spider):
name = 'images'
allowed_domains = ['images.so.com']
start_urls = ['http://images.so.com/']
def parse(self, response):
result = json.loads(response.text)
for image in result.get('list'):
item = Images360Item()
item['id'] = image.get('id')
item['url'] = image.get('qhimg_url')
item['title'] = image.get('group_title')
item['thumb'] = image.get('qhimg_thumb')
yield item
def start_requests(self):
data = {'ch': 'photography', 'listtype': 'new', 'temp': '1'}
base_url = 'https://image.so.com/zj?'
for page in range(1,self.settings.get('MAX_PAGE') + 1):
#由于页面是ajax请求,sn号,每页30
data['sn'] = (page-1)*30
#拼接成ch=photography&sn=30&listtype=new&temp=1
params = urlencode(data)
#拼接完整的url
url = base_url + params
print(url)
print('\n')
yield Request(url = url,callback = self.parse)
2 . items.py源码如下:
import scrapy
class Images360Item(scrapy.Item):
collection = table = 'images'
id = scrapy.Field()
url = scrapy.Field()
title = scrapy.Field()
thumb = scrapy.Field()
3 . pipelines.py 源码:
import pymongo
import pymysql
from scrapy.pipelines.images import ImagesPipeline
from scrapy import Request
from scrapy.exceptions import DropItem
#通过mongo存储的类
class MongoPipeline(object):
"""docstring for MongoPipeline"""
def __init__(self, mongo_uri,mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri = crawler.settings.get('MONGO_URI'),
mongo_db = crawler.settings.get('MONGO_DB')
)
def open_spider(self,spider):
self.client = pymongo.MongoClient(self.mongo_uri)
#如果self.mongo_db数据库不存在,则自动创建
self.db = self.client[self.mongo_db]
def process_item(self,item,spider):
#如果结合item.collection不存在,则自动创建
self.db[item.collection].insert(dict(item))
return item # 必须实现返回
def close_spider(self,spider):
self.client.close()
#通过mysql存储的类
class MysqlPipeline(object):
def __init__(self, host, database, user, password, port,sql_image):
self.host = host
self.database = database
self.user = user
self.password = password
self.port = port
self.sql_image = sql_image
@classmethod
def from_crawler(cls, crawler):
return cls(
host = crawler.settings.get('MYSQL_HOST'),
database = crawler.settings.get('MYSQL_DATABASE'),
user = crawler.settings.get('MYSQL_USER'),
password = crawler.settings.get('MYSQL_PASSWORD'),
port = crawler.settings.get('MYSQL_PORT'),
sql_image = crawler.settings.get('SQL_IMAGE')
)
def open_spider(self,spider):
self.db = pymysql.connect(self.host, self.user, self.password, self.database, charset='utf8', port=self.port)
self.cursor = self.db.cursor()
#创建表/字段语句,一定要先创建,后面才能执行insert动作
self.cursor.execute(self.sql_image)
def process_item(self,item,spider):
data = dict(item)
keys = ','.join(data.keys())
# print('keys:%s'%keys)
values = ', '.join(['%s']*len(data))
# print('values:%s'%values)
sql = 'insert into %s (%s) values(%s)' % (item.table, keys, values)
self.cursor.execute(sql,tuple(data.values()))
self.db.commit()
return item
def close_spider(self,spider):
self.db.close()
#保存到本地类
class Images360Pipeline(ImagesPipeline):
def file_path(self, request, response=None, info=None):
# 重命名,若不重写这函数,图片名为哈希,就是一串乱七八糟的名字
image_guid = request.url.split('/')[-1] # 提取url前面名称作为图片名。
return image_guid
def item_completed(self, results, item, info):
images_paths = [x['path'] for ok, x in results if ok]
if not images_paths:
raise DropItem('Image Download Failed')
return item
def get_media_requests(self, item, info):
yield Request(item['url'])
```
4 . settings.py源码如下:
import random
# user agent 列表
USER_AGENT_LIST = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
]
#随机生成user agent
USER_AGENT = random.choice(USER_AGENT_LIST)
BOT_NAME = 'images360'
SPIDER_MODULES = ['images360.spiders']
NEWSPIDER_MODULE = 'images360.spiders'
#Obey robots.txt rules
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'images360.pipelines.MysqlPipeline': 300,
'images360.pipelines.MongoPipeline': 301,
'images360.pipelines.Images360Pipeline': 302,
}
#定义爬取的页数
MAX_PAGE = 20
#定义mongodb数据库
MONGO_URI = 'localhost'
MONGO_DB = 'images360'
#定义mysql数据库
MYSQL_HOST = 'localhost'
MYSQL_DATABASE = 'images360'
MYSQL_USER = 'root'
MYSQL_PASSWORD = '123456'
MYSQL_PORT = 3306
IMAGES_STORE = './images'
#创建表/各个字段信息
SQL_IMAGE = '''create table if not exists images(
id varchar(100) not null,
url varchar(100) not null,
title varchar(100) not null,
thumb varchar(100) null
)
'''
运行之后结果如下:

