Python 代码笔记
1、内置函数 lambda
用法一:类函数
格式如下,[]表示可选
[生成器 =] lambda 参数x : 函数体 [实参]
f = (lambda x: x=i)
print(f(1)) # 输出1,这时候类似函数调用用法二:迭代
print map(lambda x: x.startswith('s'), cities['City name']) # 实参部分是一个列表
[False, False, False]用法三:使用 Series.apply。像 Python 映射函数一样,Series.apply 将以参数形式接受 lambda 函数,而该函数会应用于每个值。
# 如果简单的对每个值直接直接的操作,如加减乘除和判断,可以只用一个内置函数方便的完成
if __name__ == '__main__':
cities = pd.DataFrame()
cities['City name'] = ['San', 'New York']
cities['start with San'] = cities['City name'].apply(lambda name:name.startswith('San')
print(cities)
# 输出 :
City name start with San
0 San True
1 New York False# 但是如果要进行分支等间接操作,最好通过lambda函数调用其他函数来完成,逻辑比较清楚
def sel_city(name):
if name.startswith('San'):
return 'Y'
else:
return 'N'
if __name__ == '__main__':
cities = pd.DataFrame()
cities['City name'] = ['San', 'New York']
# cities['start with San'] = cities['City name'].apply(lambda name: name.startswith('San'))
cities['start with San'] = cities['City name'].apply(lambda name: sel_city(name))
print(cities)
# 输出:
City name start with San
0 San Y
1 New York N
2、multiply, dot, *, matmul 和 cross 等各种乘法的区别
multiply 和 *: 对应位元素相乘, 和原来维度一致
cross: 外积, 结果是和原来的分向量都垂直
一维时(向量):
dot 和 matmul : 內积, 结果是数
a = np.ones([3])
b = np.ones([3])
print(a * b)
print(np.multiply(a, b))
print(np.dot(a, b))
print(np.matmul(a, b))
print(np.cross(a, b))
# 输出:
[ 1. 1. 1.]
[ 1. 1. 1.]
3.0
3.0
[ 0. 0. 0.]二维时(矩阵):
dot 和 matmul : 都是矩阵乘法,如 [3,4] x [4,2] = [3,2]
超过二维时:
dot: it is a sum product over the last axis of a and the second-to-last of b,即第一个多维数a的最后一维和第二个多维数b的倒数第二维的乘积的和。也就是在最后两个维度执行矩阵乘法。并且其维度会叠加, 也就是利用了广播机制, 例如可以使用 np.dot(1, b)。
matmul : 前面维度相同且不变,最后两个维度执行矩阵乘法。没有广播机制,不能执行np.dot(1, b)。
a = np.ones([2, 3, 4])
b = np.ones([2, 4, 5])
print("dot : ", np.dot(a, b).shape)
print(np.dot(a, b))
print("matmul : ", np.matmul(a, b).shape)
print(np.matmul(a, b))
# 输出:
dot : (2, 3, 2, 5)
matmul : (2, 3, 5)# matmul 没有广播, 当后面两个维度之前的维度有不相同时,将出错。
a = np.ones([2, 3, 4])
b = np.ones([3, 4, 5])
print("dot : ", np.dot(a, b).shape)
print(np.dot(a, b))
print("matmul : ", np.matmul(a, b).shape)
print(np.matmul(a, b))
# 输出:
dot : (2, 3, 3, 5)
ValueError: operands could not be broadcast together with remapped shapes [original->remapped]: (2,3,4)->(2,3,newaxis,4) (3,4,5)->(3,newaxis,5,4) 总结:
也就是说,使用matmul时只要保持前面的维度不变,在执行
而dot会增加太多维度(如4D * 4D = (4+4-2)D = 6D),不建议使用。为了使得matmul时前面的维度相同,可先使用reshape增加一个维度,然后使用 tf.tile() 在对应维度复制n次。
3、panda 数据处理
import pandas as pd
train_df = pd.read_csv('../input/train.csv') # 读取文件
train_df.head() # 显示前面部分信息
train_df.tail() # 显示末尾部分信息
train_df.describe() # 显示详细(统计)信息
train_df.info() # 显示所有列名及其数据类型显示特征属性和结果的相关性:
train_df[['Pclass','Survived']].groupby(['Pclass'],
as_index=False).mean().sort_values(by='Survived', ascending=False)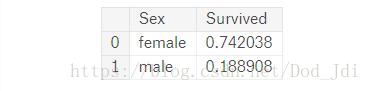
字符串替换
# 多个替换为一个
dataset['Title'] = dataset['Title'].replace(['Lady', 'Countess','Capt',
'Col','Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')
# 一一替换
dataset['Title'] = dataset['Title'].replace('Mlle', 'Miss')
# 或使用Map
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Rare": 5}
dataset['Title'] = dataset['Title'].map(title_mapping)删除和添加列
# 删除
train_df = train_df.drop(['Name', 'PassengerId'], axis=1)
# 添加, 将年龄分为5个级别,小数好像用 pd.qcut
train_df['AgeBand'] = pd.cut(train_df['Age'], 5) 数据填充
# 统计 Pclass、Sex 在 Age 上的分布,作为预测的根据
for dataset in combine:
for i in range(0, 2):
for j in range(0, 3):
# dropna() 不使用无效数据
guess_df = dataset[(dataset['Sex']==i) & (dataset['Pclass']==j+1)]['Age'].dropna()
# 随机填充
# age_mean = guess_df.mean()
# age_std = guess_df.std()
# age_guess = rnd.uniform(age_mean - age_std, age_mean + age_std)
age_guess = guess_df.median()
guess_ages[i,j] = int( age_guess/0.5 + 0.5 ) * 0.5
for i in range(0,2):
for j in range(0,3):
dataset.loc[(dataset.Age.isnull()) & (dataset.Sex == i) & (dataset.Pclass == j+1), 'Age'] = guess_ages[i, j]
dataset['Age'] = dataset['Age'].astype(int)
train_df.head()dropna 和 fillna 中 na 表示 not a number 缺失值
# 中位数填充,使用出现频率最高的数(中位数)补充,
test_df['Fare'].fillna(test_df['Fare'].dropna().median(), inplace=True)
4、seaborn、matplotlib绘图工具
seaborn 在 matplotlib 的基础上进一步封装,更便捷的建立图表
# row,col 表示设立图表的顺序
grid = sns.FacetGrid(train_df, col='Survived', row='Pclass', size=2.2, aspect=1.6)
# plt.hist 直方图, 'Age' 横坐标
grid.map(plt.hist, 'Age', alpha=0.5, bins=20)
grid.add_legend()
散点图:
g = sns.FacetGrid(train_df, col='Embarked', size=2.2, aspect=1.6)
# Pclass 横坐标,Survived 纵坐标, Sex 和 Embarked 构成点的坐标
g.map(sns.pointplot, 'Pclass', 'Survived', 'Sex', palette='deep')
grid.add_legend()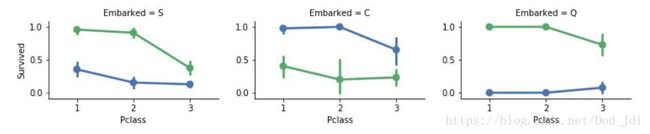
5、关于TensorFlow模块
- tf.nn:nn 是 neural network 缩写,包含了神经网络的相关方法。例如 tf.nn.conv2d 等 卷积(conv)、池化(pooling)、归一化、loss、分类、embedding(词嵌入)、Evaluation等操作。
- tf.layer:好像是在 tf.nn 建立网络模型方法上的封装,可以更方便的建立模型。tf.nn 可能更多在使用预训练模型时使用,其功能更全面。
- tf.contrib:一些contribute(类辅助性、更高级操作、新功能)的方法。例如统计方面和tf.contrib.training.train的使用。一些方法稳定后会移植到 tf.nn 等模块。
更多使用可以参看官方API文档:https://tensorflow.google.cn/api_guides/python/array_ops
Ending:数据分析步骤
工作步骤:
- 问题定义
- 获取训练和测试数据集
- 数据处理,包括删除,填充,修正和新建。
- 数据分析、显示,主要是图表
- 建立模型并进行预测
- 可视化结果进行分析
- 选择最好的方案进行提交
举例:
根据目前初步的情况建立特征和分类结果的关联关系。
初步假设分类:
1. 女生(Sex=female)更可能存活
2. 小孩(Age<?)更可能存活
3. 上层阶级的乘客(Pclass=1)更可能存活
完善一些特征:
* 年龄(Age)很可能与是否存活有关,应该进行补充完善
* 上船的港口(Embarked)可能与存活有关,可以进行补充完善验证
修正一些特征:
* 船票编码(Ticket)可能和结果没有关系,应该可以去除这个特征
* 船舱(Cabin)由于数据丢失太严重,如果补充负面影响可能大于正面,应该去除
* PassengerId 和 Name 特征应该对训练没有作用
创建一些特征:
* 可以综合 Parch 、SibSp 两个特征建立一个亲友关系特征:Family
* 将年龄(Age)划分为各个阶段的新特征(连续到离散)
* 票价(Fare)划分为多个阶段的特征有利于分析
* Name 或许可以提取一些信息(如title头衔?)作为一个新的特征