StyleBank 学习小记:一个可以分离风格与内容的图像风格转换器
实现代码:https://github.com/yjc567/StyleBank
本文是对文章 StyleBank: An Explicit Representation for Neural Image Style Transfer 的整理,以及自己重现其实验的结果和查阅相关资料的记录。
大纲
本文的大体内容分为以下几点:
- StyleBank的网络结构
- StyleBank的训练策略
- StyleBank的特性与优点
- StyleBank的参数调整对实验结果的影响
- 训练结果分析
- Instance normalization简介
- Total Variation(TV)loss简介
- 将VGG net用于特征抽取,以及Gram Matrix 简介
- 对FRIQA和SSIM两个图像质量评价方法的介绍
- 反思
- 参考文献
因为时间有限,加上自己的实验还没有完全结束。所以本文着重于讲述[1, 2, 6, 7, 8]这几个偏向理论的部分,其余部分留在下一次的实验报告中提交
StyleBank的网络结构
网络结构
- 图片编码器(image encoder) E 。
- StyleBank层(StyleBank layer) K ,其中包括 n 个并行的过滤器(filter,在本文中,使用cnn作为filter) {Ki},(i=1,2,…,n) ,对应n个不同的风格。
- 图片解码器(image decoder) D 。

训练分枝
- 自动编码器(auto-encoder)分枝 E→D
- 风格化(stylizing)分枝 E→K→D
训练的目标是使图像的内容(content)经过 E 和 D 后尽可能的不会损失。同时图像的风格信息会被StyleBank加入,以在保持内容的同时将图像用不同风格表现出来。也就是希望网络可以尽可能地将图像的内容和风格分离开。
输入与输出
输入一个图像(content image) I ,编码器 E 会从这个图像抽取出多层特征(multi-layer feature maps) F ,即: F=E(I)
在 E→D 分枝中,直接将 F 传给解码器 D ,得到输出图像 O ,即 O=D(F) ,输出图像 O 应该和输入图像 I 尽可能的接近,这也是我们训练的目标
在 E→K→D 分枝中, F 还需要通过 K 中的某一层 Ki ,得到 Fi~ ,接着再通过解码器 D ,生成对应风格 i 的输出图像 Oi ,即: Oi=D(Fi~),(i=1,2,…,n)
Encoder and Decoder
E 由3层卷积层组成,其步长和卷积大小分别是:
- stride: 1 , 9∗9 kernel
- stride: 2 , 3∗3 kernel
- stirde: 2 , 3∗3 kernel
D 的结构与 E 相反,其3层卷积层的构造是:
- stride: 12 , 3∗3 kernel
- stride: 12 , 3∗3 kernel
- stirde: 1 , 9∗9 kernel
其中除了最后一层以外,每一层后面都加上了Instance normalization和ReLU,关于Instance normalization的简介可以查阅文章后半部分。
StyleBank Layer
由 n 个卷积层组成,代表 n 个不同的风格。
训练策略
loss function
E→D 分枝只需要计算生成图像和原图在识别度上的loss( identity loss LI ):
E→K→D 分枝就需要结合生成图像内容上的loss( Lc ),风格上的loss( Ls ),和一个正则化loss( Ltv(Oi) )):
其中正则化loss Ltv(Oi) 是全变差正则化(total variation (tv) regularization)关于其介绍,请参阅后面的章节。
Lc 和 Ls 则是分别利用VGG-16网络进行特征抽取和格莱姆矩阵(Gram matrix)计算得到的。这两者的介绍放在文章后面中。
其中 {lc} 只用到了VGG-16中的 relu4_2 。
{ls} 用到了VGG-16中的 relu1_2,relu2_2,relu3_2,relu4_2 。
训练策略

敲一遍太麻烦了,所以直接上截图好了 QAQ
其中 T=2 , m=4 (branch大小为4), λ=1 。
StyleBank 的特性与应用场景
特性
分离图像的内容和风格
论文指出 E→D 分枝就是一个图像压缩与重构结构,并且 K 是完全独立于 E 与 D 的,这也是后面增量学习特性的基础。
同时每个 Ki 公用同一对 E 与 D ,极大地节省了内存空间。
此模型对内容和风格的分离可以见我的实验结果(下图),左图为原图(content image),中间是风格画像,右边是生成的图像,虽然生成的图像是一个画师以原图为基础的作画,但是显然生成图像只从中间的图片学来了画家的风格,其内容更接近原图。

传统方法与神经网络的结合
详见论文,这一部分主要介绍了神经网络的风格转换方法和一些传统方法的相似性
支持增量学习
对一个已经训练完成的StyleBank,可以保持其 E 与 D 不变,以增加一个新的 Ki 的方法来增加一个新的风格,固定 E→D 完成对新风格的学习,并且以这种方式得到的网络性能和原先一致。
应用场景
StyleBank可以以两种方式实现风格的融合。
线性融合风格
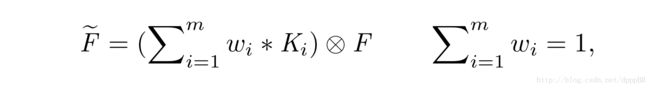
特定区域的风格融合
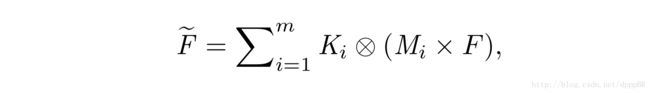

参数调整对实验结果的影响
因为实验还没有全部完成,目前还很难下定论,下次再更新这一段。
训练结果分析
同上。
Instance normalization
在 Texture Networks: Feed-forward Synthesis of Textures and Stylized Images 一文指出,针对每一个输入的图像进行normalization,而不是针对输入的一批图像进行归一化,会得到更好的风格化结果,尽管这篇文章并没有探寻这个现象的原因(不知道为什么,自己不能在arxiv上查看原始版本的论文,所以只能看网络上的中文翻译版本)。
Total Variation(TV)loss
本章节两张图片显示不出来了QAQ
自己查看图片的原网址把,反正也是从别人那里摘抄来的 = =
全变分去噪,或者说全变分loss,是一个经常被用在图像去噪上的方法,这个方法认为图片的噪声点与其周围的像素点有着很高的方差,其计算公式非常简单:
TVLoss反应的是图像的噪声,因此利用这个loss函数生成的图像可以保持光滑。
看一下加了TV正则项以后的图像复原结果和不加的差异:
图(a)是原始图像,图(b)在原图像上加了一定程度的模糊和噪声,图(c)是不加TV项的复原结果,可以看到有一圈一圈的伪影,这是我们不想要的。图(d)是加了TV项以后的复原结果,没有伪影,复原结果基本和原图像相同。
其代码实现也非常简单:
def TVLoss(output_image):
return torch.sum(torch.abs(output_image[:, :, :, :-1] - output_image[:, :, :, 1:])) + torch.sum(torch.abs(output_image[:, :, :-1, :] - output_image[:, :, 1:, :]))VGG net and Gram Matrix
VGG net
为什么VGG net的某些层可以用来抽取特征呢?可能是自己浏览的不是很仔细,竟然无法在网上找到具体的解释或原因,猜测可能很多网络都可以用来抽取特征,只是VGG深度适当,所以其运算速度和结果精确度之间有比较好的平衡?那为什么又是用VGG特定的那几层呢?
Gram Matrix
给定一个实矩阵 A ,矩阵 ATA 是 A 的列向量的格拉姆矩阵,而矩阵 AAT 是 A 的行向量的格拉姆矩阵。
而对一个三维的矩阵 A ,设 A 的大小是 (ch,h,w) 可以把 A 展开为 (ch,h∗w) 的二维矩阵,然后求其gram矩阵就好了。
根据Gram矩阵和协方差矩阵的定义可以看出Gram就是一个偏心协方差矩阵(即没有减去均值的协方差矩阵),因此Gram矩阵相比协方差矩阵,其对角线还可以体现每个特征在图像中出现的量。
其实到底为什么Gram矩阵可以用来计算features之间的loss,还是需要更高深的数学知识才可以解释,希望自己以后有机会可以掌握其真正原理。
FRIQA and SSIM
因为还没有把这两个东西具体应用到我的实验里,所以打算之后再完成这个章节。
反思
感觉自己相关的知识掌握的还不够,阅读论文的方法也有问题,很多东西都是自己问了QZQ之后才明白的。而且对pytorch相关的代码知识也不是很掌握,也是第一次接手这种项目的开发,希望在这段时间里自己可以学到一些有意思也实用的知识。
参考
StyleBank: An Explicit Representation for Neural Image Style Transfer
Instance Normalization: The Missing Ingredient for Fast Stylization
Algorithm With Total Variation Regularization for 3D Confocal Microscope Deconvolution
very deep convolutional networks for large-scale image recognition