HBase Snapshot 相关操作原理
转自:https://blog.csdn.net/t894690230/article/details/52121613
1. 前言
HBase 从0.95开始引入了 Snapshot,Snapshot 相关操作主要是对 table 做备份与还原等,这在容灾方面是必不可少的,而由于在实际工作中遇到了部分问题需要阅读源码以了解其具体的原理,所以本文将根据源码来简单描述 Snapshot 相关操作的原理。
注:本文着重关注 snapshot 相关操作时,目录或文件的变化情况,未对每一细节的源码做研究。如果想直接知道这一系列操作时目录的变化情况,可直接看第 4 节,HBase 版本为 1.1.2。
2. 问题
这里需要先说明的是 Snapshot 相关操作(export 除外)的实现并不涉及到对 table 实际数据的拷贝,而是仅仅拷贝一些元数据,比如组成 table 的 region info、表的 descriptor、对应的 HFile 的文件的引用等。同时 Snapshot 是一系列相关文件所组成的文件夹内容,不是一个单独的文件(尤其不要误以为 .snapshotinfo 就是快照文件)。
本文主要解决的问题如下:
1) snapshot 具体是什么?它所包含文件的具体信息是什么?
2) Take、Clone、Restore、Delete、Export 操作的具体实现原理(主要看其目录的变化情况)
3) 目录能改变吗?
注:在对 snapshot 相关操作做分析时,可能会引出新的问题,在后面会做具体分析。
3. Snapshot 相关文件与数据结构
snapshot 包含的是一些元数据,根据这些元数据可以重建表,也可以定位到具体的 HFile 文件(到这里就需要对 HBase 数据的物理存储结构有所了解了,先贴出其基本的原理图如下,具体的描述可以搜一下,到处都是)。
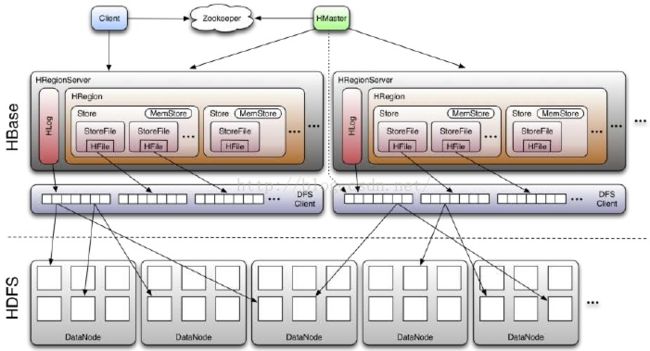
在上图中的 HRegion 外层是 table,可以认为 HRegion 是 table 中的数据被分割后存储到不同的 Region Server 服务器上一小块。Store 包含 MemStore 与 StoreFile,MemStore 是内存数据,这里不讨论,StoreFile 则是具体的物理文件,如果说 HFile 是具体的数据文件,而不代表 link,那么可以认为 StoreFile 其实除了包含 HFile,也包含了 link 数据文件,link 文件是对具体数据文件的引用,同时还有一种文件,reference 文件,这些在后面都会讲到。
那么,表数据在 HBase 中的目录结构大概如下:
注:
1) [/dirName] 代表名称可变的目录,/dirName 代表目录,[fileName]代表名称可变的文件,后同
2) .tmp 目录为临时目录,里面的数据最后都会被转移
3) 所有列出目录并不确认完整
[/Hbase]
- /archive
- /data
- [/namespace] - 表空间
- [/tableName] - 表名称
- /.tabledesc
- .tableinfo.[xxxxxxxx] - 表描述
- /.tmp
- [/region encode name] - region encode 名称
- /.tmp
- [/columns family] - 列族
- [Hfiles / link files] - hfile / link 文件
- .regioninfo - region 信息
- [/region encode name] - region encode 名称
- [/columns family] - 列族
- /.links-[regionName]
- [reference files] - 引用文件
- /.links-[regionName]
- [/columns family] - 列族
- /.tabledesc
- [/tableName] - 表名称
- [/namespace] - 表空间
- /data
- /data
- [/namespace] - 表空间
- [/tableName] - 表名称
- /.tabledesc
- .tableinfo.[xxxxxxxx] - 表描述
- /.tmp
- [/region encode name] - region encode 名称
- /.tmp
- [/columns family] - 列族
- [HFiles / link files] - hfile / link 文件
- .regioninfo - region 信息
- /.tabledesc
- [/tableName] - 表名称
- [/namespace] - 表空间
其中 /archive 除了引用文件是本地的之外,其它文件则基本上是 export 时,来自其它集群的真实数据文件,这也是Snapshot 相关操作中唯一涉及到真实数据文件拷贝的操作。
据于此,snapshot 的基本目录结构则如下(.tmp 中的文件是快照过程中生成的文件,最后的结果中并不存在):
[/Hbase]
- /.hbase-snapshot
- /.tmp
- [/snapshot] - 快照,存储相关元数据
- /.tabledesc
- .tableinfo.[xxxxxxxxxx] - 表的 HTableDescriptor 的序列化
- /.tmp
- [/region encode name] - region encode 名称
- [/columns family] - 列族
- [hfile files / link files] - hfile/ link 文件,空的文件,代表对同名文件的一个引用
- .regioninfo - region 信息
- [/columns family] - 列族
- .snapshotinfo - snapshot 的描述信息
- region-manifest.[region encode name] - 存储 store files的具体位置等信息
- 注:[/region encode name]目录下文件与 region-manifest.[region encode name]文件最终会合并成 data.manifest 文件,并保存到 snapshot 目录下
- /.tabledesc
- [/snapshot] - 快照,存储相关元数据
- [/snapshot] - 快照,存储相关元数据
- /.tabledesc
- .tableinfo.[xxxxxxxxxx] - 表的 HTableDescriptor 的序列化
- /.tmp
- .snapshotinfo - snapshot 的描述信息
- data.manifest
- /.tabledesc
- /.tmp
上面的文字看起来比较费劲,但是我现在这里也没什么专业的画图软件,就能只能用 windows 自带的画图软件先截下图然后改了一下,其目录结构和文件对应的数据结构,大致就如下了(.tmp 里的文件省略了,数据结构与文件对应的完整版在后面会描述):
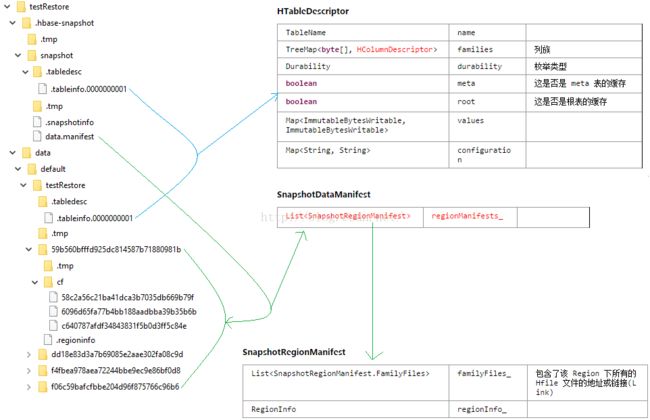
这里面有几个重要的文件需要说明一下,同时其对应的数据结构因为在源码中作为数据的载体随处可见,理解其数据结构也是看懂源码的很重要的一步,所以这里同时会列出对应的数据结构信息,如下(并不完整):
HTableDescriptor
| TableName | name | |
TreeMap<byte[], HColumnDescriptor> |
families | 列族 |
| Durability | durability | 枚举类型 |
| boolean | meta | 这是否是 meta 表的缓存 |
| boolean | root | 这是否是根表的缓存 |
| Map ImmutableBytesWritable> |
values | |
| Map |
configuration | |
HTableDescriptor 中的信息,最后会被写入 .tableinfo.[xxxxxxxxxx] 文件,位于[/snapshot]/.tabledesc 目录, 对应[/tablePath]/.tabledesc 目录下的同名文件。
HRegionInfo
| TableName | tableName | 表名称 |
| long | regionId | |
|
|
regionName | Region Name |
| int | replicaId | |
| boolean | offLine | 是否离线 |
| boolean | split | 是否分离 |
|
|
startKey | |
|
|
endKey | |
| int | hashCode | |
| String | encodedName | 编码后的名称,作为存储 region 的上级目录名 |
HRegionInfo 中的信息最后以字节码的形式被存储在 .regioninfo 文件中,[/tablePath]/[encodedName] 目录下,因为所有的 store file 位置信息最后都被consolidate(合并)到 data.manifest 中了,所以 snapshot 中并不存在此文件。
SnapshotDescription
| Object(String) | table | 表名称 |
| ByteString | name | snapshot Name |
| int | version | 版本 |
| ... | ... | 更多属性 |
SnapshotDescription 中的信息,最后被写入 .snapshotinfo 文件,位于 .hbase-snapshot 目录下。
SnapshotRegionManifest
| bitField0_ | ||
| List |
familyFiles_ | 包含了该 Region 下所有的 Hfile 文件的地址或链接(Link) |
| memoizedHashCode | ||
| memoizedlslnitialized | ||
| memoizedSerializedSize | ||
| memoizedSize | ||
| RegionInfo | regionInfo_ | |
| unknownFields | ||
| version |
SnapshotRegionManifest 中的信息并不单独存储,而是集合存储,下面会讲到。这里提一下,代码中出现的 Map
-
region_info { -
region_id: 1468477067115 table_name { -
namespace: "default"qualifier: "testRestore" -
} -
start_key: "\000\000\000\000"end_key: "\000\000\000\001"offline: false split: false replica_id: 0 -
} -
family_files { -
family_name: "cf"store_files { -
name: "3d64317c8b5344a0b7e591d5cf907e6e" -
} -
store_files { -
name: "d0b4d34cd8cb47bc8f0070afe83b20d1" -
} -
store_files { -
name: "e69ad852b0a748718ffc6c07dcfad8bc" -
} -
}
SnapshotDataManifest
| bitField0_ | ||
| memoizedHashCode | ||
| memoizedlslnitialized | ||
| memoizedSerializedSize | ||
| memoizedSize | ||
| List |
regionManifests_ | |
| TableSchema | tableSchema_ | |
| unknownFieldSet |
SnapshotDataManifest 中的信息最终会被保存到 data.manifest 文件中,位于 [snapshotPath]目录下,它是 SnapshotRegionManifest 数据的集合,据此可以找到所有备份的 region、store file 等信息或具体位置。其示例如下:
-
table_schema { -
table_name { -
namespace: "default"qualifier: "testRestore" -
} -
attributes { -
first: "IS_META"second: "false" -
} -
column_families { -
name: "cf"attributes { -
first: "DATA_BLOCK_ENCODING"second: "NONE" -
} -
attributes { -
first: "BLOOMFILTER"second: "ROW" -
} -
attributes { -
first: "REPLICATION_SCOPE"second: "0" -
} -
attributes { -
first: "COMPRESSION"second: "NONE" -
} -
attributes { -
first: "VERSIONS"second: "1" -
} -
attributes { -
first: "TTL"second: "2147483647" -
} -
attributes { -
first: "MIN_VERSIONS"second: "0" -
} -
attributes { -
first: "KEEP_DELETED_CELLS"second: "FALSE" -
} -
attributes { -
first: "BLOCKSIZE"second: "65536" -
} -
attributes { -
first: "IN_MEMORY"second: "false" -
} -
attributes { -
first: "BLOCKCACHE"second: "true" -
} -
} -
} -
region_manifests { -
region_info { -
region_id: 1468637981928 table_name { -
namespace: "default"qualifier: "testRestore" -
} -
start_key: "\000\000\000\000"end_key: "\000\000\000\001"offline: false split: false replica_id: 0 -
} -
family_files { -
family_name: "cf"store_files { -
name: "617722f185be4c31a7e1dad6d697f96f" -
} -
store_files { -
name: "d1cade129d0a4663b290163774f93d1b" -
} -
store_files { -
name: "d390ebaae77b4f2d8a6a63dc0afcd16f" -
} -
} -
} -
region_manifests { -
region_info { -
region_id: 1468637983894 table_name { -
namespace: "default"qualifier: "testRestore" -
} -
start_key: ""end_key: ""offline: false split: false replica_id: 0 -
} -
family_files { -
family_name: "cf"store_files { -
name: "0a3641d6754e4cdfbf4cd5412b2e5027.e38ba7d189fdc320ccd967bcc7e64258" -
} -
store_files { -
name: "2704e81af3284eabb170d5e86d9dab04.e38ba7d189fdc320ccd967bcc7e64258" -
} -
store_files { -
name: "be689528dfbe491db617bcc9f7b913c2.e38ba7d189fdc320ccd967bcc7e64258" -
} -
} -
}
4. Snapshot 系列操作原理
这里尽量不涉及到太多源码,而仅仅是描述其步骤,并且太多的检查是否可行等之类也一并省略了,都默认为其是可行的,同时基于 Hadoop 其它组件的文件跨集群、跨机器的拷贝,以及 RPC 调用、MapReduce 计算模型等都不在这里详述。
以下的描述会涉及到上节所描述的数据结构,就不再详细说明了。
针对 Snapshot 系列除 export 操作之外的其它操作,可能会存在一个疑问,就是:如果 snapshot 只是存储了元数据,那么如果原来的数据被改变了
4.1 Take
描述:Take 操作尝试从指定的表中获取一个 snapshot。该操作在 regions 作 balancing,split 或者 merge 等迁移工作的时候可能会失败。
Snapshot包括在线和离线的方式:
- 离线方式是disabletable,由HBase Master遍历HDFS中的table metadata和hfiles,建立对他们的引用。
- 在线方式是enabletable,由Master指示region server进行snapshot操作,在此过程中,master和regionserver之间类似两阶段commit的snapshot操作。
Take 在线方式的简单步骤如下:
- 准备工作,检查是否可以进行快照并重建工作目录(/.hbase-snapshot/.tmp)
- 清理工作目录,目录地址是 /.hbase-snapshot/.tmp
- 把 snapshotDescript 写到工作目录 .snapshotinfo 文件中,位于 /.hbase-snapshot/.tmp/[/.snapshotName] 目录下
- HMaster 通过 ZK 上发布任务,RS 服务器检测到新任务 (MARK -1)
- RS 服务器刷新缓存
- RS 服务器将 region info 写入到 .regioninfo 文件中,位于 Snapshot 的临时目录
- RS 服务器遍历 store files,并创建 V1 或 V2 版本的对 store files 的引用(V1 是对应的目录下有一个空的同名文件,V2 是一个文件,其名称指向 store file 文件)
- 等到所有任务完成后,创建一个新的 table desctiptor,写入文件 .tableinfo.[xxxxxxxxxx] 中,位于 /.hbase-snapshot/.tmp/[/.snapshotName]/.tabledesc 目录下 (MARK - 2)
- 对离线的 region 做生成快照(就遍历HDFS 中的 table meatadata 和 hfiles 就好了,不需要刷新缓存等)
- 将所有 V1 或 V2 版本的对 store files 的引用信息合并到 data.manifest 文件中,位于/.hbase-snapshot/.tmp/[/.snapshotName] 目录下
- 将临时目录下的文件转移到正式目录下,正式目录地址为:/.hbase-snapshot/[/snapshotName]
那么针对离线的表,其实就是上面的步骤中没有 MARK -1 与MARK -2 两步,就不再赘述了。
其实离线于在线的区别主要在于:
- 离线方式主要针对表被关闭了的情况,关闭一张表意味着所有的数据都写入了磁盘,而且不允许任何读写操作。在这种情况下,生成快照仅仅就是获取表元数据并且与磁盘中的HFiles保持关联。主节点执行操作需要的时间,主要取决于HDFS的namenode提供文件列表需要的时间。
- 在线方式则主要针对有表开启的情况(也会处理被关闭的表),这个时候每个 RS 都可能不断的处理 put 和 get 请求,这种情况下,主节点接受到快照请求后需要每个 RS 都为其生成一份快照,主要是需要刷新缓存等操作。
4.2 Export
描述:Export 操作拷贝指定 snapshot 的 data 和 metadata 到另一个集群。该操作仅影响HDFS,不会和 HBase 的Master 或者 Region Server 通信(这些操作可能会导致集群挂掉)。
Export 操作是 Snapshot 系列操作中唯一涉及到真实数据拷贝的一个操作,因为它涉及到跨集群。并且 export 操作会有过多的参数,如下所示:
- -snapshot
- -target
- -copy-to
- -copy-from
- -no-checksum-verify
- -no-target-verify
- -mappers
- -chuser
- -chgroup
- -bandwidth
- -chmod
- -overwrite
- -h || --help
讲真,我还没有对这些参数做一个全面的了解,但是有两个参数是必须的,即“-snapshot”和“-copy-to”,其命令格式如下(也是常用的命令格式):
sudo -u hbase hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot snapshotName -copy-to hdfs://host:port/hbase
这里也就指定了“-snapshot”和“-copy-to”参数,所以其基本步骤也就按照这两个参数来描述:
- 设置快照目录,主要是根据“snapshot.export.skip.tmp”的值判断是否要跳过临时目录,默认不跳过
- 检查快照在目标集群位置是否存在,如果存在,则根据“-overwrite”参数的值,判断是否要覆盖,默认不覆盖
- 利用 org.apache.hadoop.fs.FileUtil 类,将指定 Snapshot 拷贝到目标集群,不指定“-target”,则目标 snapshot 名称与源 snapshot 名称相同
- 开始 MR(MapReduce) Job 任务,这里只有 Map 阶段,没有 Reduce 阶段
- 在 ExportMapper(即这个 Job 的 Map 阶段实现类)初始化时,会设置输出的根目录(outputRoot)、输入的根目录(inputRoot)、输入的归档目录(inputArchive)、输出的归档目录(outputArchive)等属性,其中 inputArchive = [/inputRoot]/archive、outputArchive =[/outputRoot]/archive(这里的 archive 目录是确定的,位于 HConstants 类的 HFILE_ARCHIVE_DIRECTORY 常量,所以是不能改变的)。
- 在 Map 阶段,如果在目标集群存在与源文件同名的文件,则跳过
- 然后会读取源数据文件的输入流(InputStream)
- 这里如果是store file,那么因为 store file 可能是一个 link 文件,所以如果是 link 文件,那么它首先会根据 link 文件的链接位置去查找真正的数据文件,如果没有找到,它再依次尝试到 HFile 的位置([/Hbase]/data/[/namespace]/[/tableName]/[/region encode name]/[/columns family]目录下)、临时目录的 HFile 位置([/Hbase]/.tmp/data/[/namespace]/[/tableName]/[/region encode name]/[/columns family]目录下)、归档目录下的 HFile 位置([/Hbase]/archive/data/[/namespace]/[/tableName]/[/region encode name]/[/columns family])去找,直到找到真实的数据文件,或者抛出异常
- 根据输入流拷贝真实数据文件到目标集群下,目录位置为:[/outputRoot]/archive
- MR Job 运行完成后,数据拷贝到集群的工作也算是完成了,但此时如果需要将数据从临时目录转移到目标集群的 Snapshot 目录下(fs2:/.snapshot/)
- 验证 Snapshot 完整性
这里会有一个疑问(疑问1):Export 在将 data 拷贝到其它集群后,是位于 archive 目录下的,而在 Snapshot 拷贝到其它集群前后,并没有改变 Snapshot 中 store file 的位置信息,那么在做 restore / clone 时,link 的位置怎么处理?
4.3 Restore / Clone
描述:
- Clone:该操作用指定 snapshot 的 schema 和数据来创建一个新表。该操作不会对原表或者该 snapshot 造成任何影响。
- Restore:该操作将一个表的 schema 和 data 回滚到创建该 snapshot 时的状态。
说明:Restore 与 Clone 都不涉及真实数据文件的拷贝,而仅仅是通过 link 来链接到真实的数据文件。
因为 Restore 系列操作里面包含了 Clone 操作,并且为了不混淆 Restore 里面的 region 部分,这里把 Restore 称作 Restore 系列操作,其内包含的 restore 不变,那么其步骤大致如下:
- 根据 Snapshot 获取所有 region 的名称,命名为 regionNames (Set
) - 根据目前的 table 获取现有的所有 region 的信息(数据结构参见List
),并进行分类操作,如下: - 1) 如果现有的 region 名称存在于 regionNames 中,则这部分 region 将做 restore 操作
- 2) 如果现有的 region 名称不存在于 regionNames 中,则这部分 region 将做 remove 操作
- 3) 如果 regionNames 中有的 region 名称,当前 table 中没有,则这部分操作做 add / clone 操作
- restore 操作:
- 创建 link 文件与对应的 reference 文件(reference 文件位于 archive 对应目录中,不一定会被创建)
- 将 snapshot 之后新增的 store file 转移到 archive 对应目录中(省略了详细的步骤)
- remove 操作:
- 将相关 store file 转移到 archive 的对应目录中
- clone / add 操作:
- 创建 .regioninfo 文件, 位于[/tablePath]/[encodedName] 目录下
- 克隆 region 目录
- 为所有 store file 创建 link 与对应的 reference 文件
针对 4.2 中的疑问,在 Restore 时,并未发现 link 文件有主动转移到 archive 目录,而 link 的链接路径既然不是真实的 HFile 地址,这样难道不是错误的吗?
那么在 HBase 里,针对 link 文件有一个对应的 HFileLink 类,里面包含了 3 个路径属性,originPath、tempPath、archivePath,其中 archivePath 便是 originPath 路径在 archive 目录下对应的地址,而调用 HFileLink 的 open 方法以返回输入流时,会轮流的尝试打开 originPath、tempPath、archivePath 三个路径,所以如果按此方法打开 store file,就能找到 archive 目录下的 store file 文件。它最主要的一个方法 tryOpen 来自于其父类 Filelink 的内部类FileLinkInputStream,源码如下:
-
private FSDataInputStream tryOpen() throws IOException { -
// 遍历所有地址,尝试找到正确的文件 -
for (Path path: fileLink.getLocations()) { -
if (path.equals(currentPath)) continue; -
try { in =fs.open(path, bufferSize); -
if (pos != 0) in .seek(pos); -
assert( in .getPos() == pos) : "Link unable to seek to the right position=" + pos; -
if (LOG.isTraceEnabled()) { -
if (currentPath == null) { -
LOG.debug("link open path=" + path); -
} else { -
LOG.trace("link switch from path=" + currentPath + " to path=" + path); -
} -
} -
currentPath = path; -
return ( in ); -
} catch(FileNotFoundException e) { -
// Try another file location -
} -
} -
thrownew FileNotFoundException("Unable to open link: " + fileLink); -
}
Clone 操作其实就跟 restore 里面的 clone 操作类似,只是其实从 table 开始克隆的,如果 table 存在,就抛出 TableExistsException 异常,所以也就不必赘述了。
4.4 Delete
描述:Delete 操作将一个 snapshot 从系统中移除,释放磁盘空间,不会对其他拷贝或者snapshot造成任何影响。
Delete 操作的原理比较简单,就是从磁盘上删除 snapshot,删除前会检查这个 snapshot 是否已经完成,如果没完成会抛出异常。
5. 相关操作的影响
在做完 Snapshot 之后,相关的 HFile 的改动如果不合理,必定会对 Snapshot 照成影响,这里疑虑较多的可能就是 put、update(也是put)、major_compact 操作。
那么事实上,Hbase 在每一次 flush 时,都是将内存中的数据新增到一个新的 HFile 文件中,而不会追加到原本的 HFile 文件中,所以,put 操作并不会影响 Snapshot (每一次的 take 操作都会 flush 内存,除非是离线的表)。
而 major_compact 操作,在压缩 HFile 数据时,会将所有的新的数据新增到一个新的 HFile 文件中,旧的 HFile 会被转移到 archive 目录中,而原本 acchive 中无用的 HFile (比如删除了 Snapshot)会被删除,所以major_compact 尽管对 HFile 的改动比较大,但是它并不会对 Snapshot 中需要的 HFile 文件做删除,而仅仅是转移了位置。
6. 总结
那么到最后,经过对 Snapshot 部分文件以及其相关操作的分析,可以再来看看之前的几个问题。
1) Snapshot 具体是什么?它所包含文件的具体信息是什么?
Answer:Snapshot 其实是一系列文件的组合,这些文件中重要的有.snapshotinfo、.tableinfo.[xxxxxxxxxx] 、.regioninfo、 data.manifest,他们包含了对 table、region、store file 等的具体描述元信息,通过对 Snapshot 里的文件做相应的解析,可以还原备份前的 table、region、family 等信息,同时能够找到存储有实际数据信息的 store file 文件,而由于 HBase 在删除文件时,并不会真正的删除文件,而是将文件转移到 archive 目录,所以 Snapshot 始终能保证在任何时候都能还原数据。
2) Take、Clone、Restore、Delete、Export 操作的具体实现原理。
Answer:究其根本,这一系列操作其实就是对 table 以及其下面的所有数据做一个备份与还原等操作,而 Take、Clone、Restore、Delete 操作本身并不涉及到 store file 文件本身的操作,Export 因为涉及到跨集群,所以需要将数据拷贝到其它集群,而由于 HBase 基于 Hadoop 之上,文件系统基于 HDFS,而 Hadoop 实现了跨集群拷贝文件,以及其它譬如集群间通信等方法,这让 Snapshot 的这一系列操作实现变得不那么太关注底层的实现,所以相对而言其实现原理是相对容易理解的。
3) 目录能改变吗?
Answer:不能!即便是 Export 操作,也只能指定其它集群的 HBase 目录位置,不能改变其内在结构。
从程序代码上讲,Snapshot 相关操作的涉及到的内部目录名称都是使用类里面的常量保存,比如
HConstants.HFILE_ARCHIVE_DIRECTORY = "archive"、HConstants.SNAPSHOT_DIR_NAME = ".hbase-snapshot" 等,所以除了改变源码,否则是没办法改变其内部目录结构的。当然,改源码使其目录结构改变是及其不理智的。
其实在做 Snapshot 分析的主要原因之一在于希望能解释 Export 为什么会将数据发送到 archive 目录,而不是直接放在 data 目录下,就这个问题来分析一下为什么不能通过改源码来改变其目录结构。
在 data 目录下的 store file 都是正在使用的,Export 只是传输过来,还没确定是否要使用啊。另外如果改成其它名称,那也没必要啊。