非常开心地迎来了OO第一次放松,当我准备安装好插件,做好图,弄好数据就来写博客时,才发现第一步我就过不去了。
安装AmaterasUML
Amateras是用来自动生成类图的插件。
教程:https://www.cnblogs.com/xiluhua/p/6667935.html
当我一切都按教程做了,理直气壮地点开New ——> Other,并没有教程所说的class diagram,连个Amateras的folder都没有。我一度怀疑我eclipse重启得不够给力,多次restart甚至重启电脑。
如果你也是这样,试试我找到的偏方吧:
解决方法是:
1、打开命令行,到当前eclipse的目录下,输入eclipse -clean,重新启动eclipse,这样eclipse就会加上新插件了。
2、如果插件不能升效,则请将eclipse\configuration\org.eclipse.update目录删除后再启动eclipse:)你可以在eclipse的菜单"Help"-->"About Eclipse SDK"-->"Feature Details" 和"Plug-in Details"中看到新安装的插件。
然后你再看看New ——> Other,就可以快乐地创建class diagram了。
安装Metrics
Metrics是基于度量分析代码的插件。
教程:https://blog.csdn.net/u014736978/article/details/41149767
但是!,但是!在安装之前,要确认一下自己的是eclipse3.X,如果你使用的是助教给的eclipse,是使用不了Metrics的。所以还是去官网下个最新版本吧~
以上是一点安装时遇上的坑,下面来分析自己的代码。
代码分析
第一次作业
度量分析
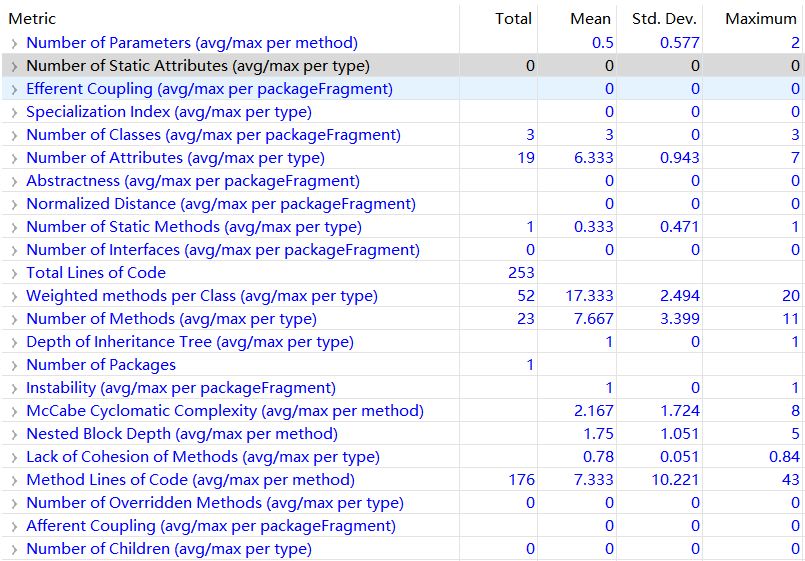
类图

第二次作业
度量分析
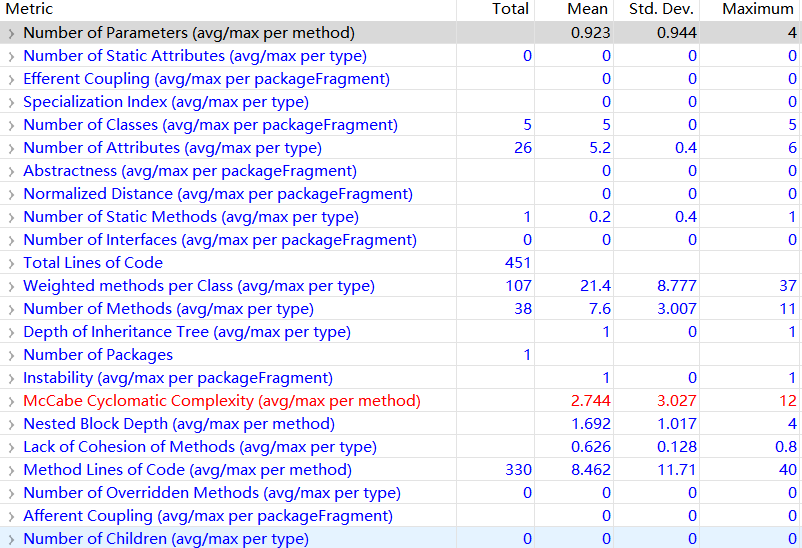
类图
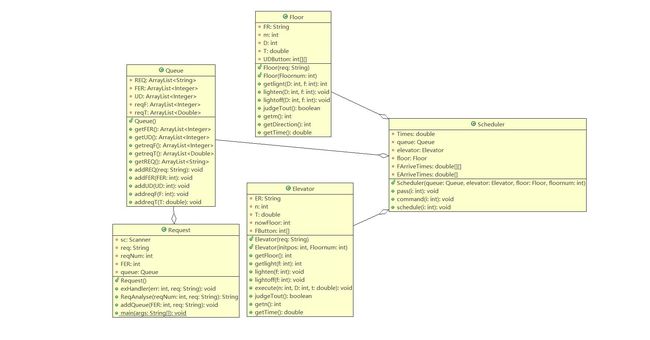
第三次作业
度量分析
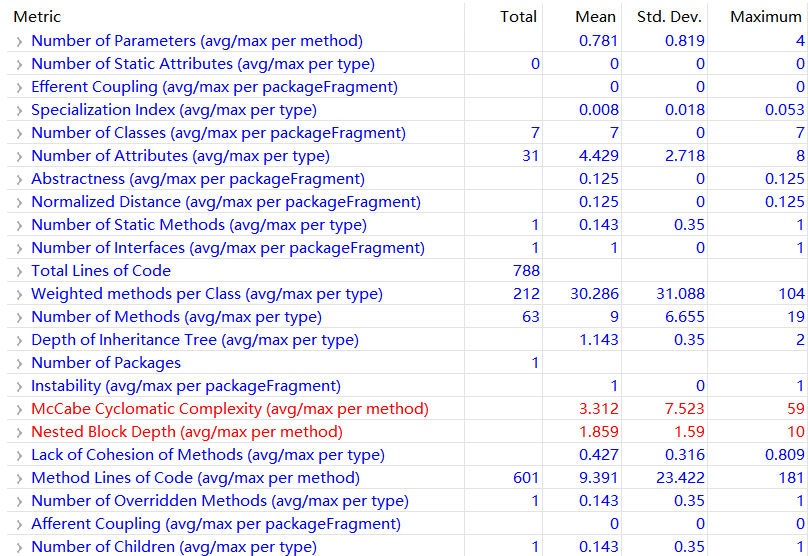
类图
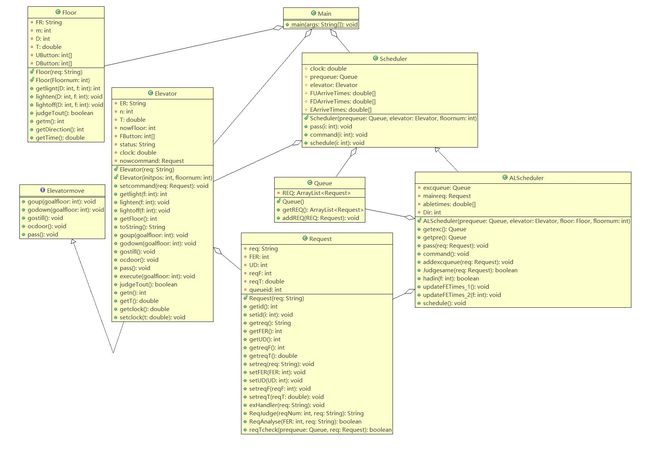
对于度量的分析
这里对标红的McCabe Cyclomatic Complexity和Nested Block Depth进行分析。(标红表示超出范围)
McCabe Cyclomatic Complexity 表示圈复杂度,圈复杂度用来衡量一个模块判定结构的复杂程度,圈复杂度大说明程序代码可能质量低且难于测试和维护。第二和第三次作业造成圈复杂度过高的原因均为调度器类中的schedule()方法。个人判断是我的代码的schedule()方法承担的职能过多,不仅要去除同质请求,还要选择可捎带请求,最后还要将请求排序形成可执行队列,对同质请求和可捎带请求的判断使用了过多的if判断语句,每个if判断条件也并不单一,导致了schedule()方法的圈复杂度过高。
Nested Block Depth表示嵌套块深度,嵌套深度表示if或者for或者while循环嵌套的个数。这里的嵌套块深度过大同样来自调度器类的schedule()方法。由于在形成可执行队列的时候对同质请求和可捎带请求同时做了判断,导致了过多的if语句和while循环多层嵌套。
其实这两特点在debug的时候已经能体会到了,过高的圈复杂度和嵌套块深度使得debug并没那么好受。
自我评价
优点:总……总得写出点优点吧。
1.对于请求的解析,我分为了两个部分,一是请求类的自我判断,二是电梯类和楼层类对请求内容的解析。另外,每个类的在程序中的职责划分还是很清晰的。
没有序号2了。
缺点:
1.初次接触面向对象编程,对于类的划分总与现实分不开。想用电梯类和楼层类解析请求源于想模仿电梯和楼层向调度器发生请求,于是又给电梯类增加了一个构造器。这样一来似乎使得电梯功能过于复杂。实际上,应该增加一个Inpu_Handler类来处理输入信息。
2.对于请求队列中同质请求和可捎带请求的判断,我都置于调度器中,使得调度器过于臃肿,并且在判断过程中又由于需要不断为调度器增加属性和方法,使得调度器越来越复杂。或许可以增加一个类用于筛选请求队列,再将可执行队列传给调度器。
3.能力不足,在设计的时候未能考虑到代码的维护与可扩展性。于是从第二次到第三次作业的过渡中还是出了不少问题。
OO三次作业以来,在各个部分花的功夫可以说是debug的时间 >> 划分类的时间 > 看指导书的时间 > 写bug的时间 >> 0。对类的划分仍然需要加以斟酌,使各个类的方法和属性更加明确,平衡各个类的负担。
有一个很深刻的教训就是,当觉得类的方法实现起来过于复杂过于长时,应该考虑一下是否让它承担了太多,而不是一味地在类中添加属性和方法,写的时候“算了,不管了,我就这样写”一时爽,等写完之后看着自己丑陋的代码和蹩脚的划分,重构的念头就开始萌生了,连提交的勇气的没有。
关于bug
自己程序的bug
1.第二次作业的程序被找出时间顺序判断不正确的bug。
测试样例:
(ER,1,0) (ER,5,100) (ER,1,0) RUN
在写代码,不对,在写bug的时候,很天真的把开始判断时间顺序是否不正确的起点设置为请求发生的时刻是否为0,而不是该请求之前是否有正确请求。
改正之前:
if(floor_req.getTime() != 0 && floor_req.getTime() < this.queue.get(this.queue.size()-1).Time) { //floor_req表示楼层请求,queue是请求队列
改正后:
if(this.queue.size() != 0 && floor_req.getTime() < this.queue.get(this.queue.size()-1).Time) { //floor_req表示楼层请求,queue是请求队列
2.第三次作业公测时间超范围的样例未通过。
测试样例:
(FR,1,UP,0) (ER,1,23333333333)//我已经感受到来自它的嘲笑 RUN
按道理这个对时间超范围的判断第二次作业通过了,第三次应该不成问题。并且截止日的前一天晚上还对多种输入不符合要求的点进行了测试,并没有发现问题。
程序员再一次遇到了灵异事件,T.T在公测结果出来之后,我的内心—— “我没动啊!”,“昨天晚上还是对的呢!”
于是发现在进行判断的时候出现了逻辑漏洞,难以解释,单独判断时间是否超范围时会出错。
写bug有风险,重构需谨慎。
找别人程序的bug
1.首先把所有符合评测要求的样例跑一遍,一般来说,是不会出现bug的;
2.嘿嘿嘿,然后就开始无赖的暴力了,把输入限制的参数100改成50000,用大样例RUN一下,把输出结果和自己的输出结果进行比对,这是找到bug最快速的方法之一。当然你不能保证自己的输出结果完全正确,万一比对之后发现的是计几的bug,周四晚上的觉是睡不好的,如果是别人的bug,则需要在100行内构造出他会出错的测试样例;
3.开始认真看代码,首先摸清楚代码整体的逻辑,然后看一些自己写过的bug是否在这也会出现,最后分析对方代码是否存在一些逻辑漏洞,比如正则表达式是否正确,临界时死循环,数组下标溢出等等,并为此精(惊)心构造测试样例。
心得体会
1.关于设计,其实很大程度上仍然没有摆脱面向过程的思想,在对类的设计中,更多地是关注这个类需要在整个控制流程中需要做些什么,而不是这个类本身自拥有的方法和属性。但其实大部分人都是一样的,思想的过渡不是一次多项式加减的作业就能完成的,还是需要多加练习和总结教训。应该先从类自拥有的属性和方法出发,去构造类之间的联系,先画好图再写代码。
2.第三次作业相信大家都对“神奇的bug无处不在”深有体会,尽管两个人校对完100行的样例都一模一样,当测试30000行的样例时,轮流debug的场景就出现了,当30000行样例校对完之后,新的样例又会让两人开始轮流debug。指导书老长老长的统一规定自身就带有复杂而难理解的逻辑,如果写代码之前没有把逻辑流程图理清楚,这个bug真的难杀。
3.从我拿到的作业来看,第二次拿到的作业模拟了时间0.5s、0.5s地进行,第三次拿到的作业则一条一条请求地进行寻找,对循环结束条件也不加以时间约束。虽然在构思程序之前这都是我所想尝试的,但个人更加追求程序运行的速度与性能,虽然这样自然而然地也给程序增加了逻辑复杂度,但一两秒跑完几万行的样例与十几秒跑完,我还是更青睐前者吧。希望能够和大家在程序设计和算法构思方面多多交流。
4.关于互评,互评水深,从我第一次被别人挂上一个交的是.cpp文件而不是.c文件的crash就体会到了。个人认为互评除了找到公测未能发现的bug之外,readme确实是很重要的部分,只要不是很牛角尖的抠readme都是可扣分的选项,所以在readme上也是需要花一定功夫的。关于程序的异常处理,我两次拿到的程序都没有进行异常处理,报告的bug还被助教删掉了,emmmmm至少意思意思的try和catch一下?
try{ //-------code------ }catch(Throwable a){ //to deal with }
如果有什么说得不好的地方,有什么建议和意见,欢迎大家评论指出~
嘻嘻,希望大家一起加油,干干干干干!