angr源码分析——cle.Loader类
上篇文章分析angr.Project类时说到,angr工具第一步就是将二进制文件加载到cle.loader类里。(CLE means Loading Everything)。loader类加载所有的对象并导出一个进程内存的抽象。生成该程序已加载和准备运行的地址空间。
构造函数参数:
cle.loader.Loader(main_binary, auto_load_libs=True, force_load_libs=(), skip_libs=(), main_opts=None, lib_opts=None, custom_ld_path=(), use_system_libs=True, ignore_import_version_numbers=True, case_insensitive=False, rebase_granularity=16777216, except_missing_libs=False, aslr=False, page_size=1, extern_size=32768)
:param main_binary: 要加载主要二进制文件的路径,或者一个带有二进制文件的对象。
以下参数是可选的.
:param auto_load_libs: 是否自动加载已加载对象所依赖的共享库.
:param force_load_libs: 无论加载对象是否需要,都加载的库列表.
:param skip_libs: 即使加载对象需要也不会加载的库列表.
:param main_opts: 一个字典,加载主二进制文件的选项.
:param lib_opts: 一个字典,将库名称映射到加载它们时要使用的选项字典.
:param custom_ld_path: 用于搜索共享库的路径列表.
:param use_system_libs: 是否搜索所请求库的系统加载路径,默认为true.
:param ignore_import_version_numbers: 文件名中具有不同版本号的库是否被认为是等效的,例如libc.so.6和libc.so.0。
:param case_insensitive: 如果将其设置为True,则无论底层文件系统的区分大小写如何,文件系统加载都将以不区分大小写的方式进行。
:param rebase_granularity: 用于重新分配共享对象的对齐方式。
:param except_missing_libs: 当找不到共享库时抛出异常.
:param aslr: 在符号地址空间中加载库。 不要使用这个选项(???)。
:param page_size: 数据映射到内存的粒度。 如果您在非分页环境中工作,请将其设置为1。
一些变量解释:
:ivar memory: 程序加载,重定位的内存。
:vartype memory: 类型为cle.memory.Clemory类
:ivar main_object: 代表了主要的二进制文件对象
:ivar shared_objects: 一个字典,映射了名名称和它们代表的对象.
:ivar all_objects: 一个列表,代表了所有被加载的不同对象.
:ivar requested_names: 一个集合,包含了所有没标记为某个部分的依赖的不同的共享库.
:ivar initial_load_objects: 一个列表,代表所有初始加载请求结果的所有对象.
当引用字典选项时,它需要一个包含零个或多个以下key的字典:
- backend(后端):“elf”,“pe”,“mach-o”,“ida”,“blob”:后端使用的加载器
- custom_arch:用于二进制文件的archinfo.Arch对象
- custom_base_addr:重新绑定对象的地址
- custom_entry_point:用于对象的入口点
更多的key在每个后端的基础上定义。
执行流程:
第一步:参数初始化。在构造函数中,主要就是初始化各个参数,这部分在后面有些参数需要格外关注时可以再仔细分析。
第二步:加载对象初始化。构造函数的最后一行代码为
self.initial_load_objects = self._internal_load(main_binary, *force_load_libs)
这里调用了函数_internal_load(),跟进去看对象初始化的逻辑。
这个函数的参数为传入要加载的文件或库。如果由于任何原因无法加载其中的任何一个,则会退出。
它将返回一个成功加载的所有对象的列表,如果其中它们任何被加载过,那么返回的列表会比你提供的列表小。
下面这段函数看一下:
for main_spec in args:
if self.find_object(main_spec, extra_objects=objects) is not None:
l.info("Skipping load request %s - already loaded", main_spec)
continue
l.info("loading %s...", main_spec)
main_obj = self._load_object_isolated(main_spec)
objects.append(main_obj)
dependencies.extend(main_obj.deps)
if self.main_object is None:
self.main_object = main_obj
self.memory = Clemory(self.main_object.arch, root=True)main_spec 就是传入的二进制文件或库。循环中,先判断的是这个对象是否加载过,若加载过则不再加载。加载一个文件时调用的函数为 _load_object_isolated()。这个函数给定一个依赖的部分说明,它将会把加载对象作为一个后端实例返回。它不会触及任何加载器全局数据。再跟进这个函数看下。
# STEP 1: identify file
if isinstance(spec, Backend):
return spec
elif hasattr(spec, 'read') and hasattr(spec, 'seek'):
full_spec = spec
elif type(spec) in (bytes, unicode):
full_spec = self._search_load_path(spec) # this is allowed to cheat and do partial static loading
l.debug("... using full path %s", full_spec)
else:
raise CLEError("Bad library specification: %s" % spec)
# STEP 2: collect options
if self.main_object is None:
options = self._main_opts
else:
for ident in self._possible_idents(full_spec): # also allowed to cheat
if ident in self._lib_opts:
options = self._lib_opts[ident]
break
else:
options = {}
# STEP 3: identify backend
backend_spec = options.pop('backend', None)
backend_cls = self._backend_resolver(backend_spec)
if backend_cls is None:
backend_cls = self._static_backend(full_spec)
if backend_cls is None:
raise CLECompatibilityError("Unable to find a loader backend for %s. Perhaps try the 'blob' loader?" % spec)
# STEP 4: LOAD!
l.debug("... loading with %s", backend_cls)
return backend_cls(full_spec, is_main_bin=self.main_object is None, loader=self, **options) #它就是main_oject 调用的是backend的init函数第二步:收集选项options。在这一步,调用了_possible_idents()函数,对刚刚获得full_spec进行识别,它遍历所有可能用于描述给定spec的识别符。
第三步:识别后端。首先从options中获取backend,并初始化一个backend_cls变量,如果该变量为空,则调用_static_backend()函数获取backend_cls实例。
也就是说,真正对二进制文件识别的函数为_static_backend(),再次跟进看其逻辑。
def _static_backend(self, spec):
"""
Returns the correct loader for the file at `spec`.
Returns None if it's a blob or some unknown type.
TODO: Implement some binwalk-like thing to carve up blobs automatically
"""
try:
return self._backend_resolver(self._lib_opts[spec]['backend'])
except KeyError:
pass
with stream_or_path(spec) as stream:
for rear in ALL_BACKENDS.values():
if rear.is_default and rear.is_compatible(stream):
return rear
return None该函数根据spec返回二进制文件的正确加载器。如果是blob或者其他未知类型则返回none。其中代码中允许我们实现能够识别和分割blob类型二进制文件的代码。(这个重点哎!)
识别后端利用的是特征匹配吧,首先加载刚刚遍历提取得到的spec,然后与ALL_BACKENDS的值进行匹配,及rear变量,调用rear.is_compatible()函数。所以我们要去看一下ALL_BACKENDS都是些什么,is_compatible()函数的匹配逻辑。而且我们的目标是要解决我们想返回自己定制的rear变量时,这个变量是什么样的。
全局搜索ALL_BACKENDS,发现其出现在如下位置:
cle/cle/backends/__init__.py(初始化)
angr/cle – loader.py (调用)
ALL_BACKENDS初始化位置在backend类里面,该类是二进制对象的基类。ALL_BACKENDS初始化代码为:
ALL_BACKENDS = dict()
def register_backend(name, cls):
if not hasattr(cls, 'is_compatible'):
raise TypeError("Backend needs an is_compatible() method")
ALL_BACKENDS.update({name: cls})可以看出ALL_BACKENDS是一个字典类型,在函数register_backend(name, cls)中会更新这个字典,向里面添加新的name和cls。全局搜索哪里调用了register_backend(name, cls)函数,发现调用的位置如下(10处):
cle/backends/cgc/cgc.py register_backend('cgc', CGC)
cle/backends/blob.py register_backend("blob", Blob)
cle/backends/cgc/backedcgc.py register_backend('backedcgc', BackedCGC)
cle/backends/elf/elfcore.py register_backend('elfcore', ELFCore)
cle/backends/ihex.py register_backend("hex", Hex)
cle/backends/soot.py register_backend('soot', Soot)
cle/backends/pe/pe.py register_backend('pe', PE)
cle/backends/idabin.py register_backend("idabin", IDABin)
cle/backends/macho/macho.py register_backend('mach-o', MachO)
cle/backends/elf/elf.py register_backend('elf', ELF)
我们随便选择一个文件类型进去看一下,register_backend(name, cls)中cls究竟是什么。这里先选择pe文件格式类型。
那跟进去发现其实cls就是后端中的类,pe中的PE就是PE类: class PE;ELF就是ELF类,class ELF。。
而且每个cls都要有一个is_compatible(stream)函数,这个函数就是用来匹配传入二进制文件特征的了。下面是PE文件格式的匹配逻辑:
@staticmethod
def is_compatible(stream):
identstring = stream.read(0x1000)
stream.seek(0)
if identstring.startswith('MZ') and len(identstring) > 0x40:
peptr = struct.unpack('I', identstring[0x3c:0x40])[0]
if peptr < len(identstring) and identstring[peptr:peptr + 4] == 'PE\0\0':
return True
return False首先读取0x1000字节,判断是否以MZ开头,并且长度大于0x40字节;如果是,那么提取出indentstring中0x3c到0x40字节的数据,并转换为无符号整数类型,如果peptr小于identstring的长度,并且indentstring中peptr位置起始的四个字节为‘PE\0\0’,则可以判断出这个一个PE文件,返回true。为了证实逻辑的准确性,我们以一个test.exe文件为例,使用winhex打开该文件。
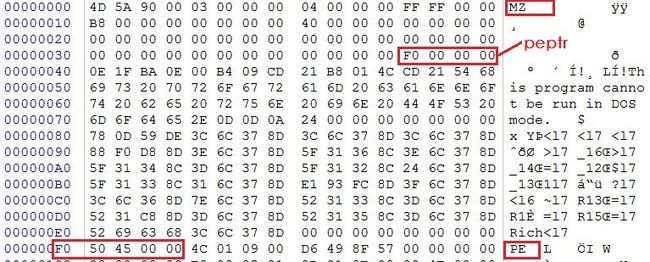
首先文件以‘MZ’开头,并且文件大于0x40。然后peptr为:F0。而F0--F4的字符确实是'PE\0\0',判断结束。
所以,我们可以自定义文件类型判断,或者针对blob文件根据自己的总结特征进行自定义处理判断。目前,主要方法为:在backends中声明一个类,并实现一个is_compatible(stream)函数和register_backend(name, cls)函数(这两个是主要的,当然其他的方法需要再次深入backend里面的类进行分析)。其他需要注意的地方以后遇到再进行讨论。
下一步搞清楚,在识别出backend后,这段程序又是如何到内存中,并且模拟执行的呢?
这段代码在_internal_load函数中。
def _internal_load(self, *args):
objects = []
dependencies = []
cached_failures = set() # this assumes that the load path is global and immutable by the time we enter this func
for main_spec in args:
if self.find_object(main_spec, extra_objects=objects) is not None:
l.info("Skipping load request %s - already loaded", main_spec)
continue
l.info("loading %s...", main_spec)
main_obj = self._load_object_isolated(main_spec)
objects.append(main_obj)
dependencies.extend(main_obj.deps)
if self.main_object is None:
self.main_object = main_obj #这个main_object就是backend实例
self.memory = Clemory(self.main_object.arch, root=True) #初始化内存空间
while self._auto_load_libs and dependencies:
dep_spec = dependencies.pop(0)
if dep_spec in cached_failures:
l.debug("Skipping implicit dependency %s - cached failure", dep_spec)
continue
if self.find_object(dep_spec, extra_objects=objects) is not None:
l.debug("Skipping implicit dependency %s - already loaded", dep_spec)
continue
try:
l.info("Loading %s...", dep_spec)
dep_obj = self._load_object_isolated(dep_spec)
except CLEFileNotFoundError:
l.info("... not found")
cached_failures.add(dep_spec)
if self._except_missing_libs:
raise
else:
continue
objects.append(dep_obj) #所有的加载对象
dependencies.extend(dep_obj.deps)
for obj in objects:
self._register_object(obj) #注册对象
for obj in objects:
self._map_object(obj) #将对象集成到地址空间
for obj in objects:
if isinstance(obj, (MetaELF, PE)) and obj.tls_used:
self.tls_object.register_object(obj)
for obj in objects:
self._relocate_object(obj) #重定位加载对象
for obj in objects:
if isinstance(obj, (MetaELF, PE)) and obj.tls_used:
self.tls_object.map_object(obj)
return objects在调用_load_object_isolated函数获得了加载对象对应的backend实例后,初始化与架构有关的内存空间memory。为了更好理解加载过程,先对Clemory对象进行简单介绍。Clemory代表了一个内存空间,使用“backers”和“updates”分别表示加载和写入内存,使查找更加高效。通过使用索引进行访问。该对象中常用的方法为:
add_backer(start, data)
start - backer的加载地址
data - backer本身。可以是一个字符串也可以是一个Clemory。
其中将对象加载到地址空间的函数为_map_object(),它的代码如下:
def _map_object(self, obj):
"""
This will integrate the object into the global address space, but will not perform relocations.
"""
obj_size = obj.max_addr - obj.min_addr
if obj.pic:
if obj._custom_base_addr is not None and self._is_range_free(obj._custom_base_addr, obj_size):
base_addr = obj._custom_base_addr
elif obj.linked_base and self._is_range_free(obj.linked_base, obj_size):
base_addr = obj.linked_base
elif not obj.is_main_bin:
base_addr = self._find_safe_rebase_addr(obj_size)
else:
l.warning("The main binary is a position-independent executable. "
"It is being loaded with a base address of 0x400000.")
base_addr = 0x400000
obj.mapped_base = base_addr
obj.rebase()
else:
base_addr = obj.linked_base
if not self._is_range_free(obj.linked_base, obj_size):
raise CLEError("Position-DEPENDENT object %s cannot be loaded at %#x"% (obj.binary, base_addr))
assert obj.min_addr < obj.max_addr
assert obj.mapped_base >= 0
if obj.has_memory:
l.info("Mapping %s at %#x", obj.binary, base_addr)
self.memory.add_backer(base_addr, obj.memory)
key_bisect_insort_left(self.all_objects, obj, keyfunc=lambda o: o.min_addr)
obj._is_mapped = True