PHP自定义业务日志(monolog源码学习)
聊聊自己从开始工作到如今,对日志的认识。
在离校实习前,也多多少少做过一些自个玩的项目,后台管理系统、公众号都有整过,对所谓的日志没有什么概念,需要做什么记录都是操作数据库的自定义log表。
开始实习后,慢慢有接触到一些所谓日志的概念,最先接触的是ThinkPHP3.1的框架,不过有使用到的都是自定义打印日志,对想要记录的数组写入到自定义日志文件里。比如每次想要打印数据,调用一个公共函数,依赖系统函数fopen、fwrite、fclose,日志文件名以日期加调用方法名定义。
随着一天天的使用,到了某一日,也许是觉得这样的日志都集中在一个目录下,数量太过庞大;也许是觉得一个日志文件写入内容太多,如果是通过浏览器访问日志文件要等待特别久时间,甚至会卡死;也许是发现业务日志即调用即写入的方法,在并发量不低的情况下,导致不同用户的日志内容混杂,不利于排错;也许是发现了TP3.1项目Runtime内的代码执行LOG随时间、又随日志大小切割很好用;也许是看了TP3.1源码打印日志的部分,发现日志还能这么用。
也忘了具体是什么原因了,也许是一个个原因的积累,看到类似的话来形容:见识了光明,就不能忍受黑暗;见识了海阔天空,就不愿继续坐井观天。总之决定换个日志记录方式。
看了下TP3.1源码的日志实现部分,两个部分让我感觉像是发现了新大陆,一个是register_shutdown_function函数(细节不说明了,另外的博客里有详细解释),一个是每次调用日志,都将内容存在一个数组增量内,即保存在内存,在所有业务逻辑执行完成后,register_shutdown_function函数注册的方法将被执行,在此处将日志刷新到日志文件内,同时具体输出到哪个日志文件呢?这个也有讲究,首先日志文件名也是按照年月日来命令,但是在输出前,会优先判断当前日志文件的大小,若超过预定义最大值,则将当前文件重命名,加上时间戳的前缀来标识,新生成日志文件来存储日志。这种实现方式的好处在于,日志大容量被切割成多个文件,避免一个文件过大。个人认为也有不好的地方,比如所有日志文件都存储一个目录下,随着时间增长这个目录的文件数会越来越多。
日志暂存储在内存,封装后一次调用error_log函数打印。现在说来可能只是个基础的概念,不过对当时的自己来说,确实觉得神奇了好久。
想自己重新实现一种打印日志的方式,首先要满足几点要求:
1、日志能满足大小超过设置最大值后进行切割;
2、单个用户的请求日志,不会被并发影响,保证每次的排错日志相邻内容都是一个用户的;
3、可以根据不同的业务模块打印日志;
4、日志文件存储目录与日期相关,保证一个目录文件数不会太多,同时想定位到指定日期日志方便查找。
日志工具类实现源码:
>>>>>>{$logTitle}{$content}".PHP_EOL.PHP_EOL);
}
public static function close() {
if (empty(self::$logArr)) return;
$logPath = self::$logRootPath.date('Y_m_d');
//创建日志文件目录
if (!file_exists($logPath)) mkdir($logPath);
//逐个日志文件写入
foreach (self::$logArr as $key => $value) {
$logDir = $logPath . DIRECTORY_SEPARATOR . $key;
if (!file_exists($logDir)) mkdir($logDir);
self::logEnd($value, $logDir);
}
self::$logArr = null;
}
public static function logEnd($data, $logDir) {
foreach ($data as $k => $v) {
//获取日志文件名 避免单个日志文件太大
$count = 1;
while(true) {
//生成日志文件名
$logFile = "{$logDir}" . DIRECTORY_SEPARATOR . "{$k}_{$count}.log";
//第一次写入日志
if (!is_file($logFile)) break;
//日志文件200M切割 byte / 1024 / 1024 = kb / 1024 = mb
$file = filesize($logFile) / 1024 / 1024;
if ($file < 200) break;
$count++;
}
$v = rtrim($v);
$v .= PHP_EOL.'-----------------end----------------------'.PHP_EOL.PHP_EOL;
error_log($v, 3, $logFile);
}
}
}调用writeLog()方法,传入日志内容、日志目录名、日志文件名、日志titile信息,内容存储在全局静态数组内,在业务代码执行结束后,系统调用close()方法,将不同日志目录下的日志逐个打印,写入过程中判断日志文件大小是否超过预定义最大值,超过则生成新文件,以后缀1、2、3递增。
打印内容格式:
writeLog(["xxx"=>"aaa"], "xxxx", "xxxx", "请求报文");
writeLog(["sss"=>"qqq"], "xxxx", "xxxx", "返回报文");
----------------start---------------------
2018-08-06 14:35:01======>>>>>>>请求报文:{"xxx":"aaa”}
2018-08-06 14:35:01======>>>>>>>返回报文:{"sss":"qqq”}
-----------------end----------------------后续发现TP5的日志打印,对不同年月也做了目录分离的处理,在日志文件过大时做切割,保证一个目录内文件不过多,说明这个考虑还是有必要的。基于register_shutdown_function函数输出日志方式,在实践中发现确实不错,代码执行异常,仍能保证日志正常生成,对排错、查漏方面都有好处。
原本对业务日志生成方面减少了研究,源于学习composer基本使用过程中,发现monolog库被用的较多,不少好框架都直接依赖作为系统库。StreamHandler是输出到文件的处理器,也是基于调用即输出的方法;再有BufferHandler,不过暂时还不太满意,多条日志,基于循环分别执行fwrite,简单的并发测试,发现日志就会重合。暂时还没研究laravel是怎么来生成系统日志的,这个框架会是以后研究的一个主题。
日志打印到自定义目录暂时发现了两个Handler,好像不太满意,要不要用呢?答案是肯定的,主要原因是monolog遵循了PSR3规范,换个角度想,之前写的日志工具类,也许公司里其他人觉得可以,会沿用下。但是对外呢?不符合规范自成一套的东西,换我我也不一定乐意用,遵循规范,说不定哪天自己的小玩意儿被很多人认同,那会是个很开心的事情。
况且,monoglog的多样性也吸引了我,不同的Handler输出日志到不同的位置,syslog、邮件、文件、数据库等等;基于多样化formatter规范日志内容模版;日志分成多个级别,实现了整个库的功能解耦。即使我对目前认知的Handler即调用即打印不满意,也有解决办法,比如转换日志打印思路、比如自定义一个Handler,可以充分发挥自己的想象。
这篇内容原本想说说monolog简单应用过程的源码走向,不知不觉总结过往写了好多,步入下正题。
就以这段代码做个测试
'15', 'amount'=>'100', 'cardno'=>'11112222222'];
$monolog = new Monolog\Logger('Pay');
$monolog->pushHandler(new Monolog\Handler\StreamHandler('./logs/1.log'));
$monolog->warn(json_encode($post));执行后,查看logs目录的1.log文件,内容如下:
[2018-08-06 23:54:18] Pay.WARNING: {"age":"15","amount":"100","cardno":"11112222222"} [] []从这段代码中,拆解出来两块内容,
- Logger是个核心控制类,push新的Handler,warn打印日志
- StreamHandler是日志输出的实际操作类,定义输出的日志文件
先看下两个类的结构,Logger类实现了\Psr\Log\LoggerInterface接口,遵循PSR3规范。StreamHandler继承AbstractProcessingHandler,AbstractProcessingHandler继承AbstractHandler,AbstractHandler实现HandlerInterface接口,四层关系。
画图更直观,先参考下
Logger结构

StreamHandler结构

现在从日志打印开始到结束观察下代码的执行过程。
第一步:初始化Logger类,传入标识Logger的channel名称,例子中为Pay。Logger可以添加、删除Handler和Processor,Processor其实就是触发一些自定义的闭包函数对日志内容渲染处理,看下源码就明白是啥用处了。日志打印调用方法有很多,比如addDebug、addInfo、debug、Info等等,最终是调用了类内部的addRecord方法,在这里对日志打印逻辑做了封装。
第二步:实例化handler类,传入不同Handler需要的参数
第三步:调用Logger的warn方法打印日志
handler实例化和Logger进行pushHandler,就是存储一些参数,直接来看warn的实现吧
/**
* Adds a log record at the WARNING level.
*
* This method allows for compatibility with common interfaces.
*
* @param string $message The log message
* @param array $context The log context
* @return Boolean Whether the record has been processed
*/
public function warn($message, array $context = array())
{
return $this->addRecord(static::WARNING, $message, $context);
}转向到类内部的addRecord方法
来看下添加了注释的源码,
/**
* Adds a log record.
*
* @param int $level The logging level
* @param string $message The log message
* @param array $context The log context
* @return Boolean Whether the record has been processed
*/
public function addRecord($level, $message, array $context = array())
{
//如果未添加handler,默认添加一个stderr的StreamHandler
if (!$this->handlers) {
//stderr、stdin、stdout是cli模式下 系统的文件句柄
//如使用: fopen('php://stderr', 'w');
//执行fwrite会将错误信息发送到用户终端
$this->pushHandler(new StreamHandler('php://stderr', static::DEBUG));
}
//根据level级别获取levelName 如:100 ===>>> DEBUG
$levelName = static::getLevelName($level);
// check if any handler will handle this message so we can return early and save cycles
//检查是否起码存在一个handle
$handlerKey = null;
//将内部指针指向数组中的第一个元素,并输出
reset($this->handlers);
while ($handler = current($this->handlers)) { //返回当前数组指针指向的元素,若不存在则返回FALSE
//例如:level 200, 判断当前的handler 对应的level 是否小于200
//比如handler设置了DEBU => 200,可以输出任何level >= 200的日志,若level == 100,当前handler不能处理
if ($handler->isHandling(array('level' => $level))) {
//handler能够处理,将key值赋给handlerKey
$handlerKey = key($this->handlers);
break;
}
//当前handler不能处理此日志,将指针向后移动
next($this->handlers);
}
//未查找到能执行的handler,return终结
if (null === $handlerKey) {
return false;
}
//根据时区初始化DateTimeZone对象
if (!static::$timezone) {
static::$timezone = new \DateTimeZone(date_default_timezone_get() ?: 'UTC');
}
// php7.1+ always has microseconds enabled, so we do not need this hack
if ($this->microsecondTimestamps && PHP_VERSION_ID < 70100) {
$ts = \DateTime::createFromFormat('U.u', sprintf('%.6F', microtime(true)), static::$timezone);
} else {
$ts = new \DateTime(null, static::$timezone);
}
//以上代码经测试验证
//PHP5.6版本验证 ==>> 执行new \DateTime(null, static::$timezone); var_dump()发现:2018-08-01 23:01:38.000000
//结论:无法获得有效的毫秒时间
//PHP7.2版本验证 ==>> 两种方式执行 var_dump()发现:2018-08-01 23:09:45.891679
//结论:都能获得有效的毫秒时间
//因此对PHP版本做个判断,执行不一样的方法实例化DateTime对象,能够正确获取到毫秒时间
/*
\DateTime::createFromFormat() 执行后var_dump()如下:
class DateTime#3 (3) {
public $date =>
string(26) "2018-08-01 15:17:34.805013"
public $timezone_type =>
int(1)
public $timezone =>
string(6) "+00:00"
}
$ts->setTimeZone(static::$timezone); //执行后var_dump()如下:
class DateTime#3 (3) {
public $date =>
string(26) "2018-08-01 23:18:38.844745"
public $timezone_type =>
int(3)
public $timezone =>
string(3) "PRC"
}
new \DateTime() 执行后var_dump()如下:
class DateTime#2 (3) {
public $date =>
string(26) "2018-08-01 23:19:52.686156"
public $timezone_type =>
int(3)
public $timezone =>
string(3) "PRC"
}
结论:不同的执行方法,timezone字段可能未初始化赋值,因此调用setTimezone设置时区
* */
$ts->setTimezone(static::$timezone);
//日志内容封装
$record = array(
'message' => (string) $message,
'context' => $context, //数组
'level' => $level,
'level_name' => $levelName,
'channel' => $this->name,
'datetime' => $ts,
'extra' => array(),
);
//轮询判断是否存在闭包函数,通过闭包函数对record进行 “加工”
//闭包函数 可以当个变量传递,在需要的时候执行,方便!
foreach ($this->processors as $processor) {
$record = call_user_func($processor, $record);
}
//依据之前操作过数组指针的基础 继续进行处理,handlers数组头部的无效handler直接不管
while ($handler = current($this->handlers)) {
//return false === $this->bubble; handle最后的return语句
//bubble ==> 处理的消息是否可以冒泡堆栈 默认为true
//简单来说 设置为true的handler处理了日志后,下一个handler会继续执行;若设置false,下个handler不再执行
if (true === $handler->handle($record)) {
break;
}
//未执行成功,继续查找下一个handler执行
next($this->handlers);
}
return true;
}
逻辑到了handler的handle方法,看图可以知道是在抽象类AbstractProcessingHandler里。
/**
* {@inheritdoc}
*/
public function handle(array $record)
{
//判断当前日志 的level是否满足该handler的要求
if (!$this->isHandling($record)) {
return false;
}
//逐个回调processors的闭包函数,对record进行加工
$record = $this->processRecord($record);
//获取formatter,并执行formmatter的format方法,对record进行结尾处理
$record['formatted'] = $this->getFormatter()->format($record);
//调用handler自行编写的日志逻辑
$this->write($record);
//判断handler的栈是否冒泡
return false === $this->bubble;
}
调用format方法,是对日志内容做指定日志模版的转换,默认使用了LineFormatter(把日志记录格式化成一行字符串)。再调用StreamHandler的write方法写入日志。
protected function write(array $record)
{
//若stream未被初始化成resource
if (!is_resource($this->stream)) {
//若url为空,则无法初始化stream,抛出异常
if (null === $this->url || '' === $this->url) {
throw new \LogicException('Missing stream url, the stream can not be opened. This may be caused by a premature call to close().');
}
//创建文件目录
$this->createDir();
$this->errorMessage = null; //错误信息初始化,若出现异常,customErrorHandler会赋值
//设置error捕捉函数
set_error_handler(array($this, 'customErrorHandler'));
//打开日志文件,此时stream是一个resource 文件的句柄
$this->stream = fopen($this->url, 'a');
//若filePermission不为null,改动日志文件的权限
if ($this->filePermission !== null) {
//忽略错误
@chmod($this->url, $this->filePermission);
}
//去除error捕捉函数
restore_error_handler();
//stream初始错误,手动抛出异常
if (!is_resource($this->stream)) {
$this->stream = null;
throw new \UnexpectedValueException(sprintf('The stream or file "%s" could not be opened: '.$this->errorMessage, $this->url));
}
}
//若userLocking为true,加上锁,表示对日志文件进行堵塞处理
if ($this->useLocking) {
// ignoring errors here, there's not much we can do about them
flock($this->stream, LOCK_EX);
}
//日志写入
$this->streamWrite($this->stream, $record);
//释放日志文件锁
if ($this->useLocking) {
flock($this->stream, LOCK_UN);
}
}
/**
* Write to stream
* @param resource $stream
* @param array $record
*/
protected function streamWrite($stream, array $record)
{
//写入日志信息要resouce对应的文件
fwrite($stream, (string) $record['formatted']);
}
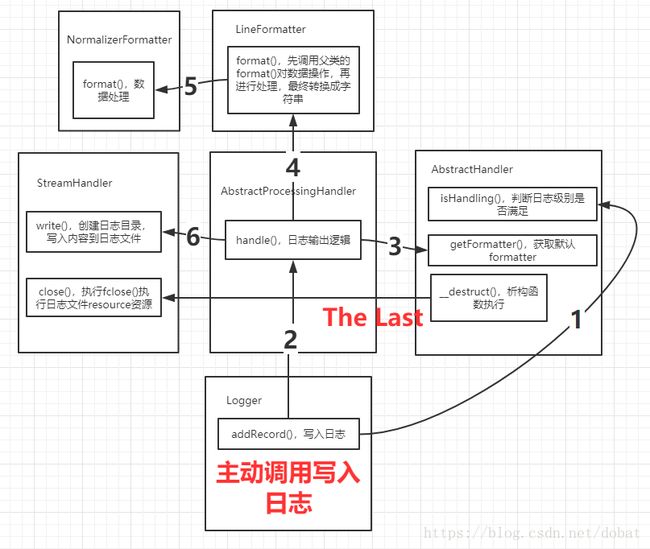
这个图来了解调用日志打印方法,到执行完成的过程,应该还是比较清晰的。
通过结构的层次划分,handler只需要处理write()的实际逻辑来完成日志的导向,close()方法对资源释放。
formatter来专门处理数据的模版格式化。想要实现自己的handler和formatter照着规范耍着来就好。
学习中也发现了几个比较有用处的handler,也许后续会再写写不同的handler和formatter吧~