netty write 和flush 源码解析
本文参考:https://www.jianshu.com/p/1ad424c53e80
概要
netty中每次write之后都需要flush才能将消息发送出去,代码如下。
笔者很好奇为什么一定要分成write和flush两个方法——既然每次都需要调用flush,直接由框架自动去调用flush不就好了吗?
于是就去看了源码,写此文记之。
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
ByteBuf buf1 = ctx.alloc().buffer(4);
buf1.writeInt(1);
ByteBuf buf2 = ctx.alloc().buffer(4);
buf2.writeInt(2);
ByteBuf buf3 = ctx.alloc().buffer(4);
buf3.writeInt(3);
ctx.write(buf1);
ctx.write(buf2);
ctx.write(buf3);
ctx.flush();
}
write和flush
两者作用概括如下:
write
将需要写的ByteBuff存储到ChannelOutboundBuffer中。
flush
从ChannelOutboundBuffer中将需要发送的数据读出来通过Channel发送出去。
ChannelOutboundBuffer
既然两者作用都和ChannelOutboundBuffer相关,那么就先看下ChannelOutboundBuffer是什么。
ChannelOutboundBuffer中的数据结构不多,最主要的就是两个数组——flushed和unflushed。这两个数组中会存储需要传输的ByteBuff。
// Flushed messages are stored in a circular buffer.
private Object[] flushed;
private ChannelPromise[] flushedPromises;
private int[] flushedPendingSizes;
private long[] flushedProgresses;
private long[] flushedTotals;
// Unflushed messages are stored in an array list.
private Object[] unflushed;
private ChannelPromise[] unflushedPromises;
private int[] unflushedPendingSizes;
private long[] unflushedTotals;
private int unflushedCount;
为什么维护两个数组,而不是直接用一个搞定?
ChannelOutboundBuffer不是一个线程安全的数据结构,可能会有同时多个线程执行write操作。
flush是去ChannelOutboundBuffer中取内容,而write是在ChannelOutboundBuffer中写内容,高并发情况下会有很多难以预料的问题。
既然如此,那为什么不用“锁”去保证ChannelOutboundBuffer的数据安全呢?
write和flush在网络中都是很频繁的操作,如果用“锁”会大大降低性能。
write源码
write的调用方法栈如下,最终会走到AbstractChannel的write方法中。
(ProtocolOutHandler是笔者demo 的ChannelOutboundHandlerAdapter)
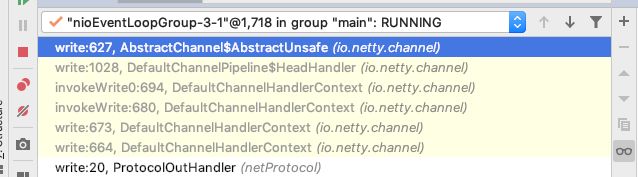
AbstractChannel的write源码如下,最终会调用到ChannelOutboundBuffer的addMessage方法。
public void write(Object msg, ChannelPromise promise) {
if (!isActive()) {
// Mark the write request as failure if the channel is inactive.
if (isOpen()) {
promise.tryFailure(NOT_YET_CONNECTED_EXCEPTION);
} else {
promise.tryFailure(CLOSED_CHANNEL_EXCEPTION);
}
// release message now to prevent resource-leak
ReferenceCountUtil.release(msg);
} else {
outboundBuffer.addMessage(msg, promise);
}
}
ChannelOutboundBuffer的addMessage方法如下。
源码中的逻辑就是将write的内容存储到unflushed这个数组中。
至此,我们发现write逻辑非常简单,就是把需要ByteBuff存储到ChannelOutboundBuffer的unflushed数组中。
void addMessage(Object msg, ChannelPromise promise) {
Object[] unflushed = this.unflushed;
int unflushedCount = this.unflushedCount;
if (unflushedCount == unflushed.length - 1) {
doubleUnflushedCapacity();
unflushed = this.unflushed;
}
final int size = channel.calculateMessageSize(msg);
unflushed[unflushedCount] = msg;
unflushedPendingSizes[unflushedCount] = size;
unflushedPromises[unflushedCount] = promise;
unflushedTotals[unflushedCount] = total(msg);
this.unflushedCount = unflushedCount + 1;
// increment pending bytes after adding message to the unflushed arrays.
// See https://github.com/netty/netty/issues/1619
incrementPendingOutboundBytes(size);
}
flush源码
flush的主要逻辑会多一些,在此先说结果,有兴趣的读者可以自己走下源码的流程。
flush主要做了两件事:
- 调用ChannelOutboundBuffer的addFlush方法,将unflushed中的内容交换到flushed数组中。
- 将ChannelOutboundBuffer的flushed数组中的内容通过Channel传输出去。
首先定位到AbstractChannel的flush方法,方法调用栈和源码如下。
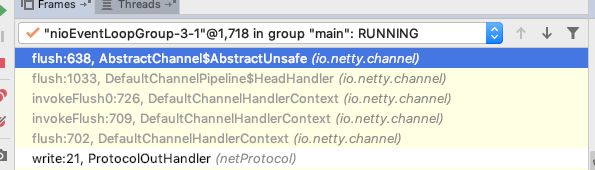
public void flush() {
ChannelOutboundBuffer outboundBuffer = this.outboundBuffer;
if (outboundBuffer == null) {
return;
}
outboundBuffer.addFlush();
flush0();
}
可以在这里看到ChannelOutboundBuffer的addFlush方法,该方法源码如下:
void addFlush() {
final int unflushedCount = this.unflushedCount;
if (unflushedCount == 0) {
return;
}
Object[] unflushed = this.unflushed;
ChannelPromise[] unflushedPromises = this.unflushedPromises;
int[] unflushedPendingSizes = this.unflushedPendingSizes;
long[] unflushedTotals = this.unflushedTotals;
Object[] flushed = this.flushed;
ChannelPromise[] flushedPromises = this.flushedPromises;
int[] flushedPendingSizes = this.flushedPendingSizes;
long[] flushedProgresses = this.flushedProgresses;
long[] flushedTotals = this.flushedTotals;
int head = this.head;
int tail = this.tail;
for (int i = 0; i < unflushedCount; i ++) {
flushed[tail] = unflushed[i];
unflushed[i] = null;
flushedPromises[tail] = unflushedPromises[i];
unflushedPromises[i] = null;
flushedPendingSizes[tail] = unflushedPendingSizes[i];
flushedProgresses[tail] = 0;
flushedTotals[tail] = unflushedTotals[i];
if ((tail = (tail + 1) & (flushed.length - 1)) == head) {
this.tail = tail;
doubleFlushedCapacity();
head = this.head;
tail = this.tail;
flushed = this.flushed;
flushedPromises = this.flushedPromises;
flushedPendingSizes = this.flushedPendingSizes;
flushedProgresses = this.flushedProgresses;
flushedTotals = this.flushedTotals;
}
}
this.unflushedCount = 0;
this.tail = tail;
}
addFlush源码逻辑很简单,就是将unflushed中的内容放到flushed中。
我们再看另一个关键方法,flush0()的源码:
protected void flush0() {
if (inFlush0) {
// Avoid re-entrance
return;
}
final ChannelOutboundBuffer outboundBuffer = this.outboundBuffer;
if (outboundBuffer == null || outboundBuffer.isEmpty()) {
return;
}
inFlush0 = true;
// Mark all pending write requests as failure if the channel is inactive.
if (!isActive()) {
try {
if (isOpen()) {
outboundBuffer.failFlushed(NOT_YET_CONNECTED_EXCEPTION);
} else {
outboundBuffer.failFlushed(CLOSED_CHANNEL_EXCEPTION);
}
} finally {
inFlush0 = false;
}
return;
}
try {
doWrite(outboundBuffer);
} catch (Throwable t) {
outboundBuffer.failFlushed(t);
if (t instanceof IOException) {
close(voidPromise());
}
} finally {
inFlush0 = false;
}
}
大部分代码是安全性判断和处理,主要逻辑就是doWrite()这个方法:
笔者的demo是用的NioSocketChannel。因此,这里我们会直接走到NioSocketChannel的源码中,此时的方法调用栈和源码如下:
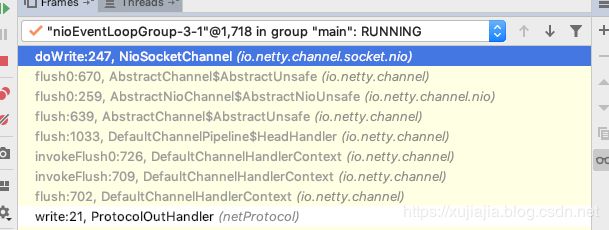
protected void doWrite(ChannelOutboundBuffer in) throws Exception {
// Do non-gathering write for a single buffer case.
final int msgCount = in.size();
if (msgCount <= 1) {
super.doWrite(in);
return;
}
// Ensure the pending writes are made of ByteBufs only.
ByteBuffer[] nioBuffers = in.nioBuffers();
if (nioBuffers == null) {
super.doWrite(in);
return;
}
int nioBufferCnt = in.nioBufferCount();
long expectedWrittenBytes = in.nioBufferSize();
final SocketChannel ch = javaChannel();
long writtenBytes = 0;
boolean done = false;
for (int i = config().getWriteSpinCount() - 1; i >= 0; i --) {
final long localWrittenBytes = ch.write(nioBuffers, 0, nioBufferCnt);
updateOpWrite(expectedWrittenBytes, localWrittenBytes, i == 0);
if (localWrittenBytes == 0) {
break;
}
expectedWrittenBytes -= localWrittenBytes;
writtenBytes += localWrittenBytes;
if (expectedWrittenBytes == 0) {
done = true;
break;
}
}
if (done) {
// Release all buffers
for (int i = msgCount; i > 0; i --) {
in.remove();
}
} else {
// Did not write all buffers completely.
// Release the fully written buffers and update the indexes of the partially written buffer.
for (int i = msgCount; i > 0; i --) {
final ByteBuf buf = (ByteBuf) in.current();
final int readerIndex = buf.readerIndex();
final int readableBytes = buf.writerIndex() - readerIndex;
if (readableBytes < writtenBytes) {
in.remove();
writtenBytes -= readableBytes;
} else if (readableBytes > writtenBytes) {
buf.readerIndex(readerIndex + (int) writtenBytes);
in.progress(writtenBytes);
break;
} else { // readable == writtenBytes
in.remove();
break;
}
}
}
}
这里由于代码逻辑太多,我们就把最关键的一部分拿出来解析,读者对其他逻辑感兴趣的可以自行查看下:
// Ensure the pending writes are made of ByteBufs only.
ByteBuffer[] nioBuffers = in.nioBuffers();
if (nioBuffers == null) {
super.doWrite(in);
return;
}
int nioBufferCnt = in.nioBufferCount();
long expectedWrittenBytes = in.nioBufferSize();
final SocketChannel ch = javaChannel();
long writtenBytes = 0;
boolean done = false;
for (int i = config().getWriteSpinCount() - 1; i >= 0; i --) {
final long localWrittenBytes = ch.write(nioBuffers, 0, nioBufferCnt);
updateOpWrite(expectedWrittenBytes, localWrittenBytes, i == 0);
if (localWrittenBytes == 0) {
break;
}
expectedWrittenBytes -= localWrittenBytes;
writtenBytes += localWrittenBytes;
if (expectedWrittenBytes == 0) {
done = true;
break;
}
}
这里主要的过程如下:
1、通过ChannelOutboundBuffer的nioBuffers方法,将flush中的数据读出来。
2、用一个for循环将数据写到Channel中(这里for循环的这种操作,我们一般称之为自旋)
将数据写到Channel中这个操作为什么要用自旋?
笔者认为这里应该是考虑到,将数据写到Channel中可能会因为网络阻塞等原因导致写失败。
但是由于netty中I/O在同一个或者几个线程中处理,是不能长时间阻塞线程的,否则会影响其他数据的处理。(很可能就一个Channel的网络阻塞了,但是其他Channel正常,正常逻辑就是应该抛弃这个消息,其他消息正常处理。)
此处使用自旋锁能在短时间内马上处理完这种异常情况。