Python实现中文最大逆向匹配分词算法
学习流程记录
20170502
经过查阅资料对最大逆向匹配算法上有了概念性的理解, 但是要具体用某一种编程工具来实现还是需要好好思考一下, 需要用什么方法实现,以及各种语法规则
手中材料有一些文章的已经切好的词, 放在表格的某一列,一词一格.
停用词表一个, 一词一格
N篇待切文章(均在切词表有)
由于数据较大可以自己制作小型测试数据,以方便调试.
5.7–5.10
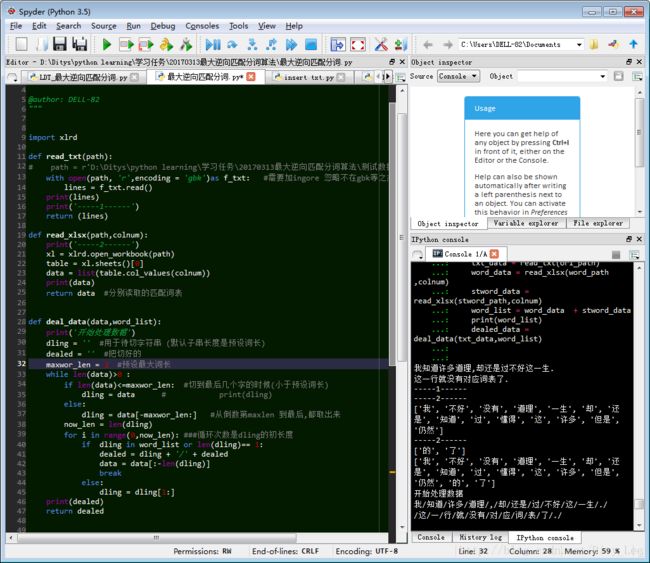
import xlrd
def read_txt(path):
# path = r'D:\Ditys\python learning\学习任务\20170313最大逆向匹配分词算法\测试数据\测试文本.txt'
with open(path, 'r',encoding = 'gbk')as f_txt: #需要加ingore 忽略不在gbk等之类的非法字符
lines = f_txt.read()
print(lines)
print('-----1------')
return (lines)
def read_xlsx(path,colnum):
print('-----2------')
xl = xlrd.open_workbook(path)
table = xl.sheets()[0]
data = list(table.col_values(colnum))
print(data)
return data #分别读取的匹配词表
def deal_data(data,word_list):
print('开始处理数据')
dling = '' #用于待切字符串 (默认子串长度是预设词长)
dealed = '' #把切好的
maxwor_len = 2 #预设最大词长
while len(data)>0 :
if len(data)<=maxwor_len: #切到最后几个字的时候(小于预设词长)
dling = data # print(dling)
else:
dling = data[-maxwor_len:] #从倒数第maxlen 到最后,都取出来
print(dling)
now_len = len(dling)
for i in range(0,now_len): ###循环次数是dling的初长度
print('开始切子串')
if dling in word_list or len(dling)== 1:
dealed = dling + '/' + dealed
data = data[:-len(dling)]
break
else:
dling = dling[1:]
print(dealed)
return dealed
if __name__=='__main__':
orl_path = r'D:\Ditys\python learning\学习任务\20170313最大逆向匹配分词算法\测试数据\测试文本.txt'
word_path = r'D:\Ditys\python learning\学习任务\20170313最大逆向匹配分词算法\测试数据\测试词表.xlsx'
stword_path = r'D:\Ditys\python learning\学习任务\20170313最大逆向匹配分词算法\测试数据\测试停用词表.xlsx'
colnum = 0 #第一列传的是0!!!不要传1 ,不然函数就读不到数据了
txt_data = read_txt(orl_path)
word_data = read_xlsx(word_path ,colnum)
stword_data = read_xlsx(stword_path,colnum)
word_list = word_data + stword_data
print(word_list)
dealed_data = deal_data(txt_data,word_list)
最开始写的时候, 也没有写的fun函数 (批量读取txt路径的函数, 只是在单个文本进行测试)
而是是单个文本测试, 就不需要 import os 这个模块了.
然后也不需要fun()这个函数去获取一个存放了路径的列表. 以及主函数里边就不需要for遍历列表了(因为目标只有一个)
单文本处理到 批量文本处理
只处理一个文本这是最开始写代码适合要完成的, 毕竟上面的def deal_data(data,word_list):
此函数是实现算法的核心 ,之后的批量处理功能可以继续想办法调用包是现:
想批量处理, 可以用os模块
然后写一个fun() 函数, 返回一个存有指定路径下所有文件的路径列表:
#遍历文件夹
def fun(path):
fileArray = []
for root, dirs, files in os.walk(path):
for fn in files:
eachpath = str(root+'/'+fn)
fileArray.append(eachpath)
return fileArray path 就是所提到需要遍历的文件夹
批量处理后, 批量存储文件
但是关于存放的问题, 也是要进行一番考虑. 如果是批量处理, 分词好的txt,存放的时统一放在一个文件夹里,,命名应该和没有分词的名字相同或相似, 这样去查看才有对应’def deal_data(data,word_list):’
于是找到了这两种方法:(用了os模块)
''获取文件名的方法,两种''
#第一种:使用.split('\\')就可以了
path = 'D:\Ditys\python learning\学习任务\20170313最大逆向匹配分词算法\测试数据\测试文本.txt'
name = path.split("\\")[-1] # 第一个反斜\代表转义~因为'\'是一个特殊的字符
print(name)
#第二种 用到os包 的os.path.basename(..)
output_path = 'D:\Ditys\python learning\学习任务\20170313最大逆向匹配分词算法\存放分词结果'
path = 'D:\Ditys\python learning\学习任务\20170313最大逆向匹配分词算法\测试数据\测试文本.txt'
name = os.path.basename(path)
print(os.path.basename(path))
out_path = output_path + '\\' + name
print(out_path)最后, 这些都运行成功后, 可以加写一个批量写入txt的函数和语句, 其中最关键的就是:
out_path = output_path + '\\' + name <<<<<是生成了一个txt 它的路径是定义好的output_path,名字和源文件相同. 二者用’\’加上, 就是一个out_path 路径.
新增函数:
def write_into_txt(data,path):
with open(path,'w') as f :
f.write(data)只要把这个函数的调用也写进for遍历里, 每分一个txt文档就可以写一次啦!
完成!
全部完整代码
路径换成真正需要处理的数据, 进行分词:
import xlrd
import os
def fun(path):
fileArray = []
for root, dirs, files in os.walk(path):
for fn in files:
eachpath = str(root+'/'+fn)
fileArray.append(eachpath)
return fileArray
def read_txt(path):
# path = r'D:\Ditys\python learning\学习任务\20170313最大逆向匹配分词算法\测试数据\测试文本.txt'
with open(path, 'r',encoding = 'Utf-8')as f_txt: #需要加ingore 忽略不在gbk等之类的非法字符
lines = f_txt.read()
print(lines)
print('-----1------')
return (lines)
def read_xlsx(path,colnum):
print('-----2------')
xl = xlrd.open_workbook(path)
table = xl.sheets()[0]
data = list(table.col_values(colnum))
# print(data)
return data #分别读取的匹配词表
def deal_data(data,word_list):
print('开始处理数据')
dling = '' #用于待切字符串 (默认子串长度是预设词长)
dealed = '' #把切好的
maxwor_len = 10 #预设最大词长
while len(data)>0 :
if len(data)<=maxwor_len: #切到最后几个字的时候(小于预设词长)
dling = data # print(dling)
else:
dling = data[-maxwor_len:] #从倒数第maxlen 到最后,都取出来
# print(dling)
now_len = len(dling)
for i in range(0,now_len): ###循环次数是dling的初长度
# print('开始切子串')
if dling in word_list or len(dling)== 1:
dealed = dling + '/' + dealed
data = data[:-len(dling)]
break
else:
dling = dling[1:]
print(dealed)
return dealed
def write_into_txt(data,path):
with open(path,'w') as f :
f.write(data)
if __name__=='__main__':
# orl_path = r'D:\Ditys\python learning\学习任务\20170313最大逆向匹配分词算法\分词文本\1.txt'
colnum = 1 #首列传的是0!!!不要弄错 ,不然函数就读不到数据了
word_path = r'D:\Ditys\python learning\学习任务\20170313最大逆向匹配分词算法\词表\words.xlsx'
stword_path = r'D:\Ditys\python learning\学习任务\20170313最大逆向匹配分词算法\词表\stopwords.xlsx'
word_data = read_xlsx(word_path ,colnum)
stword_data = read_xlsx(stword_path,colnum)
word_list = word_data + stword_data
print(word_list)
output_path = 'D:\Ditys\python learning\存放分词结果' #!!!!路径名不要太长, 不然下面的拼接的out_path就会报错啊啊啊~~ 蜜汁会改变路径
txt_path = r'D:\Ditys\python learning\学习任务\20170313最大逆向匹配分词算法\分词文本'
path_array = fun(txt_path)
for ech in path_array:
txt_data = read_txt(ech)
dealed_data = deal_data(txt_data,word_list)
now_name = os.path.basename(ech)
print(now_name)
out_path = output_path + '\\' +now_name
print(out_path)
write_into_txt(dealed_data,out_path)
最后所需遍历的文件夹有191个txt文档. 运行过后, 在指定存放数据的文件夹生成了对应的191个txt文件.