纵览轻量化卷积神经网络SqueezeNet,MobileNet,ShuffleNet
1. SqueezeNet
具体如下图所示:
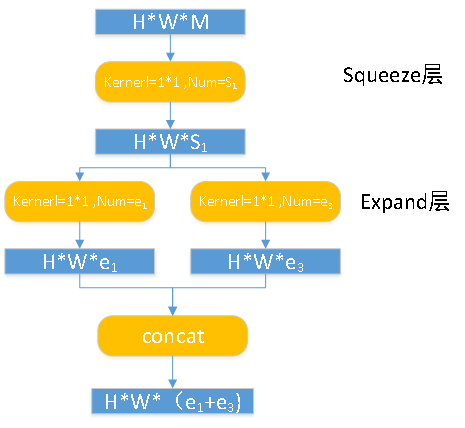
Fire module 输入的 feature map 为 H*W*M 的,输出的 feature map 为 H*M*(e1+e3),可以看到 feature map 的分辨率是不变的,变的仅是维数,也就是通道数,这一点和 VGG 的思想一致。
SqueezeNet提出了3点网络结构设计策略:
策略 1.将3x3卷积核替换为1x1卷积核。
这一策略很好理解,因为1个1x1卷积核的参数是3x3卷积核参数的1/9,这一改动理论上可以将模型尺寸压缩9倍。
策略 2.减小输入到3x3卷积核的输入通道数。
我们知道,对于一个采用3x3卷积核的卷积层,该层所有卷积参数的数量(不考虑偏置)为:
![]()
式中,N是卷积核的数量,也即输出通道数,C是输入通道数。
因此,为了保证减小网络参数,不仅仅需要减少3x3卷积核的数量,还需减少输入到3x3卷积核的输入通道数量,即式中C的数量。
策略 3.尽可能的将降采样放在网络后面的层中。
在卷积神经网络中,每层输出的特征图(feature map)是否下采样是由卷积层的步长或者池化层决定的。而一个重要的观点是:分辨率越大的特征图(延迟降采样)可以带来更高的分类精度,而这一观点从直觉上也可以很好理解,因为分辨率越大的输入能够提供的信息就越多。
2. MobileNet
1. 核心思想是采用 depth-wise convolution 操作,在相同的权值参数数量的情况下,相较于 standard convolution 操作,可以减少数倍的计算量,从而达到提升网络运算速度的目的。
2. depth-wise convolution 的思想非首创,借鉴于 2014 年一篇博士论文:《L. Sifre. Rigid-motion scattering for image classification. hD thesis, Ph. D. thesis, 2014》
3. 采用 depth-wise convolution 会有一个问题,就是导致「信息流通不畅」,即输出的 feature map 仅包含输入的 feature map 的一部分,在这里,MobileNet 采用了 point-wise convolution 解决这个问题。在后来,ShuffleNet 采用同样的思想对网络进行改进,只不过把 point-wise convolution 换成了 channel shuffle,然后给网络美其名曰 ShuffleNet
假设输入的 feature map 是两个 5*5 的,即 5*5*2;输出 feature map 数量为 3,大小是 3*3(因为这里采用 3*3 卷积核)即 3*3*3。标准卷积是将一个卷积核(3*3)复制 M 份(M=2), 让二维的卷积核(面包片)拓展到与输入 feature map 一样的面包块形状。
Standard 过程如下图,X 表示卷积,+表示对应像素点相加,可以看到对于 O1 来说,其与输入的每一个 feature map 都「发生关系」,包含输入的各个 feature map 的信息。
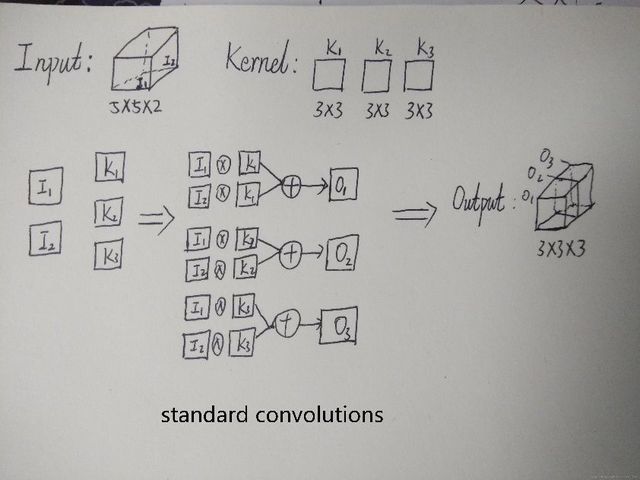
Depth-wise 过程如下图,可以看到 depth-wise convolution 得出的两个 feature map——fd1 和 fd2 分别只与 i1 和 i2「发生关系」,这就导致违背上面所承认的观点「输出的每一个 feature map 要包含输入层所有 feature map 的信息」,因而要引入 pointwise convolution。

计算量减少了:
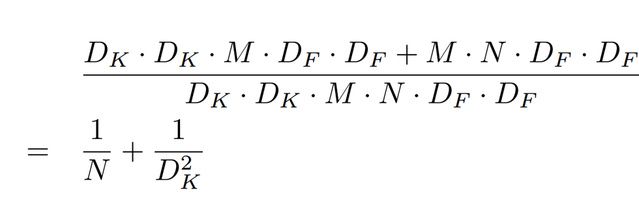
其中 DK 为标准卷积核大小,M 是输入 feature map 通道数,DF 为输入 feature map 大小,N 是输出 feature map 大小。本例中,DK=3,M=2,DF=5,N=3,参数的减少量主要就与卷积核大小 DK 有关。在本文 MobileNet 的卷积核采用 DK=3,则大约减少了 8~9 倍计算量。
3. ShuffleNet
shuffle 具体来说是 channel shuffle,是将各部分的 feature map 的 channel 进行有序的打乱,构成新的 feature map,以解决 group convolution 带来的「信息流通不畅」问题。(MobileNet 是用 point-wise convolution 解决的这个问题)
ShuffleNet unit 的演化过程
图 (a):是一个带有 depth-wise convolution 的 bottleneck unit;图 (b):作者在 (a) 的基础上进行变化,对 1*1 conv 换成 1*1 Gconv,并在第一个 1*1 Gconv 之后增加一个 channel shuffle 操作;图 (c): 在旁路增加了 AVG pool,目的是为了减小 feature map 的分辨率;因为分辨率小了,于是乎最后不采用 Add,而是 concat,从而「弥补」了分辨率减小而带来的信息损失。

ShuffleNet 小结:
1. 与 MobileNet 一样采用了 depth-wise convolution,但是针对 depth-wise convolution 带来的副作用——「信息流通不畅」,ShuffleNet 采用了一个 channel shuffle 操作来解决。
2. 在网络拓扑方面,ShuffleNet 采用的是 resnet 的思想,而 mobielnet 采用的是 VGG 的思想,
2.1 SqueezeNet 也是采用 VGG 的堆叠思想
https://baijiahao.baidu.com/s?id=1589005428414488177&wfr=spider&for=pc