谈谈Redis
抱着下面这两个问题,我开始读Redis:
1、Redis是单线程的,为什么它的性能不逊于多线程的Memcache?
2、Redis2.8版本不支持集群,而Memcache支持,为什么Redis不借鉴Memcache的方式?
一段对话:
【高级】张文 6:52:56
狗哥,在一台四核的机器上,是不是应该跑四个redis的实例
【高级】张文 6:53:19
来充分利用multi-core
【顶级】小笨狗 7:00:25
不建议
【顶级】小笨狗 7:00:59
redis没有针对多核做优化
【顶级】小笨狗 7:01:30
如果你为每个实例绑定cpu可能还会好点
【顶级】小笨狗 7:02:00
否则没有证明说跑多实例有助于多核利用
【顶级】小笨狗 7:02:21
虽然很多人在多核里跑多实例
【顶级】小笨狗 7:02:54
我认为把鸡蛋放一个篮子里很危险
【高级】张文 7:02:54
可以通过配置为每个实例指定CPU吧
【顶级】小笨狗 7:03:04
可以的
【顶级】小笨狗 7:03:13
绑定cpu
【顶级】小笨狗 7:03:45
为了这一点做多实例我宁愿浪费点cpu
【高级】张文 7:04:52
redis的性能瓶颈在网络而不是cpu
【高级】张文 7:04:58
可以这样理解吗
【顶级】小笨狗 7:05:28
只能说redis不是cpu密集型
【顶级】小笨狗 7:06:05
当你连接多的时候redis一样会飙cpu
【高级】张文 7:07:22
是因为复杂数据结构的操作
【高级】张文 7:10:39
但redis也不是IO密集型吧,虽然redis通过事件循环、IO多路复用来处理并发,但redis由于是单线程的,所以一般会避免阻塞IO
【高级】张文 7:10:57
狗哥,如果我的表述有问题,还请指出啊
【顶级】小笨狗 7:11:57
redis的作者模仿libevent写了一套 所以你无需关心io
【高级】张文 7:14:49
哦
【高级】张文 7:20:15
狗哥,我始终觉得redis这种单线程的方式相当于事务里的序列化隔离级别,所以可以进行优化:1,锁分离,如果两个文件事件所处理的数据没有冲突,则可以并行;2读写锁,将读锁和写锁分离,做读读并行
【高级】张文 7:20:20
基于多线程
【高级】张文 7:20:33
不知道可行不
【顶级】小笨狗 7:22:16
这个看你业务
【顶级】小笨狗 7:22:53
单线程不是锁
【高级】张文 7:26:16
恩,单线程不是锁,redis里的单线程是通过将所有产生事件的套接字都放到一个队列里面
【高级】张文 7:26:25
有序的处理
【高级】张文 7:27:02
上一个事件被处理完之后,才会处理下一个
【顶级】小笨狗 7:27:30
但你的业务却不是这样的
【顶级】小笨狗 7:27:44
这是redis保证自己的数据处理
【高级】张文 7:32:00
那redis试用的业务场景是
【高级】张文) 7:32:08
适用
【初级】hektor 7:32:47
有序事件那都是redis自带的原子操作方法 并不能保证一个客户端的事务能串行
另外,多线程虽然可以利用多核,提高并行度,但多线程意味着更复杂的代码、上下文切换、同步阻塞等
第二个问题
Memcache被称为分布式缓存服务器,但服务端并没有提供分布式功能,其分布式主要体现在客户端,对于Server端,仅仅是部署多个Memcache Server组成的集群,每个Server独立维护自己的数据,节点相互之间没有任何通信。Memcache的分布式是在客户端通过一致性哈希算法实现的,即将要存储的数据分布到某个特定的Server上存储,后续读取查询使用同样的Hash算法即可定位。
在分布式集群中,对机器的添加、删除或者机器故障后自动脱离集群这些操作是分布式集群管理最基本的功能。
最简单的Hash算法:targetServer=serverList[hash(key)%serverList.size]。算法简单,而且具有不错的随机分布特性。但问题也很明显,Server的总数不能轻易变化。因为如果增加/减少Server的数量,对原先存储的所有Key的后续查询都将定位到别的Server上,导致大部分Cache都不能被命中而失效。
一致性哈希算法解决了这个问题。相对于对Server总数取模的算法,一致性Hash算法除了计算Key的Hash值外,还会计算每个Server对应的Hash值,然后将这些Hash值映射到有限的值域上,0~(2^32)-1。通过寻找Hash值大于Hash(key)的最小Server作为存储该Key的目标Server。如果找不到,则直接把具有最小Hash值的Server作为目标Server。
但是当Server数量很少的时候,很可能他们在环中的分布不是特别均匀,进而导致Cache不能均匀分布到所有的Server上。
这时就需要引入虚拟节点(virtual node),一个物理节点对应多个虚拟节点,可以根据每个物理Server的负载能力,赋予不同的权重,根据权重为物理Server分配不同数量的虚拟节点。当为Cache定位目标Server时,如果定位到虚拟节点上,就表示Cache真正的存储位置是在该虚拟节点代表的物理Server上。
虚拟节点的Hash计算可以采用对应物理节点IP地址加数字后缀的方式。如,Node1的IP为192.168.0.1,Node1的Hash值是Hash(”192.168.0.1”)。Node1的虚拟节点Node1-1,Node1-2的Hash值是Hash(“192.168.0.1#1”),Hash(“192.168.0.1#2”)。
恩,很不错的算法 ^V^
而在Redis2.8中,提供Sentinel作为Redis的HA解决方案:由一个或多个Sentinel实例组成的Sentinel系统可以监视任意多个主服务器,以及这些主服务器下的所有从服务器,并在被监视的主服务器进入下线状态时,自动将下线主服务器属下的某个从服务器升级为新的主服务器,然后由新的主服务器继续处理命令请求。
之前我使用KeepAlived,做Redis的Master-Slave,主备之间切换,需要通过自己写shell脚本来控制,其间我还因为shell脚本严格的格式要求而栽过坑,调试了许久…
Sentinel本质上是一个运行在特殊模式下的Redis服务器。
就我个人而言,不喜欢这种实现方式。Sentinel作为一个Observer,为了避免单点问题,就需要多个Sentinel,这时就需要选出领头羊Sentinel…系统的复杂性大大增加。
在Redis3.0 Realease版中提供了集群方案:通过分片(sharding)的方式来保存集群中的键值对,集群的整个数据库被分为16384个槽(slot),数据库中的每个键会映射到这16384个槽中,集群中的每个节点负责处理被指派的槽,可以处理0个或最多16384个槽。集群中的每个节点都是平等的,没有中心,没有代理。每个节点通过gossip协议相互通讯掌握其他节点的健康状况和数据信息。
客户端直接访问集群节点。如果客户端请求的Key所在的槽正好被指派给了当前节点,那么当前节点直接执行这个命令;如果Key所在的槽并没有被指派给当前节点,那么会路由(redirect)到Key所在的节点进行处理。
节点和单机数据库的一个区别是,节点只能使用0号数据库,而单机Redis服务器则没有这一限制。
Redis集群的重新分片操作可以将任意数量已经指派给某个节点的槽改为指派给另外一个节点,并且相关槽所属的键值对也会从源节点移动到目标节点。重新分片操作可以在线进行,并且源节点和目标节点都可以继续处理命令请求。
Redis集群中的节点分为主节点(master)和从节点(slave),主节点用于处理槽,从节点复制主节点,在主节点下线时,代替主节点继续处理命令请求。
Redis的几个实现特点:
1、Redis有五种数据类型:字符串对象、列表对象(list)、哈希对象(hash)、集合对象(set)、有序集合对象(sortedSet)。六种内部数据结构:简单动态字符串(SDS)、list、字典(dict)、跳跃表(skiplist)、整数集合(intset)、压缩列表(ziplist)。
Redis没有直接使用C语言传统的字符串表示(以空字符结尾的字符数组),而是自己构建了一种名为简单动态字符串(SDS)的抽象类型。
sds.h/sdshdr:
struct sdshdr {
//记录buf数组中已使用字节的数量
//等于SDS所保存字符串的长度
int len;
//记录buf数组中未使用的字节数量
int free;
//字节数组,用于保存字符串
char buf[];
}
这样做的原因:
1.遵循空字符结尾这一惯例的好处是,SDS可以直接重用一部分C字符串函数库里面的函数。
2.将获取字符串长度的复杂度从O(N)降低到了O(1)
3.杜绝缓冲区溢出
4.通过空间预分配和惰性空间释放,减少修改字符串时带来的内存重分配次数
5.使用二进制安全的SDS,使得redis不仅可以保存文本数据,还可以保存任意格式的二进制数据。因为SDS是使用len属性的值而不是空字符来判断字符串是否结束的。
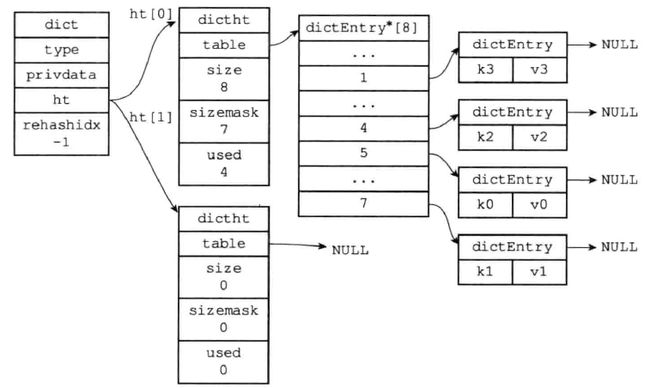
Redis的字典使用哈希表作为底层实现。
dict.h/dictht:
typedef struct dictht {
//哈希表数组
dictEntry **table;
//哈希表大小
unsigned long size;
//哈希表大小掩码,用于计算索引值
//总是等于size-1
unsigned long sizemask;
//该哈希表已有节点的数量
unsigned long used;
}dictht;
typedef struct dictEntry{
void *key;
union{
void *val;
uint64_tu64;
int64_ts64;
}v;
struct dictEntry *next;
}dictEntry;
typedef struct dict {
dictType *type;
void *privdata;
//字典只使用ht[0]哈希表,ht[1]只会在对ht[0]rehash时使用
dictht ht[2];
//记录rehash目前的进度
//当rehash不在进行时,值为-1
int trehashidx;
}一个普通状态下的字典:

Redis对字典的哈希表执行rehash的步骤如下:
1.为字典的ht[1]哈希表分配空间:如果执行的是扩展操作,那么ht[1]的大小为第一个大于等于ht[0].used*2的2的n次幂;如果是收缩操作,ht[1]为第一个大于等于ht[0].used的2的n次幂。
2.将保存在ht[0]中的所有键值对rehash到ht[1]上
3.释放掉ht[0],将ht[1]设置为ht[0],并在ht[1]新创建一个空白哈希表,为下一次rehash做准备。
例子,程序要对下面所示字典的ht[0]进行扩展操作:

ht[0].used=4,4*2=8,为字典的ht[1]哈希表分配空间:

将ht[0]包含的四个键值对都rehash到ht[1]:

释放ht[0],并将ht[1]设置为ht[0],然后为ht[1]分配一个空白哈希表:
**这个rehash动作并不是一次性、集中式的完成的,而是分多次、渐进式的完成的。即将rehash的工作分摊到对字典的每个添加、删除、查找和更新操作上,对于新添加的键值对一律保存到ht[1]里面。
redis的对象系统的内存回收机制是基于引用计数,另外redis还通过引用计数实现了对象共享机制,通过让多个数据库键共享一个对象来节约内存。但Redis只对包含整数值(0-9999)的字符串对象进行共享。因为共享对象越复杂,验证共享对象和目标对象是否相同所需的复杂度就会越高,消耗的CPU时间也越多。如果共享对象是保存整数值的字符串对象,那么验证操作是O(1),字符串值O(n)。
Redis为什么不使用Libevent或者Libev?
redis的作者Salvatore给出的答案是:
代码要足够简洁,能够满足当前的需求即可,尽量不要引入外部的依赖。
Salvatore:
Redis使用一个简洁的事件循环(event
loop),我能够完全控制它。Libevent库自身的代码量已经是Redis目前代码量的3倍大了。
Sergey Shepelev:
Year,Libevent比较差劲,相反,libev是一个小巧、well
thought、clean的库,它并没有提供任何高级的feature,比如http,但是它确实提供了非常好的底层feature。
Salvatore:
我认为从软件工程的观点来看你是正确的,通过重用一个已经很好测试过的库,Redis的事件循环出现bug的概率会小很多。
许多库在理论上被很好的测试过了,但如果通过一种和使用它的前N个项目不同的方式来使用它,还是会发现bug的。例如,Redis唯一使用的外部代码:LZF压缩已经存在很多年了。在使用它一些天后,我发现了一个内存崩溃的bug。几乎所有人都在使用它,它也被很好的测试过,但是bug仍然存在。
而且当我需要修改代码时,我能够自己实现而不用等待外部的开发者来合并我的修改。
我讨厌./configure。我对现在redis的zero-configuration的体验非常满意。
redis-3.0.1,ae.c源码:
/* Include the best multiplexing layer supported by this system.
* The following should be ordered by performances, descending. */
#ifdef HAVE_EVPORT
#include "ae_evport.c"
#else
#ifdef HAVE_EPOLL
#include "ae_epoll.c"
#else
#ifdef HAVE_KQUEUE
#include "ae_kqueue.c"
#else
#include "ae_select.c"
#endif
#endif
#endifevport(Event ports),Solaris 10新增加的类库
select/poll/epoll,linux
kqueue,FreeBSD