利用爬虫爬取百度词条(基于bs4的简单爬虫学习)
爬虫技术也是数据算法工程师必备的技能之一吧。之后要把爬虫这棵技能树点亮。
本文记录一次简单的爬虫 程序的学习,该程序主要用来爬取百度词条的标题和简介。
比如如下的python 百度词条,红色框是标题,而蓝色框是简介
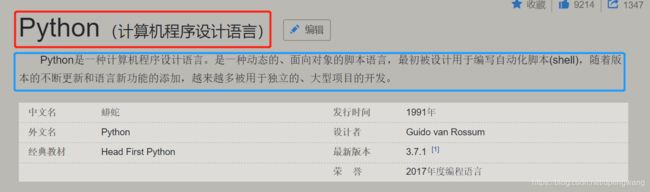
爬虫的目的是爬取跟python有关的百度词条的标题和简介。
程序的逻辑主要如下
- 获取网页内容,根据属性来筛选出页面有关的信息,不仅包括词条的标题和简介,也包含该页面包含的其他url地址,这样才能从一个页面出发爬取跟该页面词条相关的词条信息。
主要功能体如下
- 首先要有个url管理器,里面存放着已经访问过的url地址和待访问的url地址,之所以要记录访问过的,是为了防止陷入重复访问的死循环中。这个url管理器可以添加新的url和对外提供没有访问过的url
- 下载器downloader,该下载器主要负责将制定url的页面下载到本地供后续解析使用
- 网页解析器parser,同于解析网页,从网友文档中提取标题简介以及其他网页的url
- 输出器outputer,将最终的结果输出,以网页版的形式呈现
主函数如下
class SpiderMain(object):
def __init__(self):
self.urls = url_manager.UrlManager()
self.downloader = html_downloader.HtmlDownloader()
self.parser = html_parser.HtmlParser()
self.outputer = html_outputer.HtmlOutputer()
def craw(self, root_url):
count = 1
self.urls.add_new_url(root_url)
while (self.urls.has_new_url()):
try:
new_url = self.urls.get_new_url()
print("craw %d : %s" %(count, new_url))
count +=1
html_content = self.downloader.download(new_url)
new_urls, new_data = self.parser.parse(new_url, html_content)
self.urls.add_new_urls(new_urls)
self.outputer.collect_data(new_data)
if count == 10:
break
except:
print("craw failed")
self.outputer.output_html()
if __name__ == "__main__":
root_url = "https://baike.baidu.com/item/Python/407313"
obj_spider = SpiderMain()
obj_spider.craw(root_url)
程序的逻辑很清晰,从url管理器里取出一个url,然后根据url将网页内容下载下来,送到解析去解析,解析器返回解析出的标题简介内容以及新的url,并将新的ur加入url管理器。
重复这个过程知道某个条件后跳出。
UrlManager
class UrlManager(object):
def __init__(self):
self.new_urls = set()
self.old_urs = set()
def add_new_url(self, url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urs:
self.new_urls.add(url)
def add_new_urls(self, urls):
if urls is None or len(urls) == 0:
return
else:
for url in urls:
self.add_new_url(url)
def has_new_url(self):
return len(self.new_urls) != 0
def get_new_url(self):
new_url = self.new_urls.pop()
self.old_urs.add(new_url)
return new_url
这个类里面主要有四个方法:
add_new_url将新爬到的url添加到未访问的url集合中add_new_urls调用上面一个方法添加多个urlhas_new_url判断是否有新的url作为爬虫种子urlget_new_url获取一条未访问过的url,并把它加入已访问的url集合中
HtmlDownloader
import urllib.request
class HtmlDownloader(object):
def download(self, url):
if url is None:
return None
response = urllib.request.urlopen(url)
if response.getcode() != 200:
return None
return response.read()
HtmlDownloader网页下载器。获取网页的文档
import re
from urllib.parse import urljoin
from bs4 import BeautifulSoup
class HtmlParser(object):
def parse(self, page_url, html_content):
if page_url == None or html_content == None:
return
soup = BeautifulSoup(
html_content,
"html.parser",
from_encoding="utf-8"
)
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_data(page_url, soup)
return new_urls, new_data
def _get_new_urls(self, page_url, soup):
new_urls = set()
links = soup.find_all("a", href = re.compile("/item/*"))
for link in links:
new_url = link["href"]
new_full_url = urljoin(page_url, new_url)
new_urls.add(new_full_url)
return new_urls
def _get_new_data(self, page_url, soup):
res_data ={}
title_node = soup.find("dd", class_="lemmaWgt-lemmaTitle-title").find("h1")
res_data["title"] = title_node.get_text()
summary_node = soup.find("div",class_="lemma-summary")
res_data["summary"] = summary_node.get_text()
# print(summary_node.get_text())
res_data["url"] = page_url
return res_data
网页解析器
首先看_get_new_urls方法,用来获取网页中的url和,是如何定位网页中的其他词条url呢?
在python词条网页上右击蓝色字体审查元素
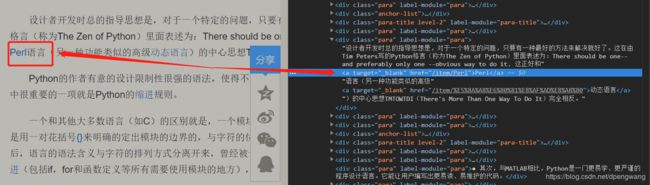
可以看到其对应着a标签,属性时href,根据这个属性来用beautifulsoup获取
links = soup.find_all("a", href = re.compile("/item/*"))
_get_new_data也是一样的原理, 只不过标题简介的属性值分别为dd和div
HtmlOutputer
class HtmlOutputer(object):
def __init__(self):
self.datas = []
def collect_data(self, data):
if data == None:
return
self.datas.append(data)
def output_html(self):
fout = open("output.html","w")
fout.write("")
fout.write("")
fout.write("")
for data in self.datas:
print(data["title"])
fout.write("")
fout.write("%s "%data["url"].encode("utf-8"))
fout.write("%s "%data["title"].encode("utf-8"))
fout.write("%s "%data["summary"].encode("utf-8"))
fout.write(" ")
fout.write("
")
fout.write("")
fout.write("")
fout.close()
写h5,没啥好说的,注意编码问题即可