浅析 Transformer Stage 在 DataStage 作业中的用法及功能实现
产品背景介绍
IBM InfoSphere DataStage 是业界主流的 ETL(Extract, Transform, Load) 工具,它使用了 Client-Server 架构,在服务器端存储所有的项目和元数据,并支持在多重数据结构中对大量数据进行收集、整合和转换。客户端 DataStage Designer 为整个 ETL 过程提供了一个图形化的开发环境,用户在 Designer 中对 DataStage Job 的进行设计和开发。DataStage 中提供了多个过程处理 Stage 来满足 ETL 的需要,然而 Transformer Stage 在这些 Stage 中用途和使用方法最为广泛,本文将对 Transformer Stage 在 ETL 过程中的用法及实现的功能做出详尽描述。本文中涉及到 IBM InfoSphere DataStage 为 IBM Information Server 8.0.1 版本。
Transformer Stage 组件介绍
Transformer Stage 在 DataStage 中是一个重要的,功能强大的组件,在 ETL 过程中,它承担“T”( 即数据的转化 ) 的责任。在 Transformer Stage 中可以指定数据的来源和目的地,匹配对应输入字段和输出字段,并指定转换规则和约束条件。
图 1. Transformer Stage 运用在 DataStage job 中的运用

图 2. Transformer Stage 列映射与字段表达式
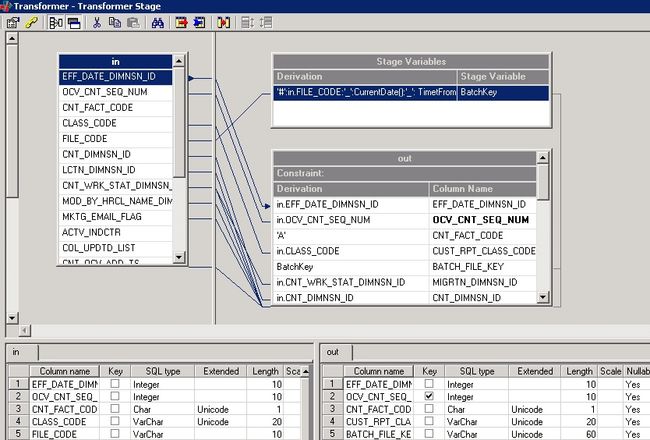
Transformer Stage 在 DataStage job 中可实现的功能及案例分析
1. 字段转换
字段转换是 Transformer Stage 中最常见的一个功能,它能够将源数据根据一定的规格转换成为目标数据。下面将以 ETL 过程中比较常见的 Date 与 Timestamp 相互转换为例,说明字段转换的实现方式。
1.1 源数据类型为 Timestamp,目标类型为 Date
清单 1. 时间转换函数
|
1
|
TimestampToDate(in.ADD_DATE)
|
图 3. 字段转换表达式
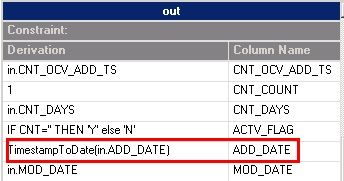
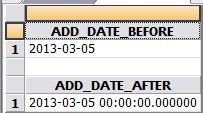
图 4. 字段转换前后对比

1.2 源数据类型为 Date,目标类型为 Timestamp
这种转换需要将 Date 类型先转换为 Varchar 类型,再将 Varchar 补齐 Timestamp 所需的时分秒的字符,再转换为 Timestamp 类型
清单 2. 时间转换函数
|
1
2
|
StringToTimestamp((DateToString(in.ADD_DATE,"%yyyy-%mm-%dd"):' 00:00:00'),
"%yyyy-%mm-%dd %hh:%nn:%ss")
|
图 5. 字段转换表达式
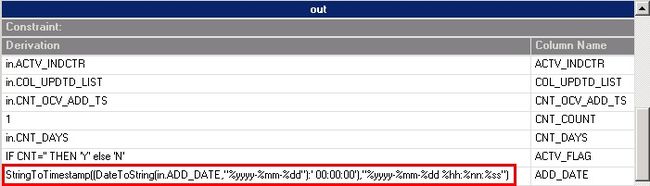
图 6. 字段转换前后对比
1.3 其他类型的转换
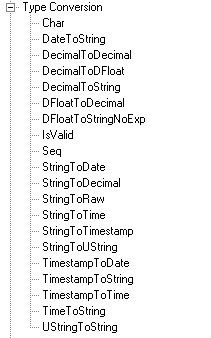
DataStage 提供了丰富的字段转换的函数,下图为字段转换函数列表。用户可根据自己的实际需求选取其中最简便的方式实现转换。
图 7. Parallel job 中的字段转换函数
2. 字段逻辑运算及判断
利用 Transformer Stage 进行字段间的运算及判断,该功能等同于 SQL 中的逻辑运算与判断。
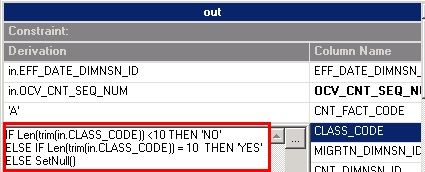
下图为根据源字段长度返回目标字段的值。Transformer Stage 根据逻辑判断将返回‘ YES ’ , ’ NO ’ 和 NLLL 三个值
清单 3. 逻辑运算表达式
|
1
2
3
|
IF Len(trim(in.CLASS_CODE)) < 10 THEN 'NO'
ELSE IF Len(trim(in.CLASS_CODE)) = 10 THEN 'YES'
ELSE SetNull()
|
图 8. 字段逻辑运算表达式
3. 数据复制
ETL 的过程中可能会有同一个数据流需要被复制,并用作不同目标的输出方式的情况,这时 Transformer Stage 就进行简单的字段复制来实现。用户可将被复制的列映射选中,直接拖拽到复制的列映射中去,并设置输出 Stage 属性。
图 9. copy link 即为 out link 的复制数据流
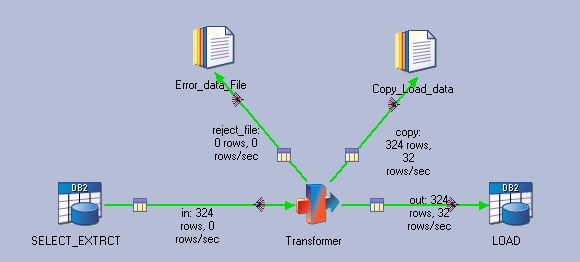
图 10. 复制的数据流保证数据列映射的一致性

4. 数据过滤
数据过滤功能相当于 SQL 中的 where 语句,Transformer Stage 中数据过滤的优势在于,可以根据不同的逻辑,在 stage 写入不同的条件限制来输出数据。
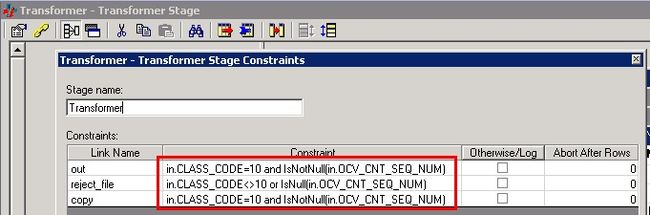
下图中, 双击 Transformer Stage 中的 Constraints 属性按钮,在弹出的窗口中会显示每个 link 对应的属性框,可以根据具体的业务逻辑,填写每个 link 的约束条件,这样 Transformer Stage 就会根据相应的条件输出被约束后的数据。
图 11. Transformer Stage 中的约束表达式
5. 字段关联
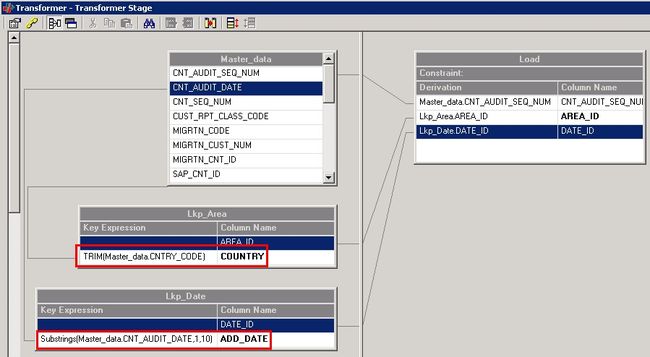
Transformer Stage 实现字段关联的功能仅限于 Server job 中。Transform stage 可以根据数据源所生成的 Hash File 中的 Key 值,与主数据进行关联,实现方式等价于数据库中的表关联。下图 job 以一个主表关联两个维表为例,做出详细说明。
下图中, 双击 Transformer Stage 中的 Constraints 属性按钮,在弹出的窗口中会显示每个 link 对应的属性框,可以根据具体的业务逻辑,填写每个 link 的约束条件,这样 Transformer Stage 就会根据相应的条件输出被约束后的数据。
图 12. Transformer Stage 在 Server job 中的数据关联用法

Job 中的主数据与两个维表,通过以下两个关联字段的表达式进行关联,用户可以根据 DataStage 提供的 Server job 函数对关联字段进行预处理,保持关联字段的类型和长度一致。
清单 4. 关联字段处理表达式
|
1
2
|
TRIM(Master_data.CNTRY_CODE)
SUBSTRINGS(Master_data.CNT_AUDIT_DATE,1,10)
|
图 12. 关联条件表达式及列映射
Transformer Stage 的自定义函数及变量
1. 自定义函数的使用
DataStage 中提供了 Routines 函数功能,Routines 是一个非常强大的内置函数库供开发人员使用,当然再多的函数也有可能满足不了特定的业务需求,因此开发人员也可以开发自定义的 Routines 函数,然后将其用于转换过程。通过下面的实例开发人员可以了解如何开发一个 Routines 函数并在 Transform Stage 中进行调用。 首先新建一个 Routines,根据具体 Transform Stage 使用情况可以选择 Server 或者 Parallel Routine。
图 14. 新建 Routine
在 General 标签页,命名其为 TestRoutine
图 15. 命名 Routine

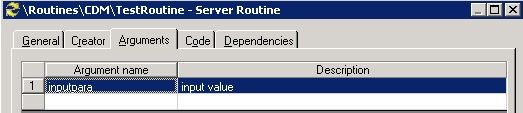
切换至 Arguments 标签页,定义函数输入参数,如下图所示,我们定义一个输入参数 inputpara
图 16. 定义 Routine 输入参数
切换至 Code 标签页,在这里编写实际的代码逻辑
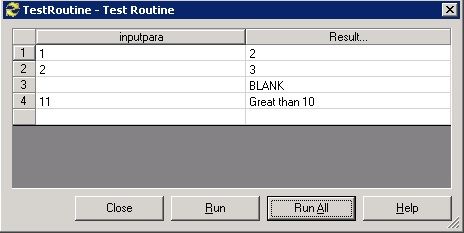
保存代码后,点击 Compile 按钮,然后通过 Test 界面进行相关测试以确保函数逻辑准备。
清单 5. 自定义函数编码
|
1
2
3
4
5
6
7
8
9
10
11
12
|
* 如果输入参数为空或者空串,返回‘ BLANK ’
如果输入参数小于 10,则自加 1,否则返回 ’ Great than 10 ’ *
If inputpara="" OR IsNull(inputpara) Then
Ans="BLANK"
GoTo ExitFunc
End
If inputpara<=10 Then
Ans=inputpara +1
End Else
Ans="Great than 10"
End
ExitFunc:
|
图 17. 定义 Routine 输入参数
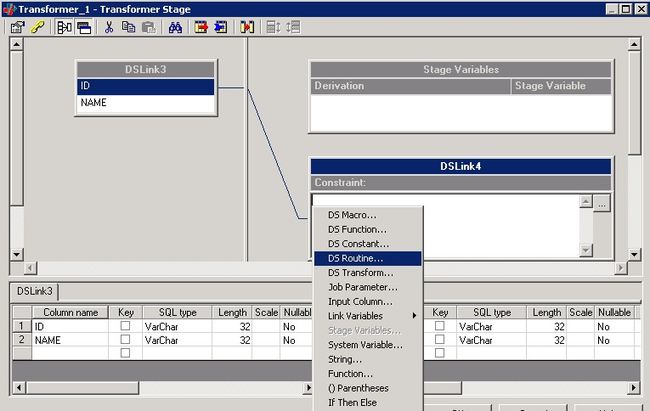
如果需要在 Transform Stage 中对相应字段进行函数调用的话,打开 Transformer Stage Property 属性页,选中所需修改的字段,点击引用按钮,选择如图 16 所示的 DS Routine,即可进行相关操作。
图 18. 在 Transform Stage 中引用函数
2. 阶段变量 Stage Variables 的使用
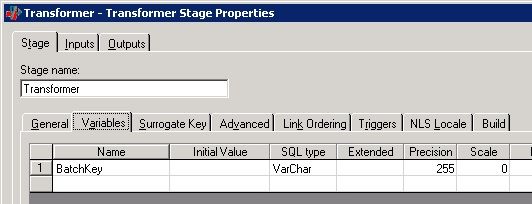
DataStage 中还提供了 Stage Variables 这种阶段变量的方式来实现复杂逻辑的处理,并提高处理效率。Transformer Stage 可以定义一个 Stage Variables,将字段的 Derivation 赋值为 Stage Variables,减少一次或者多次计算量。Stage Variables 是对于 job 级别的变量,因而不能直接在整个 project 中被调用。通过下面的实例开发人员可以了解如何开发一个 Stage Variables 并在 Transform Stage 中进行调用。实例中的 Stage Variables 用来生成同一批数据加载中的唯一键。双击 Transformer Stage 中的 stage properties 属性按钮,在弹出的窗口选中 Variables 页签,定义一个 job 级别的 variables , 命名为“BatchKey”. 并保存。
图 19. 在 job 中定义 Stage Variables
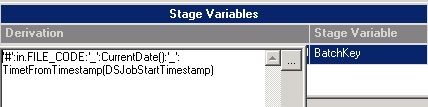
在 Transformer Stage 的列映射右半部分的 Stage variables 属性框中,就能显示出已经定义的“BatchKey”,输入变量的表达式。
图 20. Stage variables 表达式
清单 6. Stage variables 表达式
|
1
|
'#':in.FILE_CODE:'_':CurrentDate():'_': TimetFromTimestamp(DSJobStartTimestamp)
|
特别注意的是,为了保证同一批数据加载的唯一键,这里用到了 DataStage 的自带函数 DSJobStartTimestamp,该函数返回的结果为作业开始运行的时间,每次作业运行只能返回唯一的时间。
图 21. 列映射中引用被定义的 Stage Variables
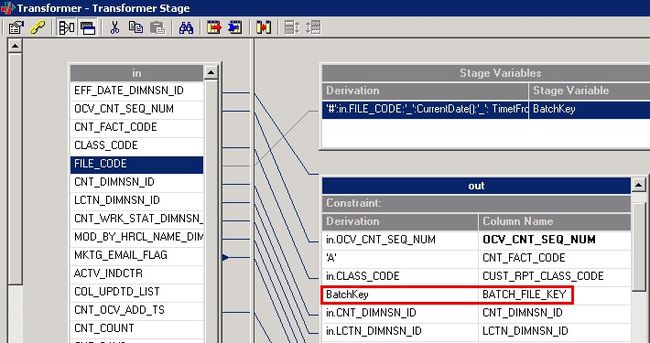
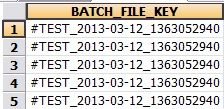
图 22. 数据库中经过 Stage Variables 定义生成的唯一键
Transformer Stage 在 job 中性能优化及替代组件
Transformer Stage 有着很强大数据处理的功能,与此同时,DataStage 也提供了一些更加实用,简洁的过程处理 Stage,其功能等同于 Transformer Stage 中的各个分项功能。
表 1. Transformer Stage 功能替换 Stage 列表
Transformer Stage 的优化原则
1. 提高运行效率
加快 Job 的逻辑处理速度,灵活应用不同的 Stage,或者走不同的处理流程,对整个 Job 的处理速度的提升,也会有比较显著的效果。尽可能共享数据源,减少使用 (parallel routine) 的使用,尽可能用其他 Stage 替换 Transformer Stage。优化 Partition 方式,这些都可以提高运行效率。
2. 对于数据较大的表,改用 Join Stage 替代 Lookup Stage
通常会用 LookUp Stage 做有关数据的匹配查找工作。对于 LookUp Stage 的 Reference Link,DataStage 会尽可能将数据放到内存中,并且只有当所有的 Reference Link 数据都读取完毕,Lookup Stage 才会开始工作,所以当其数据量较大的时候(超过了内存的大小),推荐用 Join Stage 的内连接来实现相同的功能。
3. 字段合并及字段过滤
当整个处理流程只需要部分源数据字段时,最好通过 Copy Stage 或者 Sequential File Stage 的 Drop on input 筛选字段。如果源为数据库时,则只选择需要的字段。尽可能减少处理过程中系统资源的消耗。某些时候只需要处理部分字段,但是需要输出所有字段。推荐将连续的,不参与运算的字段进行合并处理。这样可以减少数据的解析,减少处理量。让工具只需要处理较少的需要转换的字段。对于多个不参与运算的字段连在一起的情况下,这种处理方式也有很好的效果。
4. 减少 Transformer Stage 及 Parallel Routine 的使用
用其他 Stage 替换 Transformer Stage 对效率的提高也会有帮助。比如,用 Modify Stage 处理 null 值及做类型转换;用 Filter Stage 做数据分流等等。
Parallel Routine 是以 C++ 语言编写的,存放在 Server 端,会被编译为 C++ Operator。尽量少用 Parallel Routine。当一个复杂的逻辑需要十数个 Stage 完成,可以酌情考虑用 Parallel Routine 替换。
结束语
Transformer Stage 虽然是一个看上去几乎“万能”的组件,可是怎么用好它,让它发挥出自身的特点才是最重要的。综上分析出的用法及功能,合理的确定 DataStage 作业中的组件使用,让 Transformer Stage 组件及其他组件相辅相成的使用,并形成完美的配合。