【读书笔记】美团机器学习实践-5.2 用户画像数据挖掘
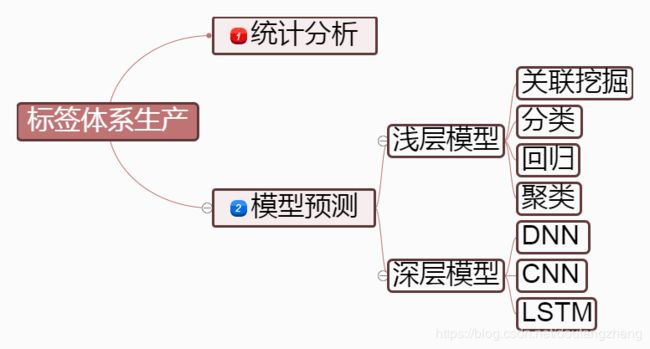
标签体系生产
用户画像架构

用户标识
1. pin: Personal Identification Number个人识别码
2. userID存在问题:
(1) 无法包括同一用户其他网络数据(大量数据缺失);
(2) 必须是登录状态才能记录数据(未登录状态数据丢失);
(3) 多个账号(利益趋势下注册多个账号获取优惠补贴)
3. uuid: Universally Unique Identifier通用唯一识别码
4. device ID(用户设备ID):按照用户设备信息生成的唯一标识ID
5. 自然人概念NPI:一个用户多个ID(userID/deviceID/Mobile/Payaccount/Email/QQ/identityID/unionID),各种ID之间关联(浏览:userID->deviceID,绑定:userID->Mobile,支付:userID->Payaccount),这些一起构成一个实际用户->自然人,所有ID对应一个唯一编号NPI
6. 求解最大连通子图,每个连通子图表示一个自然人
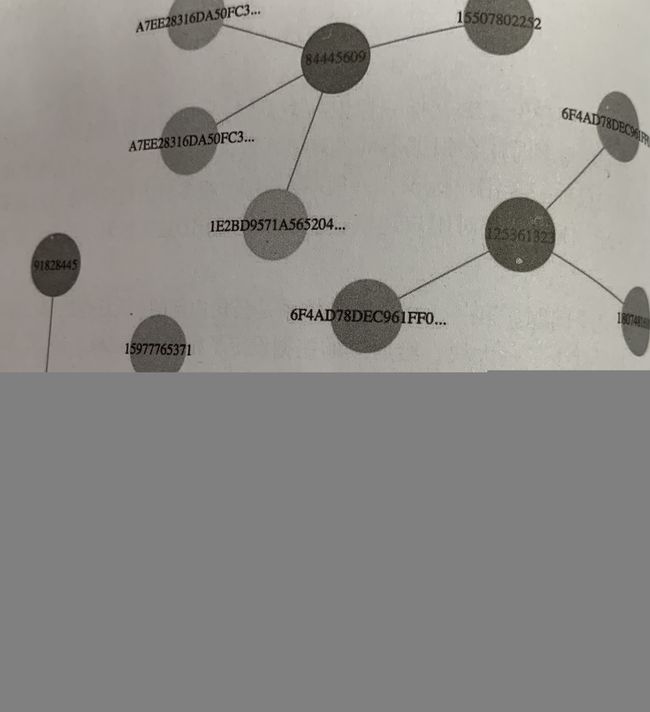
连通图求解问题:用户ID数量几十亿,并差集难以并行,MapReduce迭代时间复杂度O(N)(N为最大子图半径),面对超级簇会出现迭代轮数过多无法及时收敛的问题
解决办法:优化的MapReduce算法,Hash-To-Min,时间复杂度为O(log(N))
特征数据
1. 数据稀疏——大量特征
2. 用户特征库规划和建设:
(1) 不同标签跨品类有效,如婚纱摄影—结婚有小孩,美甲—性别、母婴人群;
(2) 不同属性的关联性,所以为了避免重复复提取特征,高效挖掘降低人力时间成本,需要对用户特征库进行规划和建设;
(3)静态属性、LBS数据、动态行为、外部数据、间接相关实体(居住城市、商圈)(大大解决数据稀疏问题),年月日周节假日进一步划分
样本数据
1. 样本缺失、样本少、单样本
2. 找、转、试
找:问卷、内部员工、人工标注、用户注册服务提交
转:变为可按照时间切分的预测问题,用现在预测未来
试:自学习、直推式、PU学习(One-Class-SVM/Biased-SVM/SPY/NB)等
3. 未标注样本对机器学习有效:数据分布角度分析:如果一个参数化模型能够分解成P(x,y/theta)=P(y/x,theta)*P(x/theta),则未标记示例的价值体现在,能够帮助更好的估计模型参数,从而提高模型性能
标签建模
1. 涉及领域:算法模型调优+系统工程
(1) 系统工程:标签数据更新、特征数据更新、标签质量监控、特征质量监控、新标签开发;
(2) 算法:优化目标因为面对的问题(分类、回归、语义分析、协同等)广泛,因此也较为广泛(这一点可以对比搜索和广告的明确目标,如CTR、CVR、毛利、访购率等)
2. 大数据计算工具支撑:基于Hadoop生态衍生出的大数据处理工具:
(1) 大数据存储:HDFS、HBase、MongoDB、RocksDB;
(2) 离线批量海量计算:MapReduce、Hive、Spark;
(3) 实时计算框架:Storm、Spark-Streaming、Flink
组件+框架——>结合业务定制开发
美团实例-离线标签生产平台-系统层面


1. 自动训练:
(1) 针对线上模型随时间推移效果下降的问题;
(2) 上线配置文件,重新训练模型,人工确认,上线;
(3) 降低人力成本
2. 特征爬虫:
(1) 特征开发困难;
(2) 提供样本数据,模型会自动搜索内部库,通过计算样本与特征之间的相关性,进行打分;
(3) 能够发现重要的潜在特征,解决了人工找特征难的问题
美团实例-实时标签生产平台-系统层面
实时特征
1. 根据用户行为实时产生的特征数据
2. Kafka,将用户行为作为消息队列中的消息(Kafka高吞吐量的分布式消息系统,更好的吞吐量、内置的分区、冗余及容错性)
3. Storm,构建一系列实时消息消费处理的拓扑,进行实时特征生产:
(1) 解决了实时处理复杂数据的痛点:需要维护一堆消息队列和消费者及其构成的复杂的图结构;
(2) 抽象消息传递,自动并发流式计算,让用户更专注于业务逻辑;
(3) 基于Storm的二次开发和封装
实时计算
1. 用户行为数据:异步,生产入库后一段时间保持不变
例子:用户打开app—>用户定位消息—>查询城市天气(异步计算完毕)—>天气标签写入数据库(用户没有任何动作,实时天气标签计算完成),当用户浏览相应业务时,后台就可以查询实时天气,做出相应的策略
用户行为就可以直接出发部分实时标签的计算,在用户没有想后台请求查询的情况下,标签数据可以提前计算完毕并入库
2. 用户请求数据:同步,当前上下文变化
例子:美食品类实时偏好,通过短期内浏览点击美食品类信息计算,时间越久权重越低
美团实例-标签挖掘-算法
1. 特征工程
特征提取:数据格式化
特征监控:特征质量保障
特征处理:异常数据处理,过滤、嵌入、包装等

2. 模型

说明:图表均来自《美团机器学习实践》-美团算法团队著