xgboost使用cross validation
简要的说明下交叉验证的作用:
- 防止过拟合。他虽然不能在质的级别上提高我们模型效果,但是能够防止我们的模型过拟合,比如xgboost里面,过拟合的一个表现就是生成的树太多,假如们设置了xgboost 的
early_stopping_rounds参数,那么树会一直生成直到验证集上auc(假设这里的评估标准是auc)不再上升为止,这样的话如果验证集划分的不准确,就会导致验证集上的auc不准,那么生成的树数目也就可能过多。 - 比赛中可以使线上线下的auc一致。比赛的时候常常会发现,本地的auc很高,而提交上去auc却不如线下的。可能是因为线下使用的验证集太少,评估的泛化能力弱。而交叉验证可以用到所有的数据做验证。
- 尽可能多的使用数据训练。不用交叉验证的话我们需要从训练集中划分出验证集,如果本来训练集就少的话,那么再划分出一部分数据做验证那么可训练的数据就更少了,那样预测的效果将会大打折扣。
我们用交叉验证的目的是什么呢?:
调参:我们需要根据结果结果的auc进行调参,就得保证输出的auc是准确可靠的,这时候用交叉验证就能保证可靠性。利用交叉验证调参也一定程度上限制了过拟合。
当参数固定后,我们通过cv获得最佳的迭代次数,然后再训练所有的数据得到一个新模型(这样可以利用所有的数据),并用这个新模型预测结果。
举个例子
不使用交叉验证
没用xgboost交叉验证的时候,我们通常是通过train_test_split将数据划分成训练集和验证集,训练的时候根据验证集上的auc,得到最佳的boost_round,然后在这个boost_round下去预测数据。加入7:3分割数据,那么最终训练出的模型只用了70%的数据。
当然你也可以在固定参数后再用全部数据训练处一个新模型,但这个模型的准确性却不能保证,固定好的参数(当前最优)对应的是那70%数据,在剩下的30%数据上的效果咋样就不一定了。
import xgboost as xgb
from Utils import pathUtils
import pandas as pd
from sklearn.model_selection import train_test_split
from Process.genBasicData import genData
from Utils import feaUtils
train_data = genData(pathUtils.train_path)
test_data = genData(pathUtils.test_path)
param = {'max_depth': 3,
'learning_rate ': 0.01,
'silent': 1,
'objective': 'binary:logistic',
"eval_metric":"auc",
"scale_pos_weight":10,
"subsample":0.8,
"min_child_weight":1,
"n_estimators": 1}
# features = [i for i in list(train_data.columns) if i not in ["ID","y"]]
features = feaUtils.train_fea
x_train, x_valid, y_train, y_valid = train_test_split(train_data[features],train_data["y"],
test_size=0.2, random_state=66)
dtrain = xgb.DMatrix(x_train, y_train)
dvalid = xgb.DMatrix(x_valid, y_valid)
dtest = xgb.DMatrix(test_data[features])
evallist = [(dtrain,"train"),(dvalid,"valid")]
num_round = 20000
bst = xgb.train(param, dtrain, num_round, evals=evallist, early_stopping_rounds=30)
y_pre = bst.predict(dtest, ntree_limit = bst.best_ntree_limit)
res = pd.concat([test_data[["ID"]],pd.DataFrame(y_pre,columns=["pred"])],axis=1)
res.to_csv(pathUtils.predict_root_path+"3.csv",index=False)
线下:

线上:
![]()
可以看到出现了过拟合,线下小于线上。
使用交叉验证
这里使用10折交叉验证
import xgboost as xgb
from Utils import pathUtils
import pandas as pd
from sklearn.model_selection import train_test_split
from Process.genBasicData import genData
from Utils import feaUtils
train_data = genData(pathUtils.train_path)
test_data = genData(pathUtils.test_path)
param = {'max_depth': 3,
'learning_rate ': 0.01,
'silent': 1,
'objective': 'binary:logistic',
"eval_metric":"auc",
"scale_pos_weight":10,
"subsample":0.8,
"min_child_weight":1,
}
features = [i for i in list(train_data.columns) if i not in ["ID","y"]]
dtrain = xgb.DMatrix(train_data[features],label=train_data['y'])
dtest = xgb.DMatrix(test_data[features])
cv_res= xgb.cv(param,dtrain,num_boost_round=2000,early_stopping_rounds=30,nfold=10, metrics='auc',show_stdv=True)
print(cv_res)
#cv_res.shape[0]为最佳迭代次数
bst = xgb.train(param,dtrain,num_boost_round=cv_res.shape[0])
y_pre = bst.predict(dtest)
res = pd.concat([test_data[["ID"]],pd.DataFrame(y_pre,columns=["pred"])],axis=1)
res.to_csv(pathUtils.predict_root_path+"cv_res.csv",index=False)
线下
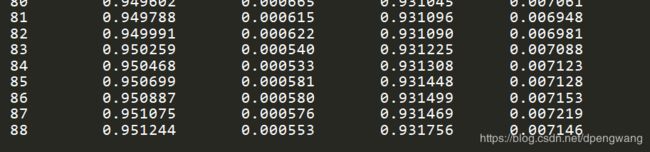
线上:
![]()
可以看到线上线下几乎保持一致