SparkSQL中的Sort实现(一)
引言
Sort操作也是SQL中常用的操作,一般来说,Sort操作在SQL语句中有两种体现,即Sort by和Order by。这两种的区别是前者是针对分区内排序,而后者是对全表进行一个排序。那有的人问了,全表排序可以理解,那分区排序针对于什么场景呢?通常是在SQL语句中搭配distributed by一起使用,先将表按照某些字段进行分区,然后在分区内进行排序,能够很好的看清分区内的数据分布。
Sort by和Order by
SparkSQL中也不例外,Sort by和Order by这两种语法均支持。而Sort by仅作为分区内排序,是Order by排序过程的一部分。即Order by先针对数据按照字段进行分区,再在每个分区内对数据进行排序(即Order by的操作)。表示成图如下:
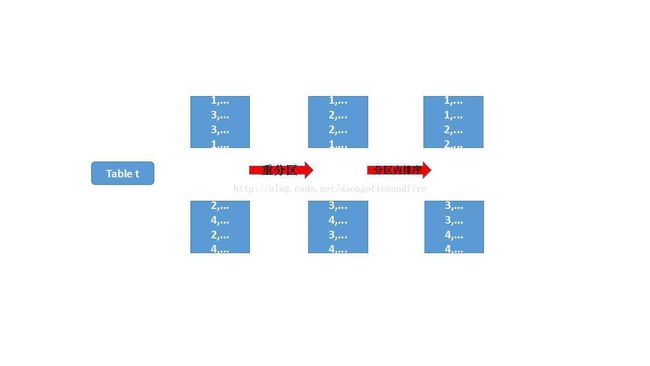
如上图,第一个红色箭头表示按照顺序重分区,保证第n-1个分区内的数据在排序上前于第n个分区内的数据。第二个红色箭头是分区内排序,即对第n个分区,保证第m-1个元素在顺序上早于第m个元素。经过这两个步骤之后,就能保证全表是一个有序的集合了。
而Sort by只进行第二个步骤,即只保证分区内的数据有序。
顺序分区的实现
通常进行shuffle,Partitioner按照hash code决定某个记录属于哪个分区,然后进行写入。按照顺序的分区是怎么实现的呢?如何决定一个分区内包含哪些范围内的数据,又如何将某条记录分配到其对应的分区内呢?我们来看看SparkSQL中是怎么实现的。
前面说过HashParitioner的原理是将记录按照key的hash code进行分区,显然这种场景是不适用的。我们还有另外一种Paritioner:RangePartitoner。RangePartitoner将记录按照key所属的范围进行分区,每个分区都有key按照ordering划分的min、max值,RangePartitoner保证两部分:
1. key值按照ordering计算后值相同的会被分在同一个分区内
2. 每个分区有min、max值,key按照ordering计算后落在min-max范围内的记录会被分在相应的分区
以上两点都比较好理解,但这里有一个关键的问题,每个分区的min、max的值是如何确定的呢?
表内数据采样
显然对于每个表,都有不同的分区字段,而即使分区字段相同,因为表内的数据分布不同,也没有一个统一的标准来对数据进行分区从而确定min、max值。SparkSQL在这里采取了一个比较笨但是靠谱的方法:采样。通过采样概率性采取分区内的数据分布,再根据采样的值确定每个分区的上下限。这个方法虽然不能严格将表中的数据按照size进行分区,却在保证效率的前提下尽量使分区边界保持在一个相对公平的水准。
根据数据的分区分布情况,采样分为两轮:
1. 根据采样大小进行第一轮采样
即对表中的每一个分区,按照sampleSizePerPartiton进行采样,sampleSizePerPartition为3倍的sampleSize/#part,而sampleSize取经验值20*#part和1M的较小值。
这个采样过程较为简单,即对每个分区维护一个sampleSizePerPartition大小的数组,若分区内的记录小于这个数量,则全部采样回去。若大于,则遍历每一个元素,对其和已经遍历过的元素做一个置换,若置换在采样范围内,则更新采样数组内的数据。
此处使用一个map函数实现,遍历过程中会记录分区内的记录数。
2. 对倾斜分区使用采样率做第二轮采样
当某些记录数特别大(大于3*#Items/#part,其中#Items表示表记录总数)的分区,由于粗暴的根据采样大小采样可能会丢失其精确度,将会使用采样率作为条件对其进行第二轮采样,以收集更多的分界样本。
采样率为sampleSize/#Items,即将sampleSize按照表记录总数比例进行放大。
此处首先将识别的倾斜分区作为PartitionPrunedRdd的输入,再使用其sample方法进行采样,具体过程不再赘述。
确定分区上下限
对每个分区采样后,得到采样的记录。但对于每个记录数来说,他们代表的权重是不一样的,因为他们所代表的记录条数不一样(此处有些像美国大选,每个州根据其人数来确定选举人数的票数)。将每个记录所代表的权重记为weight,即分区中的记录数与采样数的比值。
得到每个记录和其代表的权重后,划分分区上下限就比较简单了,如下图:

保证相同的key分在相同分区,且每个分区内的权重大致相等即可。
后记
可以看出,保证分区间有序的操作是通过range partitioner来对表中的记录进行重分区,分区的上下限由两次采样完成后,对采样数据根据权重进行划分来决定。
采样(尤其是二次采样)和权重的结合一定程度上保证了分区上下限基本符合表中数据的基本分布。
分区内排序的过程比较简练:
child.execute().mapPartitionsInternal { iter =>
val sorter = createSorter()
val metrics = TaskContext.get().taskMetrics()
// Remember spill data size of this task before execute this operator so that we can
// figure out how many bytes we spilled for this operator.
val spillSizeBefore = metrics.memoryBytesSpilled
val sortedIterator = sorter.sort(iter.asInstanceOf[Iterator[UnsafeRow]])
sortTime += sorter.getSortTimeNanos / 1000000
peakMemory += sorter.getPeakMemoryUsage
spillSize += metrics.memoryBytesSpilled - spillSizeBefore
metrics.incPeakExecutionMemory(sorter.getPeakMemoryUsage)
sortedIterator
}即使用一个全局的sorter来排序,此处使用的是UnsafeExternalRowSorter,涉及到Spark自身研发的内存管理模块。此处篇幅比较大,暂不做展开,后续再分析。
声明:本文为原创,版权归本人所有,禁止用于任何商业目的,转载请注明出处:http://blog.csdn.net/asongoficeandfire/article/details/53728182
如果你觉得我文章写的不错,可以扫描支付宝二维码打赏我:)
