R语言使用支持向量机完成数据分类(SVM)
说明
libsvm和SVMLite都是非常流行的支持向量机工具,在R语言中,e1071包提供了libsvm的实现,klap包提供了对SVMLite的实现。
继续使用telecom churn数据集做为输入数据源来训练向量机
导入e1071包
library(e1071)使用svm函数训练支持向量机,trainset数据集作为输入数据集,churn是分类类别。
model = svm(churn ~.,data = trainset,kernel = "radial",cost = 1,gamma = 1/ncol(trainset))使用summary( )得到model所有信息
Call:
svm(formula = churn ~ ., data = trainset, kernel = "radial", cost = 1, gamma = 1/ncol(trainset))
Parameters:
SVM-Type: C-classification
SVM-Kernel: radial
cost: 1
gamma: 0.05882353
Number of Support Vectors: 691
( 394 297 )
Number of Classes: 2
Levels:
yes no说明
支持向量机构建了一个超平面(或者一组超平面),使得高维度空间内两个类的边缘间隔最大化。定义这些超平面的向量就被称为支持向量,
支持向量机首先要构建一个超平面能够最大化距离,然后将定义扩展到非线性可分问题上,最后将数据映射到一个高维度空间,使得数据能够更容易被边界分开。
SVM的优势在于利用了面向工程问题的核函数,能够提供准确率非常高的分类模型,同时可以借助正则项避免模型的过度适应,用户不用担心局部最优与多重共线性问题。svm的算法的主要弊端是对模型进行训练和测试的速度很慢,模型处理需要很长的时间。SVM的结果也很难解释,如何确定合适的核函数是一个难点,而正则化也是用户需要考虑的问题。
本例中通过训练函数SVM,用户可以确定核函数,成本函数的gamma,对于核函数的选择,默认选择radial(径向函数),用户还可以选择线性核函数,多项式函数,径向基函数和sigmod核函数。gamma函数确定了分离平面的形状,默认为函数维数的倒数(1/数据维度),提高gamma的值通常会增加支持向量的数量。考虑到成本函数,默认值通常为1,此时正则式也是常数,正则式越大,边界越小。
选择支持向量机的惩罚因子
支持向量机能够通过最大化边界得到一个优化的超平面以完成对训练数据的分离,不过有时算法也允许被错误分类样本的存在,惩罚因子能实现SVM对分类数误差及分离的控制。如果惩罚因子比较小,分类间隔会比较大(软间隔),将产生比较多的被错分样本,相反当加大惩罚因子,会缩小分类间隔(硬间隔),从而减小错分样本。
调用subset函数获得iris数据集中的species值为setosa和virginica,选择样例在Sepal.Width,Sepal.Width,Species列的投影。
调用plot函数绘制散点图
iris.subet = subset(iris,select = c("Sepal.Length","Sepal.Width","Species"),Species %in% c("setosa","virginica"))
> plot(x = iris.subet$Sepal.Length,y = iris.subet$Sepal.Width,col = iris.subet$Species,pch = 19)
iris数据集子集散点图
将惩罚因子设置为1,利用iris.subset数据集训练SVM,将支持向量用蓝色的圈注标出来。
svm.model = svm(Species ~ .,data = iris.subet,kernel = "linear",cost = 1,scale = FALSE)
plot(x = iris.subet$Sepal.Length,y = iris.subet$Sepal.Width,col = iris.subet$Species,pch = 19)
points(iris.subet[svm.model$index,c(1,2)],col = "blue",cex = 2)

加分隔线:
w = t(svm.model$coefs) %*% svm.model$SV
b = -svm.model$rho
abline(a = -b/w[1,2],b=-w[1,1]/w[1,2],col = "red",lty = 5)
将惩罚因子设置为10000,重新训练一个SVM模型
plot(x = iris.subet$Sepal.Length,y = iris.subet$Sepal.Width,col = iris.subet$Species,pch = 19)
svm.model = svm(Species ~ .,data = iris.subet,kernel = "linear",cost = 10000,scale = FALSE)
points(iris.subet[svm.model$index,c(1,2)],col = "blue",cex = 2)
w = t(svm.model$coefs) %*% svm.model$SV
b = -svm.model$rho
abline(a = -b/w[1,2],b=-w[1,1]/w[1,2],col = "red",lty = 5)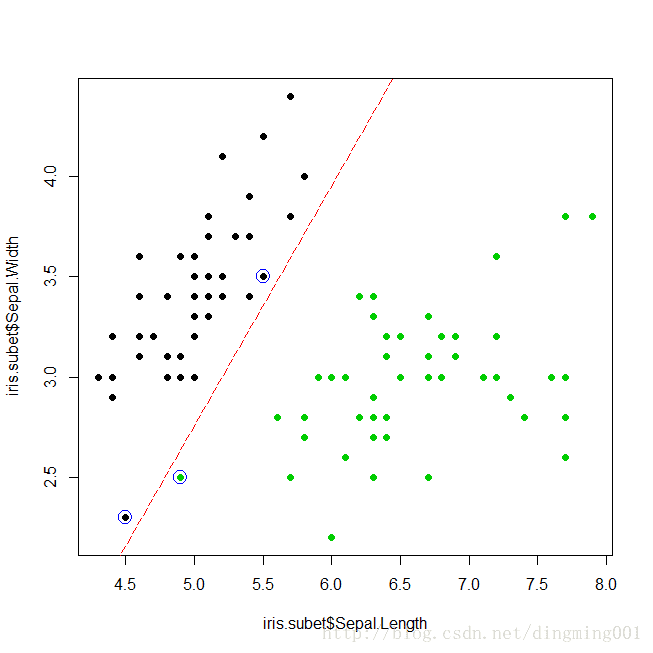
惩罚因子原理
本节讨论了惩罚因子大小对SVM分类器的影响。我们首先选择了一个小的惩罚因子cost = 1来训练SVM,该分类器允许存在部分错分样本,分隔边界属于软间隔,支持向量均用蓝色圆圈进行标注,不同类别之间也增加了一条分隔线,出于选择了一个小的惩罚因子,造成图中有一个绿点(virginica)被错误的划分到其它分类(setosa)