目录
- 1.本次讲座的学习总结
- 技术背景
- 密码分析与机器学习
- 深度学习简介与现状
- 深度学习与密码分析
- 深度学习与密码设计
- 2.学习中遇到的问题及解决
- 3.本次讲座的学习感悟、思考等
- 4.“Machine Learning and Medicine”最新研究现状
- Machine Learning in Genomic Medicine: A Review of Computational Problems and Data Sets
- Prediction of post-operative implanted knee function using machine learning in clinical big data
- Classifying osteosarcoma patients using machine learning approaches
- A 128-Channel Extreme Learning Machine-Based Neural Decoder for Brain Machine Interfaces
- Recent machine learning advancements in sensor-based mobility analysis: Deep learning for Parkinson's disease assessment
- 参考资料
课程:《密码与安全新技术专题》
班级:1892
姓名:杨
学号:20189230
上课教师:金鑫
上课日期:2019年3月26日
必修/选修:选修
1.本次讲座的学习总结
讲座主题:基于深度学习的密码分析与设计初探
技术背景
• 人工智能、机器学习和深度学习的区别——
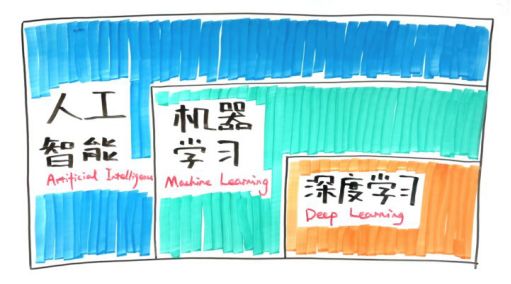
深度学习,作为目前最热的机器学习方法,但并不意味着是机器学习的终点。目前存在以下问题:
A.深度学习模型需要大量的训练数据,才能展现出神奇的效果,但现实生活中往往会遇到小样本问题,此时深度学习方法无法入手,传统的机器学习方法就可以处理;
B.有些领域,采用传统的简单的机器学习方法,可以很好地解决了,没必要非得用复杂的深度学习方法;
C.深度学习的思想,来源于人脑的启发,但绝不是人脑的模拟,举个例子,给一个三四岁的小孩看一辆自行车之后,再见到哪怕外观完全不同的自行车,小孩也十有八九能做出那是一辆自行车的判断,也就是说,人类的学习过程往往不需要大规模的训练数据,而现在的深度学习方法显然不是对人脑的模拟。
• 深度学习、迁移学习、强化学习、对抗学习的区别——
A.深度学习:
大数据造就了深度学习,通过大量的数据训练,我们能够轻易的发现数据的规律,从而实现基于监督学习的数据预测。
基于卷积神经网络的深度学习(包括CNN、RNN),主要解决的领域是图像、文本、语音,问题聚焦在分类、回归。
B.迁移学习:
迁移学习解决的问题是如何将学习到的知识从一个场景迁移到另一个场景?
这是一个普遍存在的问题,问题源自于你所关注的场景缺少足够的数据来完成训练,在这种情况下你需要通过迁移学习来实现模型本身的泛化能力。
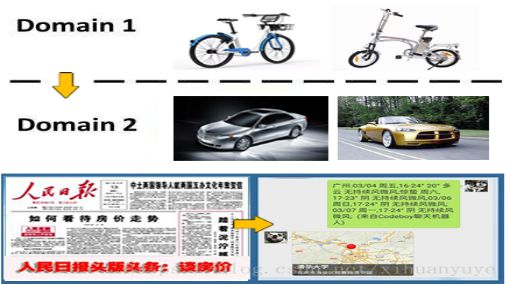
借用一张示意图来进行说明:

迁移学习的必要性和价值体现在:复用现有知识域数据,已有的大量工作不至于完全丢弃;不需要再去花费巨大代价去重新采集和标定庞大的新数据集,也有可能数据根本无法获取;对于快速出现的新领域,能够快速迁移和应用,体现时效性优势。
迁移学习算法的思路包括以下几种:通过原有数据和少量新领域数据混淆训练;将原训练模型进行分割,保留基础模型(数据)部分作为新领域的迁移基础;通过三维仿真来得到新的场景图像(OpenAI的Universe平台借助赛车游戏来训练);借助对抗网络 GAN 进行迁移学习的方法。
C.强化学习(反馈与修正):
强化学习全称是Deep Reinforcement Learning(DRL),其所带来的推理能力是智能的一个关键特征衡量,真正的让机器有了自我学习、自我思考的能力,毫无疑问Google DeepMind 是该领域的执牛耳者,其发表的 DQN 堪称是该领域的破冰之作。
目前强化学习主要用在游戏 AI 领域(有我们老生常谈的 AlphaGo)和机器人领域,除此之外,Google宣称通过强化学习将数据中心的冷却费用降低了40%,虽无法考证真伪,但我愿意相信他的价值。
强化学习是个复杂的命题,Deepmind大神David Silver将其理解为这样一种交叉学科:

实际上,强化学习是一种探索式的学习方法,通过不断“试错”来得到改进,不同于监督学习的地方是强化学习本身没有Label,每一步的Action之后它无法得到明确的反馈(在这一点上,监督学习每一步都能进行 Label 比对,得到 True or False)。
强化学习是通过以下几个元素来进行组合描述的:对象(Agent)、环境(Environment)、
动作 (Actions) 、奖励 (Rewards) 。
D.对抗学习
对抗学习网络GAN的基本原理其实非常简单,这里以生成图片为例进行说明。假设我们有两个网络,G(Generator)和D(Discriminator)。正如它的名字所暗示的那样,它们的功能分别是:是一个生成图片的网络,它接收一个随机的噪声z,通过这个噪声生成图片,记做G(z)。D是一个判别网络,判别一张图片是不是“真实的”。它的输入参数是x,x代表一张图片,输出D(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片。
在训练过程,生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。而D的目标就是尽量把G生成的图片和真实的图片分别开来。这样,G和D构成了一个动态的“博弈过程”。
最后博弈的结果是什么?在最理想的状态下,G可以生成足以“以假乱真”的图片G(z)。对于D来说,它难以判定G生成的图片究竟是不是真实的,因此D(G(z)) = 0.5。
密码分析与机器学习
• 密码分析与机器学习之间有天然的相似性

深度学习简介与现状
• 深度学习的五大挑战及其解决方案——
A.(1)挑战1:标注数据代价昂贵:
深度学习训练一个模型需要很多的人工标注的数据。例如在图像识别里面,经常我们可能需要上百万的人工标注的数据,在语音识别里面,我们可能需要成千上万小时的人工标注的数据,机器翻译更是需要数千万的双语句对做训练,在围棋里面DeepMind当初训练这个模型也用了数千万围棋高手走子的记录,这些都是大数据的体现。
但是,很多时候找专家来标注数据是非常昂贵的,并且对一些应用而言,很难找到大规模的标注的数据,例如一些疑难杂症,或者是一些比较稀有的应用场景。
(2)前沿1:从无标注的数据里学习:
现在已经有相关的研究工作,包括最近比较火的生成式对抗网络,以及对偶学习。

生成式对抗网络的主要目的是学到一个生成模型,这样它可以生成很多图像,这种图像看起来就像真实的自然图像一样。它解决这个问题的思路是同时学习两个神经网络:一个神经网络生成图像,另外一个神经网络给图像进行分类,区分真实的图像和生成的图像。在生成式对抗网络里面,第一个神经网络也就是生成式神经网络,它的目的是希望生成的图像非常像自然界的真实图像,这样的话,那后面的第二个网络,也就是那个分类器没办法区分真实世界的图像和生成的图像;而第二个神经网络,也就是分类器,它的目的是希望能够正确的把生成的图像也就是假的图像和真实的自然界图像能够区分开。大家可以看到,这两个神经网络的目的其实是不一样的,他们一起进行训练,就可以得到一个很好的生成式神经网络。
对偶学习的思路和前面生成式对抗学习会非常不一样。对偶学习的提出是受到一个现象的启发:我们发现很多人工智能的任务在结构上有对偶属性。比如说在图像理解里面,看图说话,也就是给一张图生成一句描述性的语句,它的对偶任务是给一句话生成一张图,这两个任务一个是从图像到文本,另外一个是从文本到图像。在搜索引擎里面,给定检索词返回相关文档和给定文档或者广告返回关键词也是互为对偶的问题:搜索引擎最主要的任务是针对用户提交的检索词匹配一些文档,返回最相关的文档;当广告商提交一个广告之后,广告平台需要给他推荐一些关健词使得他的广告在用户搜索这些词能够展现出来被用户点击。因此我们可以通过这种对偶过程从无标注的数据获得反馈信息,知道我们的模型工作的好还是不好,进而根据这些反馈信息来训练更新正向反向模型,从而达到从无标注数据学习的目的。

B.(1)挑战2:大模型不方便在移动设备上使用:
现在常见的模型,像图像分类里面,微软设计的深度残差网络,模型大小差不多都在500M以上。比如说手机输入法,还有各种对图像做变换做处理做艺术效果的app,如果使用深度学习的话效果会非常好,但是这种模型由于它们的size太大,就不太适合在手机上应用。
因此当前深度学习面临的第二个挑战就是如何把大模型变成小模型,这样可以在各种移动设备上使用。因为移动设备不仅仅是内存或者存储空间的限制,更多是因为能耗的限制,不允许我们用太大的模型。
(2)前沿2:降低模型大小:
第一种方法是针对计算机视觉里面的CNN模型,也就是卷积神经网络,做模型压缩;第二种方法是针对一些序列模型或者类似自然语言处理的RNN模型如何做一个更巧妙的算法,使得它模型变小,并且同时精度没有损失。
对卷积神经网络而言,主要是采用模型压缩的技术缩减模型的大小。模型压缩的技术,可以分为四类:

一个是叫剪枝,神经网络主要是由一层一层的节点通过边连接,每个边上有些权重。如果我们发现某些边上的权重很小,这样的边可能不重要,这些边就可以去掉。我们在把大模型训练完之后,看看哪些边的权重比较小,把这些边去掉,然后在保留的边上重新训练模型;
模型压缩的另外一种做法就是通过权值共享。假设相邻两层之间是全连接,每层有一千个节点,那么这两层之间有一千乘一千也就是一百万个权值(参数)。对一百万个权值做聚类,看看哪些权值很接近,可以用每个类的均值来代替这些属于这一类的权值,这样很多边(如果他们聚在同一类)共享相同的权值。如果我们把一百万个数聚成一千类,就可以把参数的个数从一百万降到一千个,这也是一个非常重要的一个压缩模型大小的技术。
还有一个技术可以认为是权值共享的更进一步,叫量化。深度神经网络模型的参数都是用的浮点型的数表达,32bit长度的浮点型数。实际上没必要保留那么高的精度,我们可以通过量化,比如说就用0到255表达原来32个bit所表达的精度,通过牺牲精度来降低每一个权值所需要占用的空间。
这种量化的更极致的做法就是第四类的技术,叫二制神经网络。所谓二制神经网络,就是所有的权值不用浮点数表达了,就是一个二进制的数,要么是+1要么是-1,用二进制的方式来表达,这样原来一个32 bit权值现在只需要一个bit来表达,从而大大降低这个模型的尺寸。

上面这张图显示了多种模型压缩的技术在不同卷积神经网络上的结果。随着原始网络大小的不同,得到的压缩比是不一样的,特别是VGGNet,一个非常重要的卷积神经网络,能够把大小从原来的550M压缩到11M,并且让人惊奇的是,压缩后分类的准确率没有下降,反而略微有一点提高,这是非常了不起的。
除了模型压缩的方法之外,还可以通过设计更精巧的算法来降低模型大小。

算法的基本思想是:不是用一个向量来表达一个词,而是用两个向量表达一个词,一个行向量+一个列向量,不同的词之间共享行或列向量。我们用一个二维的表格来表达整个词表,假设这个二维的表格有一千行一千列,这个表格可以表达一百万个词;这个表格的每一行有一个行向量,每一列有一个列向量,这样整个二维表格只需要两千个向量,这样大大降低词嵌入向量模型的大小。
在公共的数据集上做测试,结果表明LightRNN算法极大的减小了模型的尺寸,可以把原来语言模型的大小从4G降到40M左右,当这个模型只有40兆的时候,很容易使得我们在移动设备或者是GPU上使用。
C.(1)挑战3:大计算需要昂贵的物质、时间成本:
大计算说起来容易,其实做起来非常不容易,非常不简单。比如说AlphaGo,它也需要非常大量的计算资源。AlphaGo的模型包含一个策略神经网络,还有一个值网络,这两个都是卷积神经网络。它的策略网络用了50块GPU做训练,训练了3个周,值网络也是用了50块GPU,训练了一周,因此它整个的训练过程用了50块CPU四周时间,差不多一个月。
(2)前沿3:全新的硬件设计、算法设计、系统设计:
因此深度学习所面临的第三个挑战是如何设计一些更高级的算法,更快的算法,更有效的算法。手段可能是通过一些全新的硬件设计或者是全新的算法设计,或者是全新的系统设计,使得这种训练能够大大的加速。
D.(1)挑战4:如何像人一样从小样本进行有效学习?
一般来说,通过在驾校的培训,也就是几十个小时的学习,几百公里的练习,大多数人就可以开车上路了,但是像现在的无人车可能已经行驶了上百万公里,还是达不到人的全自动驾驶的水平。原因在于,人经过有限的训练,结合规则和知识能够应付各种复杂的路况,但是当前的AI还没有逻辑思考、联想和推理的能力,必须靠大数据来覆盖各种可能的路况,但是各种可能的路况几乎是无穷的。
这种知识很容易通过语言进行传授,但是对于一个AI或者对于一个深度学习算法而言,如何把这种知识转化成实际模型的一部分,怎么把数据和知识结合起来,提高模型的训练的速度或者是识别的精度,这是一个很复杂的问题。
(2)前沿4:数据+知识,深度学习与知识图谱、逻辑推理、符号学习相结合:
人工智能国际顶级会议AAAI 2017的最佳论文奖,颁给了一个利用物理或者是一些领域的专业知识来帮助深度神经网络做无标注数据学习的项目。

论文里的具体例子是上面这张图里面一个人扔枕头的过程,论文想解决的问题是从视频里检测这个枕头,并且跟踪这个枕头的运动轨迹。如果我们没有一些领域的知识,就需要大量的人工标注的数据,比如说把枕头标注出来,每帧图像的哪块区域是枕头,它的轨迹是什么样子的。实际上因为我们知道,枕头的运动轨迹应该是抛物线,二次型,结合这种物理知识,我们就不需要标注的数据,能够把这个枕头给检测出来,并且把它的轨迹准确的预测出来。这篇论文之所以获得了最佳论文奖,也是因为它把知识和数据结合起来,实现了从无标注数据进行学习的可能。
E.(1)挑战5:如何从认知性的任务扩展到决策性任务?
人的智能包含了很多方面,最基本的阶段是认知性智能,也就是对整个世界的认知。我们看到一幅图能知道里面有什么,我们听到一句话知道在说文字。现在对于图象识别、语音识别,AI已经差不多能达到人类的水平,当然可能是在某些特定的约束条件下,能够达到人类的水平。但是其实这种认知性的任务,对人类而言都是非常简单的,比如说一个三五岁的小孩子已经能做得很好了,现在AI所能做的这种事情或者能达到的水平,人其实也很容易做到,只是AI可能在速度上更快,并且规模上去之后成本更低,并且24小时都不需要休息。更有挑战的问题是,人工智能能不能做一些人类做不了或者是很难做好的事情。
像图象识别、语音识别这类认知性的任务,AI之所以做得好,是因为这些任务是静态的,所谓静态就是给定输入,预测结果不会随着时间改变。但是决策性问题,往往和环境有很复杂的交互,在某些场景里面,如何做最优决策,这些最优决策往往是动态的,会随着时间改变。
(2)前沿5:博弈机器学习
现在有人尝试把AI用到金融市场,例如如何用AI技术来分析股票,预测股票涨跌,对股票交易给出建议,甚至是代替人来进行股票交易,这类问题就是动态决策性问题。同样一支股票同样的价格,在一周前可能是值得买入,但是一周之后可能就要卖出了,同样一个事件或者是政治新闻比如说是在总统大选之前发生还是之后发生,对股票市场的影响也完全不一样。所以决策问题的一个难点就在于时变性。
决策性问题的第二个难点在于各种因素相互影响,牵一发而动全身。一支股票的涨跌会对其他股票产生影响,一个人的投资决策,特别是大的机构的投资决策,可能会对整个市场产生影响,这就和静态的认知性任务不一样的。在静态认知性任务我们的预测结果不会对问题(例如其他的图像或者语音)产生任何影响,但是在股票市场,任何一个决定,特别是大的机构的投资策略会对整个市场产生影响,对别的投资者产生影响,对将来会产生影响。无人驾驶某种程度上也是比较类似的,一辆无人车在路上怎么行驶,是由环境和很多车辆共同决定的,当我们通过AI来控制一辆车的时候,我们需要关注周围的车辆,因为我们要考虑到周围的车辆对于当前这个无人车的影响,以及我们无人车(如左转右转或者并线)对周围车辆的影响。
当前深度学习已经在静态任务里面取得了很大的成功,如何把这种成功延续和扩展到这种复杂的动态决策问题中,也是当前一个深度学习的挑战之一。我们认为,一个可能的思路是博弈机器学习。在博弈机器学习里,通过观察环境和其他个体的行为,对每个个体构建不同的个性化行为模型,AI就可以三思而后行,选择一个最优策略,该策略会自适应环境的变化和其他个体的行为的改变。
深度学习与密码分析
• 基于卷积神经网络的侧信道攻击
• 基于循环神经网络的明文破译
• 基于生成对抗网络的口令破解
• 基于深度神经网络的密码基元识别
• 深度学习最新进展:
A.多通道深度神经网络
B.级联深度神经网络
C.多任务深度神经网络
D.知识驱动的深度学习
E.深度森林
gcForest(muti-Grained Cascade Forest,多粒度串联森林),它是基于树的集成方法,通过对树组成的森林来集成并前后串联起来达到表征学习的效果。它的表征学习能力可以通过对高维输入数据的多粒度扫描而进行加强。串联的层数也可以通过自适应的决定从而使得模型复杂度不需要成为一个自定义的超参数,而是一个根据数据情况而自动设定的参数。值得注意的是,gcForest会比DNN有更少的超参数,更好的一点在于gcForest对参数是有非常好的鲁棒性,哪怕用默认参数也可以获得很棒的结果。换句话来说,gcForest相对于DNN,不仅超参数更少,而且对超参数的依赖性也更低。因为这样,gcForest的训练更为便捷,理论分析也更为清晰,这并不是说树比神经网络更好去解释,就单纯从超参数来说,更少超参数意味着更少的主观设定(虽然设定超参数也是结果导向的,但通常为什么要这么设是没有一个很好的理由去解释)。周教授说,在他们的实验中,gcForest不仅仅效果可以媲美DNN,而且单机跑gcForest所需的时间与带GPU加速跑DNN是相仿的,因为gcForest是可以并行计算。
固然gcForest并非为了替代DL而生,而是由于DL在很多情况下,对数据量、超参数调优、设备计算能力都有很高的要求,所以gcForest希望是能在某些场合替代高开销的DNN。
F.图深度学习
深度学习与密码设计
详见前文对抗学习部分。
2.学习中遇到的问题及解决
- 问题1:什么是卷积神经网络中的通道?
- 问题1解决方案:
在深度学习的算法学习中,都会提到 channels这个概念。在一般的深度学习框架的 conv2d中,如tensorflow 、mxnet ,channels 都是必填的一个参数。channels 究竟该如何理解呢?
首先,是tensorflow 中给出的,对于输入样本中channels的含义。一般的RGB图片,channels 数量是3(红、绿、蓝);而monochrome图片,channels 数量是 1 。
其次,mxnet 中提到的,一般 channels 的含义是,每个卷积层中卷积核的数量。 - 问题2:什么是级联神经网络中的交叉验证方法?
- 问题2解决方案:
交叉验证(Cross-validation)是为了避免神经网络产生过拟合,而在一种统计学上将数据样本切割成较小子集的实用方法。运用交叉验证把 CNN 的一部训练集区分出来,当作验证集,而用剩余的训练集来对CNN 中各神经网络进行测试训练,此时,验证集对于各神经网络来说是未知的。各神经网络训练的预测误差对于验证集来说是一个衡量其月度预测误差的标准,神经网络的泛化能力,所谓泛化能力(generalization ability)是指机器学习算法对新鲜样本的适应能力。学习的目的是学到隐含在数据对背后的规律,对具有同一规律的学习集以外的数据,经过训练的网络也能给出合适的输出,也能得到评估。训练和验证的结果越相似,则说明交叉验证的效果越好。各神经网络训练阶段的每一步进程都受验证误差(验证误差为验证集的误差)的限制,当各神经网络在训练时开始出现过拟合,验证误差也会开始上涨,当验证误差上涨到一定限值时,训练将提前终止,从而很准确地防止了过拟合现象的产生。 - 问题3:深度学习中的多任务模式有哪些好处?
- 问题3解决方案:
一旦发现正在优化多于一个的目标函数, 你就可以通过多任务学习来有效求解;即使对于最特殊的情形下你的优化目标只有一个, 辅助任务仍然有可能帮助你改善主任务的学习性能, 多任务学习通过使用包含在相关任务的监督信号中的领域知识来改善泛化性能。 - 问题4:为什么多任务学习有效?
- 问题4解决方案:
定义两个任务A和B, 两者的共享隐藏层用F表示。
隐式数据增加机制。多任务学习有效的增加了训练实例的数目。由于所有任务都或多或少存在一些噪音, 同时学习到两个任务可以得到一个更为泛化的表示。如果只学习任务A要承担对任务A过拟合的风险, 然而同时学习任务A与任务B对噪音模式进行平均, 可以使得模型获得更好表示F。
注意力集中机制。若任务噪音严重, 数据量小, 数据维度高, 则对于模型来说区分相关与不相关特征变得困难。 多任务有助于将模型注意力集中在确实有影响的那些特征上, 是因为其他任务可以为特征的相关与不相关性提供额外的证据。
窃听机制。对于任务B来说很容易学习到某些特征G, 而这些特征对于任务A来说很难学到。这可能是因为任务A与特征G的交互方式更复杂, 或者因为其他特征阻碍了特征G的学习。 通过多任务学习, 我们允许模型窃听, 即任务A使用任务B来学习特征G。
表示偏置机制。多任务学习更倾向于学习到一类模型, 这类模型更强调与其他任务也强调的那部分表示。 由于一个对足够多的训练任务都表现很好的假设空间, 对来自于同一环境的新任务也会表现很好, 所以这样有助于模型展示出对新任务的泛化能力。
正则化机制。 多任务学习通过引入归纳偏置起到与正则化相同的作用, 它减小了模型过拟合的风险, 降低了拟合随机噪声的能力。 - 问题5:知识驱动的深度学习方法有哪些瓶颈?
- 问题5解决方案:
不确定性问题;自学习问题;处理效率问题(这个问题很容易理解,传统的专家系统在一个细分领域还能初步覆盖大部分知识,人工建立规则也不是太困难。但在大数据时代,面对多源异构的海量数据,面对环境的动态变化,面对增量的学习等等问题,人工或者半自动化设立规则系统都太重量级了。)
3.本次讲座的学习感悟、思考等
通过本次讲座金老师详细全面的讲解和课下老师布置的作业,我觉得我对人工智能领域的认识又加深了许多。之前我对这个领域的了解只停留在用模式识别方法处理图像这方面,对机器学习和深度学习更是一知半解。老师的讲解激发了我的兴趣,我在课下浏览了许多这个方面的普及知识,知道原来人工智能也分弱人工智能、强人工智能和超级人工智能三种,我们现在生活中所使用的只称得上是弱人工智能。我观看了美国电影《人工智能》,这是一部多年前的电影,但其中所畅想的未来社会的强人工智能和超级人工智能还是令人浮想联翩。我想,也许现在的我们就站在人类发展节点而不自知,未来5年、10年,谁又知道会发生什么变化呢?

4.“Machine Learning and Medicine”最新研究现状
Machine Learning in Genomic Medicine: A Review of Computational Problems and Data Sets
Proceedings of the IEEE ( Volume: 104 , Issue: 1 , Jan. 2016 )
作者信息:
•Michael K. K. Leung
•Andrew Delong
•Babak Alipanahi
研究进展:
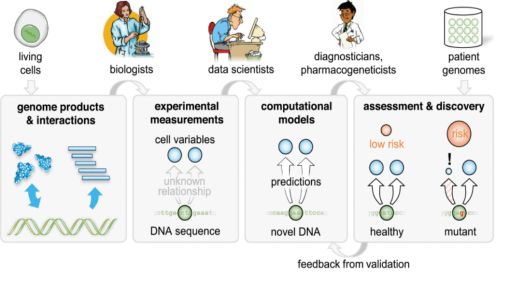
文章介绍了解决基因组医学中重要问题的机器学习任务。基因组医学的目标之一是确定个体DNA的变异如何影响不同疾病的风险,并找到因果解释,以便设计有针对性的治疗方法。这里将重点放在机器学习如何帮助建立DNA和细胞中关键分子数量之间的关系,前提是这些数量,我们称之为细胞变量,可能与疾病风险有关。现代生物学允许对许多这样的细胞变量进行高通量测量,包括基因表达、剪接和与核酸结合的蛋白质,这些都可以作为预测模型的训练目标。随着大规模数据集和深度学习等先进计算技术的日益普及,研究人员可以帮助开创一个有效基因组医学的新时代。
Prediction of post-operative implanted knee function using machine learning in clinical big data
2016 International Conference on Machine Learning and Cybernetics (ICMLC)
作者信息:
•Syoji Kobashi
•Belayat Hossain
•Manabu Nii
研究进展:
全膝关节置换术是一种常见的膝关节手术。由于TKA植入物有多种类型,很难为个体患者选择合适的TKA植入物类型。为了便于术前计划,研究提出了一种新的方法来预测个体术后植入的膝关节功能。它基于临床大数据分析。大数据由一组术前膝关节活动功能和术后膝关节功能组成。该方法采用机器学习的方法建立了术后膝关节功能预测模型。采用主成分分析法提取特征,构造了从术前特征空间到术后特征空间的映射函数。通过对52例TKA手术膝关节术后前后平移的预测,验证了该方法的有效性。漏掉一次交叉验证试验显示预测性能,平均相关系数为0.79,平均均方根误差为3.44mm。

Classifying osteosarcoma patients using machine learning approaches
2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC)
作者信息:
•Zhi Li
•Yingqi Hua
研究进展:
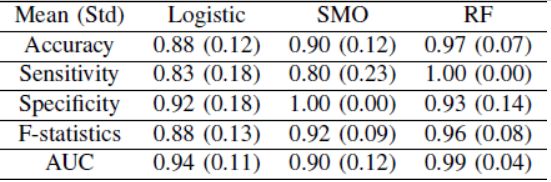
代谢组学数据分析为我们进一步了解骨肉瘤提供了一个独特的机会,骨肉瘤是一种常见的骨恶性肿瘤,基因组学和蛋白质组学的研究取得了有限的成功。代谢学研究的主要目标之一是对早期骨肉瘤进行分类,这是转移切除治疗所必需的。本文采用逻辑回归、支持向量机(SVM)和随机森林(RF)三种分类方法对sjtu小组收集的骨肉瘤患者的代谢数据进行分类。利用接收机工作特性曲线对其性能进行了评价和比较。三个分类器均能成功区分健康对照组和肿瘤病例,在训练集交叉验证方面,随机森林优于其他两个分类器(逻辑回归、支持向量机和随机森林的准确率分别为88%、90%和97%)。随机森林在测试集上的总准确率为95%,AUC为0.99。
A 128-Channel Extreme Learning Machine-Based Neural Decoder for Brain Machine Interfaces
IEEE Transactions on Biomedical Circuits and Systems ( Volume: 10 , Issue: 3 , June 2016 )
作者信息:
•Yi Chen
•Enyi Yao
研究进展:
目前,最先进的脑机接口运动意向解码算法大多在PC机上实现,消耗大量的能量。文章提出了一种0.35μm CMOS的机器学习协处理器,用于脑机接口中的运动意图解码。利用极限学习机算法和低功耗模拟处理,以50赫兹的分类率实现了3.45 pj/mac的能效。第二阶段的学习和相应的数字存储系数用于提高核心模拟处理器的鲁棒性。用猴指运动实验记录的神经数据对该芯片进行了验证,运动类型译码精度达到99.3%。同样的协处理器也被用来解码异步神经尖峰的运动时间。随着时间延迟特征维数的增强,在输入通道数目有限的情况下,分类精度可提高5%。此外,稀疏性促进训练方案使可编程权重减少≈2倍。

Recent machine learning advancements in sensor-based mobility analysis: Deep learning for Parkinson's disease assessment
2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC)
作者信息:
• Bjoern M. Eskofier
• Sunghoon I. Lee
• Jean-Francois Daneault
研究进展:
可穿戴传感器的发展为长期评估运动障碍打开了大门。然而,仍然需要开发适合于监测临床内外运动症状的方法。文章旨在探讨深度学习作为一种监测方法。深度学习最近打破了语音和图像分类的记录,但作为一种分析可穿戴传感器数据的潜在方法,它还没有得到充分的研究。我们使用惯性测量单位收集了10名特发性帕金森病患者的数据。一些运动任务被贴上了专家标签并用于分类。我们特别关注缓激症的检测。为此,我们将标准机器学习管道与基于卷积神经网络的深度学习进行了比较。结果表明,在分类率方面,深度学习优于其他最先进的机器学习算法至少4.6%。文章讨论了传感器运动评估中深度学习的优缺点,认为深度学习是一种很有前途的方法。

参考资料
Machine Learning in Genomic Medicine: A Review of Computational Problems and Data Sets
Prediction of post-operative implanted knee function using machine learning in clinical big data
Classifying osteosarcoma patients using machine learning approaches
A 128-Channel Extreme Learning Machine-Based Neural Decoder for Brain Machine Interfaces
Recent machine learning advancements in sensor-based mobility analysis: Deep learning for Parkinson's disease assessment