0. 算法概述
决策树(decision tree)是一种基本的分类与回归方法。决策树模型呈树形结构(二分类思想的算法模型往往都是树形结构)
0x1:决策树模型的不同角度理解
在分类问题中,表示基于特征对实例进行分类的过程,它可以被看作是if-then的规则集合;也可以被认为是定义在特征空间与类空间上的条件概率分布
1. if-then规则集合
决策树的属性结构其实对应着一个规则集合:由决策树的根节点到叶节点的每条路径构成的规则组成;路径上的内部特征对应着if条件,叶节点对应着then结论。
决策树和规则集合是等效的,都具有一个重要的性质:互斥且完备。也就是说任何实例都被且仅被一条路径或规则覆盖。
从if-then视角来看,构造过程是这样的
1. 由决策树的根节点到叶节点的每一条路径构建一条if-then规则 2. 路径上的内部节点的特征对应着if的判断条件,而叶节点的类对应着规则的then结论
决策树的路径或其对应的if-then规则集合具有一个重要的性质:互斥且完备
即每一个实例都被一条路径或一条规则所覆盖,而且只被一条路径或一条规则所覆盖
2. 条件概率集合
决策树还是给定特征条件下,类别的条件概率分布的一种退化表示(非等效)。
该条件分布定义在特征空间的划分上(每个划分代表一个条件),特征空间被划分为互不相交的单元,每个单元定义一个类的概率分布就构成了一个条件概率分布。
决策树所表示的整体条件概率分布由各个单元在给定条件下类的条件概率分布组成,决策树的每条路径对应于划分中的一个单元。给定实例的特征X,一定落入某个划分,决策树选取该划分里最大后验概率对应的类(期望风险最小化)作为结果输出。这点上和朴素贝叶斯和KNN的决策思想是一致的
0x2:决策树的优缺点
1. 优点
1. 可读性和可解释性强,可通过可视化的方式直观展现 - "分而治之”(divide-and-conquer)策略 2. 对数据预处理的要求较低,不需要预先做数据规范化。这是因为决策树不是非常关注样本特征维度中的数值大小,而是更关注其代表了类别,根据所属的范畴进行二分类,这也是判别式模型的好处 3. 内存开销小,不像DNN深度学习算法需要在内存中保存大量的中间梯度变量,decision tree的内存开销是logN级别的 4. 既可以处理数值数据(连续性),也可以处理分类数据(离散型) 5. 能够处理多分类问题(输出的Y是一个2维数组) 6. 性能优良,分类速度快,单纯由逻辑判断组成
2. 缺点
1. 决策树很容易陷入训练样本数据的细节中,过分地细分会导致训练出一个很"复杂且深"的树出来。这是因为 太过复杂的树很容易对训练数据中的噪音过于敏感 2. 决策树本身存在"不稳定性",训练样本集中的一些微小的变化,可能就会导致决策树建立出一个不同的分类模型,这也是决策树对训练数据样本太过敏感的表现,这个问题可以用决策森林的投票法得到缓解 3. 当数据中某些维度上的分布特别密集(这可能是采样观察量不够的原因),决策树可能会形成偏树,这种偏树无法拟合出真实的数据规律,对之后的分类效果也会下降
3. 决策树对特征工程的依赖
不单是对决策树,对所有分类型机器学习算法特征工程是最基础也是最重要的一个环节(如果特征足够好,模型已经不重要了),我么提供给决策树算法的特征需要足够好,足够具备"代表性、可分性、鉴别型",决策树才能尽可能地从数据中学习到规律。这对特征工程提出了很高的要求,那如何提高特征的鉴别型呢?
1. 一是设计特征时尽量引入domain knowledge(专家领域知识):对于业务领域专家来说,他能通过将人工判断的经验通过抽象转化成一系列的特征维度,人工的经验越丰富,所提取的特征的代表性往往就越强,决策树非常依赖于代表性强的特征 2. 二是对提取出来的特征做选择、变换和再学习,这一点是机器学习算法不管的部分 3. 现在的机器学习还做不到完全的point to point黑盒预测,前期的特征提取和特征预处理在很多场景下还依赖于专家的参与
Relevant Link:
http://scikit-learn.org/stable/modules/tree.html#tree
2. 决策树模型定义
0x1:决策树是判别模型
决策树的训练过程无法得到样本中包含的概率密度分布,它得到的是一个按照不同特征划分的判别规则集合,因此属于一种判别模型
0x2:决策树模型
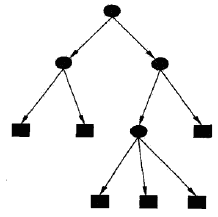
决策树模型是一种描述对实例进行分类的树形结构。决策树由结点(node)和有向边(directed edge)组成。结点有两种类型
1. 内部节点(internal node):表示一个特征维度或一个属性 2. 叶节点:表示一个类
1. 决策树学习
假设给定训练数据集:![]() ,其中,
,其中,![]() 为输入实例(特征向量),n为特征个数,
为输入实例(特征向量),n为特征个数,![]() 为类标记,
为类标记,![]() ,N 为样本容量。学习模型的目标是根据给定的训练数据集构建一个决策树模型,使它能够对实例进行正确的分类
,N 为样本容量。学习模型的目标是根据给定的训练数据集构建一个决策树模型,使它能够对实例进行正确的分类
2. 基于决策树模型进行分类预测
用决策树分类,从根节点开始,对实例的某一特征维度进行测试,根据测试结果将实例分配到其子节点;
这时,每一个子节点对应着该特征维度的一个取值(分类结果范围);
如此递归地对实例进行测试和分配,直至达到叶节点;
最后将实例分到叶节点的类中,完成预测的过程
Relevant Link:
https://technet.microsoft.com/zh-cn/library/cc645758(v=sql.105).aspx http://www.jianshu.com/p/3997745880d4
3. 决策树学习策略
我们知道,机器学习一般由模型、策略、算法组成,这一章节我们来讨论下决策树的学习策略。学习策略的目标是通过一个可收敛函数将模型原本的最优求解难题转化为一个数学上可解的方程式求解问题
决策树学习本质上是从训练数据集中归纳出一组分类规则,与训练数据集拟合的决策树可能有多个,也可能一个都没有(当数据集中完全无规律时决策树也无法建树)。我们需要的是一个与训练数据集拟合程度较好,同时具有很好的泛化能力的模型
0x1:结构化风险最小
决策树学习用损失函数来表达对训练数据的拟合以及泛化能力的目标,所以,决策树学习的损失函数通常是正则化的极大似然估计。
决策树学习的策略是以损失函数为目标函数的最小化,这对应于结构风险最小策略。
但是要明白的是,即使对于结点数量固定的树,确定最优结构(包括每次划分使用的输入变量以及对应的阈值)来最小化平方和误差函数的问题通常在计算上不可行的,因为可能的组合数量相当巨大,在这种情况求偏导极值计算量十分庞大。
所以,大多数时候:决策树无法一步到位得到整个模型的结构!我们通常使用贪心的最优化算法
0x2:次最优启发策略
当损失函数确定以后,学习问题就变为在损失函数意义下选择最优决策树的问题,因为从所有可能的决策树中选取最优决策树是NP完全问题(搜索空间过于庞大),所有现实中的决策树学习通常采用启发式方法,通过逐步逼近的思想,近似求解这一最优化问题。这样得到的决策树是次最优(sub-optimal)的
0x3:结构化风险和次最优启发策略在建树过程中的体现
决策树学习的算法通常是一个递归地选择最优特征,并根据该特征对训练数据进行分割,使得对各个子数据集有一个最好(局部最好)的分类的过程 。这一过程对应着对特征空间的一次次划分,也对应着决策树的构建
1. 开始,构建根节点,将所有训练数据都放在根节点 2. 选择一个最优特征,选择的标准是信息增益(比)最大或基尼指数最小,即选择能让分类后的样本纯度最大的特征维度。按照这一特征将训练数据集分隔成子集,使得各子集有一个在当前条件下最好的分类 3. 如果这些子集已经能够被基本正确分类,那么构建叶节点,并将这些子集分到所对应的叶节点中去; 4. 如果还有子集不能被"基本正确"分类(纯度还不高),那么就对这些子集继续选择新的最优特征(局部最优),继续对其进行分割,构建相应的节点 5. 如此递归地进行下去,直至所有训练数据子集被基本正确分类,或者没有合适的特征为止 6. 最后每个子集都被分到叶节点上,即都有了明确的类,这就生成了一棵决策树
以上方法生成的决策树可能对训练数据有很好的分类能力,但对未知的测试数据却未必有很好的分类能力,即可能发生过拟合现象。根据结构化风险最小策略思想,我们需要对已生成的树自上而下进行剪枝,将树变得更简单(奥卡姆剃刀原则),从而使它具有更好的泛化能力
从贝叶斯后验概率的角度来看,决策树学习是由训练数据集估计后验条件概率模型。基于特征空间划分的类的条件概率模型有无穷多个(当然最大似然后验概率只有一个)。我们选择的条件概率模型应该不仅对训练数据有很好的拟合而且对未知数据有很好的预测
Relevant Link:
http://scikit-learn.org/stable/modules/tree.html http://www.cnblogs.com/yonghao/p/5061873.html http://www.cnblogs.com/leoo2sk/archive/2010/09/19/decision-tree.html http://blog.csdn.net/nieson2012/article/details/51314873 http://www.cnblogs.com/bourneli/archive/2013/03/15/2961568.html
4. 决策树建树算法 - 对训练样本尽可能地拟合以符合经验风险最小策略
0x1:特征选择
特征选择可谓决策树建树过程中非常核心关键的一部分,为什么这么说?
我们知道,感知机的分界面寻找过程基于的梯度下降算法、KNN分类过程寻找最大后验概率类算法,其本质都符合经验风险最小策略,即尽可能地去拟合已知的观测样本。到了决策树这里,情况依然没有改变,同时决策树是沿着特征不断地进行二叉切分,向下生长的树形结构,经验风险策略的体现就通过来特征选择来实现。为什么这么说?我这里谈一些我个人的理解:
1. 经验风险的定义是:模型关于训练数据集的平均损失称为经验风险(empirical risk);
2. 同时决策树中特征选择的核心思想是"最大熵减",即每次选的特征要让当前剩余样本集的熵减少幅度最大,换句话说即每次选的特征要让当前剩余样本被误分类的个数减少幅度最大;
3. 所以决策树每次特征选择对应的损失都是局部最优的,对于全局整体来说,也是逼近全局最优的,即符合经验风险最小原则
但是经验风险最小化毕竟只是一个思想,在决策树算法中有更加明确严格地对特征选择原则的定义,那就是信息增益或信息增益比
信息增益的目的是为了更好地量化该如何评判不同特征对建模效果的共享,而我们知道:
如果利用一个特征进行分类的结果与随机分类的结果没有很大差别,则称这个特征是没有分类能力的,扔掉这样的特征对决策树学习的精确度影响不大
对于这个问题,我们可以用于生活上的例子来帮助理解:如果我们要从一群人里分类出打篮球打的好的同学,我们手上现在有几个特征:年龄、性别、身高、体重、语文课成绩。其中语文课成绩这个特征维度中,打篮球好的和打篮球坏的同学数量基本相同,即这个特征维度下基本不包含有用的分类规律(就算知道了这个特征的分布也不能对我们的判断起多大的帮助),所以直观上这个特征是可以丢弃的
这是直观上的感觉,下面我们用信息增益(比)和基尼指数来定量描述一个特征的"可分类性"
1. 信息增益
信息增益的概念建立在熵与条件熵的基础概念之上
1. 随机变量的熵
在信息论与概率统计中,熵(entropy)是表示随机变量不确定性的度量。设X是一个取有限个值的离散随机变量,其概率分布为:![]()
则随机变量X的熵定义为:![]() 。由定义可知,熵只依赖于X的分布结构,而与X的具体取值无关,所以也可以将X的熵记作H(P),即:
。由定义可知,熵只依赖于X的分布结构,而与X的具体取值无关,所以也可以将X的熵记作H(P),即:![]()
熵值随着随机变量的不确定的增加而单调增大,从定义可验证
![]()
当随机变量符合伯努利分布(只取两个值,例如0,1)时,X的分布为:![]()
熵为:![]()
这时,熵H(p)随概率p变化的曲线如下图所示
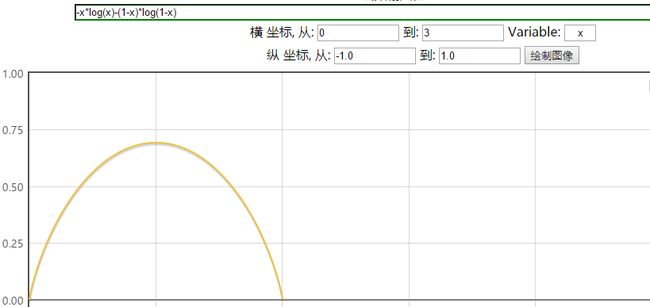
可以看到,X的概率分布越接近于0.5(随机分布),则随机变量的不确定性越大,熵越大。熵的极值是log2
2. 条件随机变量的熵
设有随机变量(X, Y),其联合概率分布为:![]()
条件熵H(Y|X)表示在已知随机变量X的条件下随机变量Y的不确定性。随机变量X给定的条件下随机变量Y的条件熵(conditional entropy)。H(Y|X)定义为在给定X的条件下,Y的条件概率分布的熵对X的数序期望
![]()
当熵和条件熵中的概率由观察样本数据估计(特别是极大似然估计)得到时,所对应的熵与条件熵分别称为经验熵(empirical entropy)和经验条件熵(empirical conditional entropy)
3. 信息增益定义
对熵和条件熵有所了解后我们来继续讨论信息增益。信息增益(information gain)表示获得特征X的信息之后使得类Y的信息的不确定性减少的程度,即我们能从特征中得到多少有效信息。特征A对训练数据集D的信息增益g(D, A),定义为集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差,即:![]()
一般地,熵![]() 与条件熵
与条件熵![]() 之差称为互信息(mutual information)。决策树中的信息熵等价于训练数据集中类与特征的互信息
之差称为互信息(mutual information)。决策树中的信息熵等价于训练数据集中类与特征的互信息
显然,对于数据集D而言,信息增益依赖于特征的选取,不同的特征往往具有不同的信息增益。
信息增益大的特征具有更强的分类能力,同时获得更好的经验风险
4. 信息增益的算法
设训练数据集为D,| D | 表示其样本容量,即样本个数。设有K个类Ck,k=1,2,3...K。| Ck | 为属于类Ck的样本个数,![]() 。设特征A有n个不同的取值{a1, a2, ...,an},根据特征A的取值将D划分为n个子集D1,D2,,..,Dn,| Dt | 为Dt的样本个数,
。设特征A有n个不同的取值{a1, a2, ...,an},根据特征A的取值将D划分为n个子集D1,D2,,..,Dn,| Dt | 为Dt的样本个数,![]() ,记子集Di中属于类Ck的样本集合为Dik,即:
,记子集Di中属于类Ck的样本集合为Dik,即:![]() ,| Dik | 为Dik的样本个数。信息增益算法公式如下
,| Dik | 为Dik的样本个数。信息增益算法公式如下
1. 计算数据集D的经验熵H(D):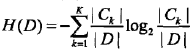
2. 计算特征A对数据集D的经验条件熵H(D|A):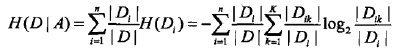
3. 计算信息增益:![]()
下面举一个具体的里来说明如何用信息增益来选择一次特征选择中的局部最佳特征
样本数:15 样本类别 K = 2:是;否 特征维度(属性): 1)年龄:青年;中年;老年 2)有工作:是;否 3)有自己的房子:是;否 4)信贷情况:一般;好;非常好

首先计算经验熵H(D)
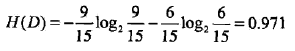 :9个样本分类是"是",6个样本的分类是"否"。经验熵H(D)代表的是未根绝特征分类前当前样本的不确定度
:9个样本分类是"是",6个样本的分类是"否"。经验熵H(D)代表的是未根绝特征分类前当前样本的不确定度
然后确定各特征对数据集D的信息增益,分别用A1、A2、A3、A4表示年龄、有工作、有自己的房子、信贷情况这4个特征
特征A将数据分为3类,每类都是5个,所以| Di | / | D | = 5/15。然后再计算被特征A分类后的类和样本label类的交集
1)g(D,A1) = H(D) - 【5/15 * H(D1) + 5/15 * H(D2) + 5/15 * H(D3)】 = 0.971 - 【5/15 * ( -2/5 * log2/5 - 3/5 * log3/5) + 5/15 * ( -2/5 * log2/5 - 3/5 * log3/5) + 5/15 * (-4/5 * log4/5 - 1/5 * log1/5) 】= 0.971 - 0.888 - 0.083 - 年龄在青年、中年、老年的子集中的经验条件熵
2)g(D,A2) = H(D) - 【5/15 * H(D1) + 10/15 * H(D2) 】 = 0.971 - 【5/15 * 0 + 10/15 * ( -4/10 * log4/10 - 6/10 * log6/10) 】= 0.324
3)g(D,A3) = H(D) - 【6/15 * H(D1) + 9/15 * H(D2) 】 = 0.971 - 【6/15 * 0 + 9/15 * ( -3/9 * log3/9 - 6/9 * log6/9) 】= 0.971 - 0.551 = 0.420
4)g(D,A4) = 0.971 - 0.608 = 0.363
比较各特征的信息增益值,由于特征A3(有自己的房子)的信息增益值最大,所以选择特征A3作为本轮特征选择的最优特征
5. 基于信息增益的特征选择
根据信息增益准则的特征选择方法是:对训练数据集(或子集)D,计算其所有每个特征的信息增益,并比较它们的大小,选择信息增益最大的特征
2. 信息增益比
信息增益值的大小是相对于训练数据集而言的,容易受到训练数据集的经验熵的影响而变大变小。使用信息增益比(information gain ratio)可以对这一问题进行校正,相当于根据数据集的经验熵进行归一化。
特征A对训练数据集D的信息增益比![]() 定义为其信息增益g(D,A)与训练数据集D的经验熵H(D)之比:
定义为其信息增益g(D,A)与训练数据集D的经验熵H(D)之比:![]()
3. 基尼指数
基尼指数和信息熵本质是一样的,都是用于描述数据集混乱度的一种数学度量。在分类问题中,假设有K个类,样本点属于第k类的概率是Pk,则概率分布的基尼指数定义为: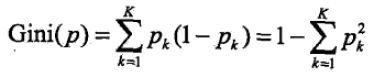
对于二分类问题,若样本点属于第一个类的概率是p,则概率分布的基尼指数为:![]()
对于给定的样本集合D,其基尼指数为: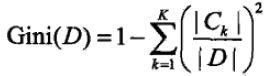 ,这里Ck是D中属于第k类的样本子集,K是类的个数。注意因为实际概率我们不知道,只能用样本分布来估计概率p
,这里Ck是D中属于第k类的样本子集,K是类的个数。注意因为实际概率我们不知道,只能用样本分布来估计概率p
1. 基于基尼指数来评估分类特征的效果
信息增益用分类前后的概率分布的熵差值来体现分类的效果,基尼指数的核心思想也是类似的,基尼指数反映了样本集的不确定性,基尼指数越大,样本的不确定性就越大
如果样本集合D根据特征A是否取某个可能的值a被分隔成D1和D2两部分,即:![]() ,则在特征A的条件下,集合D的基尼指数定义为:
,则在特征A的条件下,集合D的基尼指数定义为:
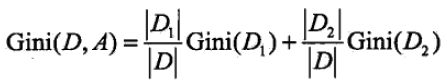 ,基尼指数Gini(D)表示集合D的不确定性,基尼指数Gini(D, A)表示经A=a分隔后集合D的不确定性。和信息增益一样,基尼指数本质上也是在评估分类后的样本纯度
,基尼指数Gini(D)表示集合D的不确定性,基尼指数Gini(D, A)表示经A=a分隔后集合D的不确定性。和信息增益一样,基尼指数本质上也是在评估分类后的样本纯度
下图显示了二类分类问题中基尼指数Gini(p)、1/2 * 熵(单位比特)、分类误差率的曲线关系
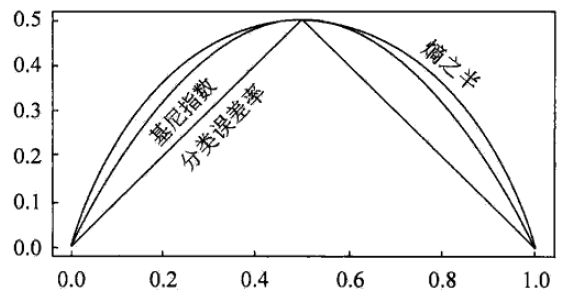
可以看出基尼指数和熵之半的曲线和接近,都可以近似地代表分类误差率
Relevant Link:
http://zh.numberempire.com/graphingcalculator.php?functions=log%281-x%29%2C1%2F%28x-1%29
0x2:决策树建树具体算法 - 工程化应用
上面讨论的特征选择更多地是体现决策建树的策略性指导原则,而在具体工程化领域应用这一原则构建决策树需要有具体的算法
决策树学习的常用算法有ID3、C4.5和CART,这3个算法包括了特征选择、建树训练、剪枝过程(我们后面会讨论),我们接下来分别讨论每种算法的主要思想以及演进情况
1. ID3算法
ID3算法的核心是在决策树各个结点上应用信息增益准则选择特征,递归地构建决策树T
1. 若当天结点中的D所有实例都属于同一类Ck,则T为单节点树(这是建树停止的强条件),并将类Ck作为该节点的类标记。返回T 2. 若当前可选取的特征A为空(即无特征可选),则T为单节点树,并将D中实例数最大的类Ck作为该结点的类标记(有可能纯度未达到100%),返回T 3. 否则,从当前D中计算所有特征的信息增益,选择信息增益最大的特征Ag,如果Ag对应的信息增益小于收敛阈值(类似于损失函数减少量阈值,用于提前终止,快速收敛),则设置T为单节点树,并将当前D中实例数量最大的类Ck作为该结点类标记,返回T 4. 否则,对Ag的每一可能取值ai,依照Ag = ai将D分割成若干非空子集Di,将Di中实例数最大的类作为标记,构建子结点,由结点及其子节点沟通树T,返回T 5. 对第i个子结点,已Di为训练集,以A-{Ag}为特征集(在剩下来的特征中继续寻找最优),递归地调用1~4步。得到子树Ti,返回Ti
ID3相当于用极大似然法进行概率模型的选择
回到上面"贷款申请样本表"的例子中,使用ID3来生成决策树
1. 由于特征A3(有自己的房子)的信息增益最大,所以选择特征A3作为根节点的特征。它将训练数据集D划分为两个子集D1(A3取值为"是")和D2(A3取值为"否") 2. 由于D1只有同一类label的样本(即纯度已经100%),即"有自己房子"的样本的label都是能够予以放款。所以D1成为一个叶节点,结点的类标记为"是" 3. 对D2则需要从特征A1(年龄)、A2(有工作)和A4(信贷情况)中选择新的特征,计算各个特征的信息增益 g(D2,A1) = H(D2) - H(D2 | A1) = -3/9 * log3/9 - 6/9 * log6/9 - H(D2 | A1) = 0.918 - H(D2 | A1)= 0.918 -【4/9* H(D21) + 2/9 * H(D22) + 3/9 * H(D23)】 = 0.918 - 【4/9 * ( -3/4 * log3/4 - 1/4 * log1/4) + 2/9 * 0 + 3/9 * (-2/3 * log2/3 - 1/3 * log1/3) 】= 0.918 - 0.667 = 0.251 g(D2,A2) = H(D2) - H(D2 | A2) = 0.918 g(D2,A4) = H(D2) - H(D2 | A4) = 0.474 # 可以看到,在条件概率对应的特征Ag下,如果依据该特征进行分类后,不管label是哪一类,只要纯度最高,则对应的信息增益就是最高的,信息增益关注的是分类后的纯度 4. 选择信息增益最大的A2(有工作)作为结点的特征 5. 由于A2有两个可能的取值: 1)一个对应"是"(有工作)的子结点,包含3个样本,它们属于同一类,所以这就是一个叶节点,标记为"是"; 2)另一个是对应"否"(无工作)的子节点,包含6个样本,它们也属于同一类,所以这也是一个叶节点,类标记为"否" 6. 由于到了这一步后,所以子节点的纯度都已经到100%,因此建树过程结束
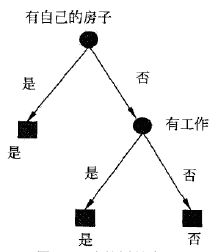
需要注意的是,ID3算法只有树的生成,所以该算法生成的树容易产生过拟合
2. C4.5算法
C4.5算法与ID3的建树过程相似,所区别的是,C4.5对特征选择进行优化,采用了信息增益比来选择特征
3. CART算法
分类与回归树(classification and regression tree CART)模型是一种广泛应用的决策树学习算法。它同样由特征选择、树的生成以及剪枝组成,既可以用于分类也可以用于回归
CART是在给定输入随机变量X条件下输出随机变量Y的条件概率分布的学习方法,和ID3和C4.5不同的是(ID3和C4.5可以支持多叉树),CART假设决策树是二叉树,内部结点特征的取值永远为"是"和"否"
1. 左分支是取值为"是"的分支 2. 右分支有取值为"否"的分支
这样的决策树等价于递归地二分每个特征,将输入空间即特征空间递归地划分为2的指数倍个单元,并在这些单元上根据训练数据推测出条件概率分布
1. 回归树的生成
决策树的生成就是递归地构建二叉决策树的过程,对回归树用平方误差最小化策略(回归问题)
回归问题和分类问题不同,回归问题本质上一个拟合问题,回归树的建立和分类数建立有几个最大的不同
1. 分类树对特征空间的划分是针对离散的特征(例如年龄、收入、工作等)进行的,而回归树的特征数量往往是一个连续区间(例如【0,10.5】),回归树是将特征空间"采样化"成m个数量的区域Rm,只要落在这个区域内的特征,不管其值如何,都统一归一化为同一个特征值 2. 分类树的输入样本在一个特征中的特征值是离散有限的,但是回归树的输入样本在一个特征中的特征值是连续无限的,所以回归树这里最重要的"采样思想",在每个特征单元Rm上有一个固定的输出值Cm,本质上就是用线性分类器在对连续变量进行离散的拟合
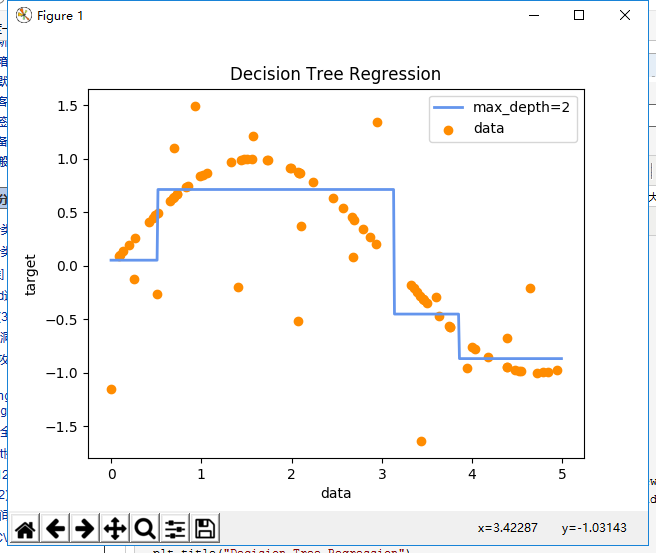
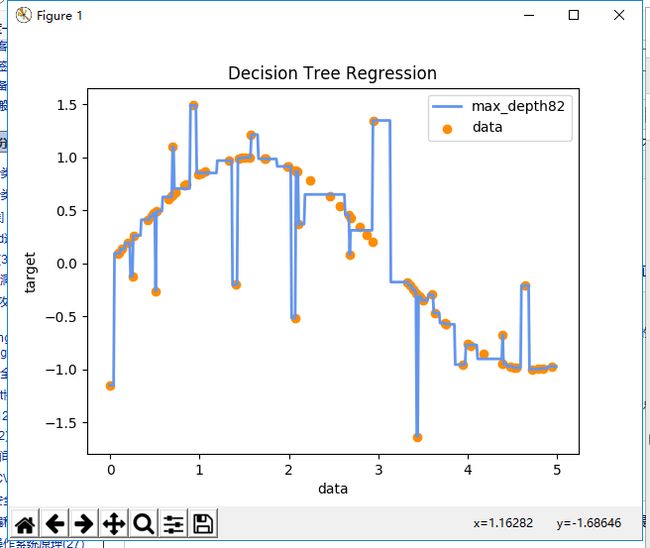
用skilearn官方的例子来说明回归树(depth = 2)的非线性数据拟合问题
# -*- coding: utf-8 -*- # Import the necessary modules and libraries import numpy as np from sklearn.tree import DecisionTreeRegressor import matplotlib.pyplot as plt import pydotplus from sklearn import tree # Create a random dataset rng = np.random.RandomState(1) X = np.sort(5 * rng.rand(80, 1), axis=0) y = np.sin(X).ravel() y[::5] += 3 * (0.5 - rng.rand(16)) # Fit regression model regr_1 = DecisionTreeRegressor(max_depth=2) regr_2 = DecisionTreeRegressor(max_depth=5) print X print y regr_1.fit(X, y) regr_2.fit(X, y) # Predict X_test = np.arange(0.0, 5.0, 0.01)[:, np.newaxis] y_1 = regr_1.predict(X_test) y_2 = regr_2.predict(X_test) # generate a PDF file ''' dot_data = tree.export_graphviz(regr_1, out_file=None) graph = pydotplus.graph_from_dot_data(dot_data) graph.write_pdf("dt_2.pdf") dot_data = tree.export_graphviz(regr_2, out_file=None) graph = pydotplus.graph_from_dot_data(dot_data) graph.write_pdf("dt_5.pdf") ''' # Plot the results plt.figure() plt.scatter(X, y, c="darkorange", label="data") plt.plot(X_test, y_1, color="cornflowerblue", label="max_depth=2", linewidth=2) #plt.plot(X_test, y_2, color="yellowgreen", label="max_depth=5", linewidth=2) plt.xlabel("data") plt.ylabel("target") plt.title("Decision Tree Regression") plt.legend() plt.show()
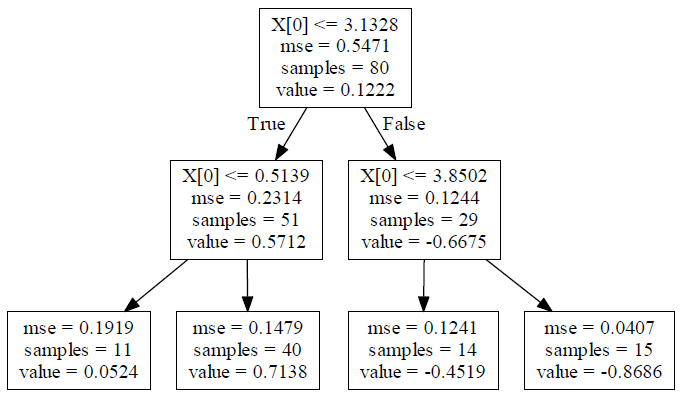
打印出模型参数
我们先用不太严谨粗糙的语言描述整个建树和预测过程,以期对决策回归树有一个直观的理解,之后再详细讨论它的算法过程公式
1. 该样本总共有80个,特征为X坐标,特征值为Y坐标,这样很利于我们画图可视化和理解 2. 回归树遍历所有特征,尝试将每个特征作为切分变量,并计算在该切分点下,两边区间Rm的最小平方误差Cm(Cm是一定可以算出来的) 3. 在第一轮选择中,回归树最终选择了3.1328这个点,这时候 1)左区间的最优输出值(即采样值)(其实就是均值)是0.5712 2)右区间的最优输出值是-0.6675 4. 由于我们指定了树深度为2,所以回归树继续递归地在第一轮分出的子区间中寻找最优切分点 1)这一次在左区间找到了0.5139 2)在右区间找到了3.8502 5. 根据新的切分点将左右子区间再次切分成子区间,这样就有4个区间了:R1【0: 0.5139】;R2【0.5139: 3.1328】;R3【3.1328: 3.8502】;R4【3.8502: 5】,这4个区间的输出值就是这4个区间的样本均值: Cm1 = 0.0524;Cm2 = 0.7138;Cm1 = -0.4519;Cm1 = -0.8686;
可以看到,随着depth深度的增大,回归树会逐渐从采样分类问题演进为曲线拟合问题,但depth的增加也会加剧过拟合的产生。即回归树对训练数据拟合的很精确,但是泛化能力会下降
接下来用公式化描述回归树建树过程
一个回归树对应着输入空间(即特征空间)的一个划分以及在划分的单元上的输出值(在连续值中取离散值)。假设已将输入空间分化为M个单元R1,...Rm,并且在每个单元Rm上有一个固定的输出值Cm,于是回归树模型可以表示为: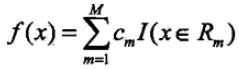 。当输入空间的划分确定时,可以用平方误差
。当输入空间的划分确定时,可以用平方误差 来表示回归树对于训练数据的预测误差,用平方误差误差最小的准则求解每个单元上的最优输出值。根据高斯正态分布可知,单元Rm上的Cm的最优值
来表示回归树对于训练数据的预测误差,用平方误差误差最小的准则求解每个单元上的最优输出值。根据高斯正态分布可知,单元Rm上的Cm的最优值![]() 是Rm上所有输入实例Xi对应的输出Yi的均值,即:
是Rm上所有输入实例Xi对应的输出Yi的均值,即:![]() 。得到了Cm,我们就可以计算在一个特定切分变量情况下,左右子区间的最小平方误差了
。得到了Cm,我们就可以计算在一个特定切分变量情况下,左右子区间的最小平方误差了
1. CART采取启发式的方法,遍历当前所有特征中选择第 j 个变量(特征)![]() 作为切分变量,切分变量确定后,特征就被切分成了左右子区域:
作为切分变量,切分变量确定后,特征就被切分成了左右子区域:![]()
2. 在一轮特(切分变量)征选择中有很多选择,我们通过下面公式,得到最优的切分变量以及它的切分点(切分点就是区域内的特征均值):
3. 用选定的(切分变量 j,切分点 s)划分区域并决定相应的输出值: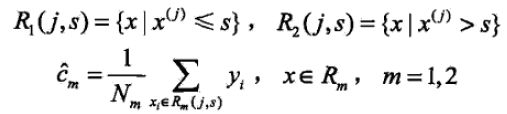
4. 继续递归地对左右子区间进行2~3步骤,直至满足终止条件
5. 将输入特征空间划分为M个区域R1...Rm,生成决策树: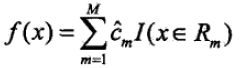 。决策时是针对特征进行预测
。决策时是针对特征进行预测
2. 分类树的生成
对分类树(分类问题)用基尼指数(Gini Index)最小化策略,进行特征选择,生成二叉树
分类树用基尼指数(类似与信息增益的思想)选择最优特征,同时决定该特征的最优二值切分点。根据训练数据集,从根节点开始,递归地建树
1. 设结点的训练数据集为D,计算现有特征对该数据集的基尼指数。遍历所有特征,计算每个特征分类后的条件基尼指数 2. 在所有可能的特征A以及它们所有可能的切分点a中,选择基尼指数最小的特征及其切分点(均值)作为最优特征和最优切分点。将训练集分配到这两个子节点中 3. 对两个子节点递归地调用1、2过程,直至满足条件。(结点中的样本个数小于阈值、或样本集的基尼指数小于阈值)、或者没有更多特征 4. 生成CART决策树
CART建树为了实现二分类,不仅要评估切分变量(特征),还在要特征的可能取值中选出一个最佳切分点用于二分类(压缩),还是用之前的放贷的数据集作为例子,约定数学代号
A1:年龄 1:青年 2:中年 3. 老年 A2:有工作 1. 有工作 2. 无工作 A3:有自己的房子 1. 有房子 2. 无房子 A4:信贷情况 1. 非常好 2. 好 3. 一般
求特征A1的基尼指数,遍历所有可能值作为切分点
Gini(D,A1 = 1) = 5/15 * (2 * 2/5 * (1 - 2/5)) + 10/15 * (2 * 7/10 * (1 - 7/10)) = 0.44
Gini(D,A1 = 2) = 5/15 * (2 * 3/5 * (1 - 3/5)) + 10/15 * (2 * 6/10 * (1 - 6/10)) = 0.48
Gini(D,A1 = 3) = 5/15 * (2 * 4/5 * (1 - 4/5)) + 10/15 * (2 * 5/10 * (1 - 5/10)) = 0.44
由于Gini(D,A1 = 1)和Gini(D,A1 = 3)相等,且最小,所以A1=1、A1=3都可以选作A1的最优切分点,注意这时候还不确定是否A1就是本轮的最优切分变量
求特征A2、A3的基尼指数,遍历所有可能值作为切分点
Gini(D,A2 = 1) = 0.32
Gini(D,A3 = 1) = 0.27
由于A2、A3内都只有两个特征值,无论选谁作为切分点都是一样的,因此不需要选择
求特征A4的基尼指数,遍历所有可能值作为切分点
Gini(D,A4 = 1) = 0.36
Gini(D,A4 = 2) = 0.47
Gini(D,A4 = 3) = 0.32
Gini(D,A4 = 3) = 0.32最小,所以A4 = 3作为A4的最优切分点
总体比较所有(切分变量,切分点)对,Gini(D,A3 = 1) = 0.27最小,所以特征A3(是否有自己房子)为最优特征,A3=1为最优切分点(即有自己房子)。于是根节点生成2个子结点,一个是叶节点(A3已不可再分),另一个作为新的数据集继续用以上方法寻找最佳切分变量和切分点
Relevant Link:
https://cethik.vip/2016/09/21/machineCAST/
5. 决策树剪枝算法 - 在样本拟合和模型复杂度间动态平很以符合结构风险最小策略
所有的机器学习模型都要遵循一个原则:"Be Simple",在深度神经网络中的正则化项、DropOut;贝叶斯概率模型中的经验风险和结构风险(复杂度惩罚项);还是到决策树中的剪枝都体现了这种策略思想,在相同的分类效果下,越简单的模型往往具备越好的泛化能力
决策树生成算法递归地产生决策树,直到不能继续下去为止(没有可选特征、信息增益小于阈值、子集中纯度达到100%)。这样产生的树往往对训练数据的分类很准确,但是对未知的测试数据却效果没那么好,即出现过拟合现象。回想上面的贷款例子,在第二轮选择A2特征(有工作)作为分类特征时,如果被分出来的子集中类label的纯度不是如题的100%,而是包含了一些噪音数据,则决策树还会继续递归下去,但也许这些噪音数据并不代表该分类问题真实的规律,这样建出来的树在之后的predict中对包含这部分噪音特征范围的样本就会预测失败,决策树的过分细分导致出现过拟合现象
0x1: 对噪音数据过于敏感导致过拟合
在讨论剪枝之前,我们先来探讨下决策树在建树过程中,对噪音数据处理能力较差的问题,决策树的建树过程有点像物尽其类,如果不设置MAX Depth或者最小叶子数,决策树会不断递归地去把样本中的所有样本都分到对应的label类中
下面我们通过一个逐步加深决策树深度的例子来说明决策树建树过程中的过拟合现象,基于bag of word onehot模型对标记了"好/坏"倾向性的评论语料集进行训练,例如下面的句子,句首的数字代表了label
1 originally launched in 1978 , this popular film was re-introduced in 1998 to a whole new generation of moviegoers . based on the mighty successful musical from broadway , grease was followed in 1980 with the less stellar grease 2 ( 6 . 5/10 ) , starring a young michelle pheiffer in one of her first feature film roles . plot : high-school musical set in the 1950's showcasing the relationship between the cool danny zuko of the t-birds ( travolta ) and the innocent and pure sandy olsen ( newton-john ) from australia . the film follows the couple and their vivacious friends during their last year at rydell high through song , dance and humour . critique : fun-loving , energetic and innocent look back at times much simpler . this movie effectively juggles a thin romantic story line and the overall experience of the 1950's , with a superb soundtrack and some great dance numbers . admittedly , i am somewhat biased in this opinion , since this film blasts me into my past as a rebellious youth ( grease was one of schmoe's first big-screen experiences , and every other scene sends me reeling into the times of my elaborate grease bubble-gum card collection ) , and the lesser responsibilities that i possessed at that time . but apart from the nostalgic vibe , i was still extremely impressed by this film , as it continued to amuse me , despite my previous dozen or so viewings . this film took john travolta from a dim-witted " sweathog " on tv's welcome back kotter , and transformed him into a movie-star of spectacular proportions ( saturday night fever ( 7 . 5/10 ) in 1979 confirmed that sudden popularity ) . unfortunately for the rest of the cast , his popularity was not terribly contagious , despite their effective showings in this classic movie . on the down side , some of the absolute innocence in this film might bore or turn people off ( like when sandy sings about " drinking lemonade " and " staying out until 10 " with danny in " summer nights " ) , and the plot isn't exactly the most elaborate story-line ever created , but despite these small reservations , this movie carries enough great music and high energy to keep anyone amused through its rapid 110 minute running time ( and believe me . . . i am not a fan of the musicals ! ! ) . make sure to look for a young lorenzo lamas in the static role of the brainless football player , as well as the national bandstand dance contest as one of the film's absolute highlights . and don't forget to buy the popular soundtrack afterwards , so that you could listen to its peppy tunes whenever you're feeling a little blue . little known facts : henry winkler , of tv's happy days' fonzie fame , turned down the part of danny zuko because he did not want to be typecast for the rest of his career . both travolta and conaway were smitten by newton-john during the filming of this picture . conaway eventually bowed out of the woo-fest , and married newton-john's sister a year later ( divorced after five years ) .
0 confucius once said , " governing a nation is like cooking a small fish -- don't overdo it . " his maxim might be easily applied to writing a comedy script , for quantity over quality is one of the worst mistakes an amateur scribe can make . granted , mike judge , writer-director of the workplace satire office space isn't exactly an amateur ( his most infamous work , the mtv series " beavis and butt-head " was pure gold for its network ) . but unfailingly , judge manages to make some rather inexcusable mistakes in office space by spreading an iffy plot over too much ground . the iffiness in judge's plot -- a group of coworkers plan the downfall of their despicable boss -- is not in its appeal . in fact , based on the popularity of scott adams' cartoon " dilbert , " which will soon have its own television series , a satirical view of the american workplace is a hot item in hollywood . unfortunately the concept lends itself to skit-length sequences which would be more at home on the set of " saturday night live " rather than a full-length feature . the most convincing evidence of this are the trailers for office space , which feature almost all of the movie's top content ; this leaves the actual picture appearing very deflated . other evidence of office space's failure to work are its lack of good jokes . the comedy is marginally funny at best , but not enough to get a packed house of theater-goers to laugh out loud . the material in the movie is on-key for an older demographic than judge is used to targeting , and this could partially explain his work here . however , the movie is loaded with too many misfires -- including the token plot -- to allow for any excuse . the plot centers around three or four cubicled engineers , headed up by peter gibbons ( ron livingston ) , at a company named initech . after the movie elaborately establishes the miserable working conditions at initech , the movie introduces us to two consultants ( john c . mcginley and paul willson ) which are in charge of " downsizing " the company's payroll . when peter and his gang learns of this , as well as the reason behind it -- so their smooth talking boss bill lumbergh ( gary cole ) 's stock will go up -- they set about creating a plan to see his downfall . the circumstances that follow were obviously intended to be hilarious but they come out as anything but . a sympathetic cast and a muddled jennifer aniston-as-love-interest subplot are all that keep this one together , but it's definitely missable in lieu of something more intelligent .
向量化后得到一个3473维度的定长vector
1. depth = 1
bad? -N-> class 1 (333 for class 0, 533 for class 1) -Y-> class 0 (358 for class 0, 176 for class 1)
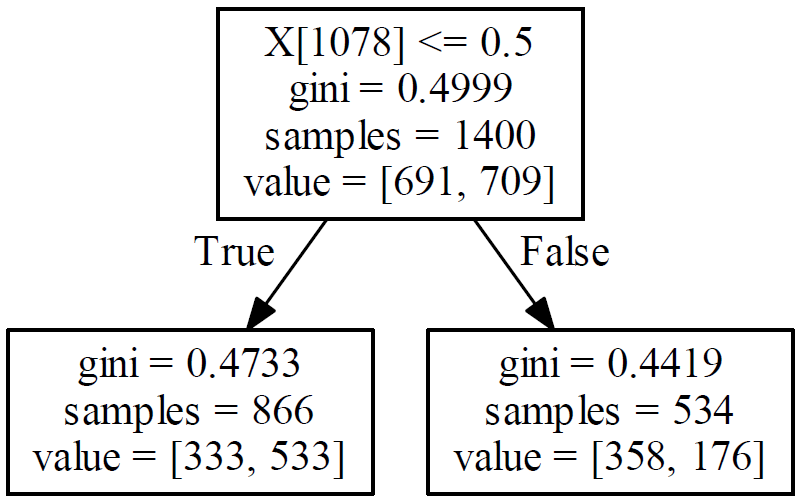
上图表明,决策树通过信息增益或者基尼指数计算得到1078维度的特征的分类能力最强,即根据"bad"这个词进行二分类
1. 被分到True类(class = 1)的866个样本中 1) 533的label class = 1 2) 333的label class = 0:看起来还有很多样本虽然在这个维度分类点有相同的区间范围,但是一定还在其他维度有不同的表现,似乎还应该继续分下去 2. 被分到False类(class = 0)的534个样本中 1) 358的label class = 0 2) 176的label class = 1
分别查看当前模型对训练集、验证机、和测试集的准确度
# Accuracy of training set print np.mean(dt.predict(X_tr) == Y_tr) 0.636428571429 # Accuracy of dev set print np.mean(dt.predict(X_de) == Y_de) 0.605 # Accuracy of test set print np.mean(dt.predict(X_te) == Y_te) 0.595
可以当前模型对训练数据的准确度为63%(但是注意是训练集,对训练集的准确度并不能说明泛化能力,对训练集的准确度只能说明模型对训练数据的拟合程度)
2. depth = 2
我么看到,仅在深度为1的情况下,决策树的分类还不够彻底,每一类中还有很多类明显和该类不兼容(纯度还不够),应该还可以再分,我们把深度提高到2
bad? -N-> worst? | -N-> class 1 (281 for class 0, 514 for class 1) | -Y-> class 0 (52 for class 0, 19 for class 1) -Y-> stupid? | -N-> class 0 (281 for class 0, 168 for class 1) | -Y-> class 0 (77 for class 0, 8 for class 1) 0.66 0.62 0.615
这一次,所有集合中的准确度都有所提高
3. depth = 3
bad? -N-> worst? | -N-> many? | | -N-> class 1 (204 for class 0, 274 for class 1) | | -Y-> class 1 (77 for class 0, 240 for class 1) | -Y-> present? | | -N-> class 0 (52 for class 0, 13 for class 1) | | -Y-> class 1 (0 for class 0, 6 for class 1) -Y-> stupid? | -N-> wonderfully? | | -N-> class 0 (280 for class 0, 153 for class 1) | | -Y-> class 1 (1 for class 0, 15 for class 1) | -Y-> bob? | | -N-> class 0 (76 for class 0, 4 for class 1) | | -Y-> class 1 (1 for class 0, 4 for class 1) 0.676428571429 0.645 0.625
4. depth = 4
bad? -N-> worst? | -N-> many? | | -N-> dull? | | | -N-> class 1 (184 for class 0, 271 for class 1) | | | -Y-> class 0 (20 for class 0, 3 for class 1) | | -Y-> ludicrous? | | | -N-> class 1 (70 for class 0, 240 for class 1) | | | -Y-> class 0 (7 for class 0, 0 for class 1) | -Y-> present? | | -N-> brilliant? | | | -N-> class 0 (52 for class 0, 9 for class 1) | | | -Y-> class 1 (0 for class 0, 4 for class 1) | | -Y-> class 1 (0 for class 0, 6 for class 1) -Y-> stupid? | -N-> wonderfully? | | -N-> life? | | | -N-> class 0 (205 for class 0, 79 for class 1) | | | -Y-> class 0 (75 for class 0, 74 for class 1) | | -Y-> area? | | | -N-> class 1 (0 for class 0, 15 for class 1) | | | -Y-> class 0 (1 for class 0, 0 for class 1) | -Y-> bob? | | -N-> buddy? | | | -N-> class 0 (76 for class 0, 2 for class 1) | | | -Y-> class 1 (0 for class 0, 2 for class 1) | | -Y-> falls? | | | -N-> class 1 (0 for class 0, 4 for class 1) | | | -Y-> class 0 (1 for class 0, 0 for class 1) 0.699285714286 0.645 0.635
5. depth = 5
bad? -N-> worst? | -N-> many? | | -N-> dull? | | | -N-> both? | | | | -N-> class 1 (149 for class 0, 164 for class 1) | | | | -Y-> class 1 (35 for class 0, 107 for class 1) | | | -Y-> terrific? | | | | -N-> class 0 (20 for class 0, 1 for class 1) | | | | -Y-> class 1 (0 for class 0, 2 for class 1) | | -Y-> ludicrous? | | | -N-> awful? | | | | -N-> class 1 (61 for class 0, 236 for class 1) | | | | -Y-> class 0 (9 for class 0, 4 for class 1) | | | -Y-> class 0 (7 for class 0, 0 for class 1) | -Y-> present? | | -N-> brilliant? | | | -N-> approach? | | | | -N-> class 0 (52 for class 0, 6 for class 1) | | | | -Y-> class 1 (0 for class 0, 3 for class 1) | | | -Y-> class 1 (0 for class 0, 4 for class 1) | | -Y-> class 1 (0 for class 0, 6 for class 1) -Y-> stupid? | -N-> wonderfully? | | -N-> life? | | | -N-> plausible? | | | | -N-> class 0 (205 for class 0, 73 for class 1) | | | | -Y-> class 1 (0 for class 0, 6 for class 1) | | | -Y-> else? | | | | -N-> class 1 (54 for class 0, 70 for class 1) | | | | -Y-> class 0 (21 for class 0, 4 for class 1) | | -Y-> political? | | | -N-> class 1 (0 for class 0, 15 for class 1) | | | -Y-> class 0 (1 for class 0, 0 for class 1) | -Y-> bob? | | -N-> meeting? | | | -N-> treats? | | | | -N-> class 0 (75 for class 0, 0 for class 1) | | | | -Y-> class 1 (1 for class 0, 2 for class 1) | | | -Y-> class 1 (0 for class 0, 2 for class 1) | | -Y-> give? | | | -N-> class 1 (0 for class 0, 4 for class 1) | | | -Y-> class 0 (1 for class 0, 0 for class 1) 0.722857142857 0.62 0.6425
可以看到,当深度提高到5的时候,训练准确度继续提高,但是dev和test却出现了小幅下降以及保持持平,这说明开始出现了过拟合的现象,继续往下实验可以发现,从6开始,泛化能力就逐渐走下坡路了,这说明过深的决策树过分地捕获了细节信息,导致将噪音特征作为判断依据,最终导致泛化能力下降
6. depth range(1, 40)
我们打印从depth = 1到depth = 40的train/dev/test的准确度曲线
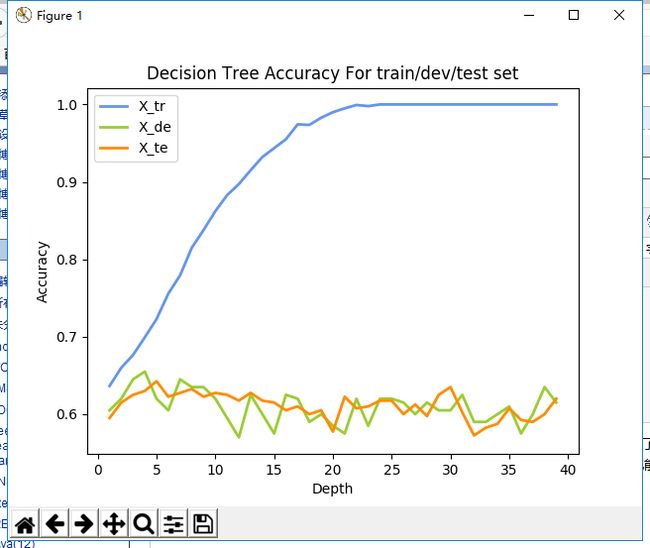
可以看到,在depth = 25的时候,train的准确度到达了极限,很可能是叶子已经不可再分了,而从depth = 5开始,就出现了过拟合现象,之后随着depth的增加,dev和test的准确度都在不断波动
0x2: 缓解过拟合的策略 - 剪枝
过拟合的原因在于学习时过多地考虑如何提高对训练数据的正确分类,从而构建出过于复杂的决策树,解决这一问题的思路是将已生成的树进行简化,即剪枝(pruning)。具体的,剪枝从已生成的树上裁掉一些子树或叶节点,并将其根节点或父节点作为新的叶节点,从而简化分类树模型
剪枝的原理和Dropout是相通的,不过其更本质的目的是降低模型的复杂度
0x3: 剪枝策略
决策树的剪枝往往通过极小化决策树整体的损失函数(loss function)或代价函数(cost function)来实现。
设树T的叶节点个数为|T|,叶节点个数和树复杂程度呈比例上升趋势,t是树T的叶节点,该叶节点有Nt个样本点,其中k类的样本点有Ntk个(每个叶节点可能纯度不一定都100%,所以可能包含K类),Ht(T)为叶节点t上的经验熵,a>=0为参数,则决策树学习的损失函数可以定义为:![]() ,其中经验熵为:
,其中经验熵为: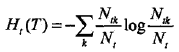
所以损失函数的第一项C(T)可写为: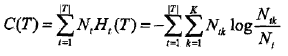
这时有:![]() ,其中
,其中
1. C(T)只由训练数据决定,它反映了模型对训练数据的预测误差,即模型与训练数据的拟合程度 2. | T | 表示模型复杂度(等比于叶节点个数) 3. 参数 a>=0 控制两者之间的平衡 1)较大的a的情况下:| T | 就被迫要尽量小,但是C(T)相对地就会增加,这动态地促使模型选择较简单的模型(浅树) 2)较小的a的情况下:| T | 就被迫要尽量大,C(T)就会相对地减小,促使选择较复杂的模型(深树)
剪枝,就是当a确定时,选择损失函数最小的模型,即损失函数最小的子树。当a值确定时
1. 子树越大,往往与训练数据的拟合越好,但是模型的复杂度就越高 2. 相反子树越小,模型的复杂度就越低,但是往往与训练数据的拟合不好
损失函数动态地调整了对两者的平衡。可以看到,上面定义的损失函数的极小化策略等价于正则化的极大似然估计。所以,利用损失函数最小原则进行剪枝就是用正则化的极大似然估计进行模型选择
注意:上式中的C(T)即对训练数据的预测误差,也可以用基尼指数来评估(CART剪枝),用经验熵来评估就是ID3/C4.5剪枝
0x4: 剪枝过程
1. 计算当前树中每个结点的经验熵
2. 递归地从树的叶节点向上回缩,即将叶节点归并到其父节点中
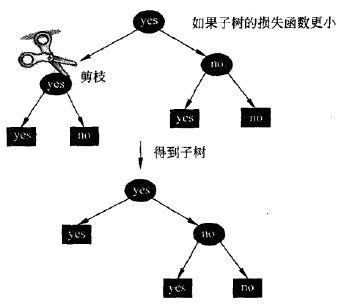
3. 设一组叶节点回缩到其父节点之前与之后的整体树分别为Tb与Ta,其对应的损失函数值分别是:Ca(Tb)与Ca(Ta)。如果:Ca(Ta) <= Ca(Tb)。即损失函数减小了,说明这个剪枝给整棵树带来了正向的帮助,则进行剪枝,即将叶节点归并到父节点中,将父节点作为新的叶节点
4. 递归地进行2~3过程,直至不能继续或者损失函数不再减小为止,最终得到损失函数最小的子树Ta
Relevant Link:
https://github.com/hal3/ciml https://github.com/hal3/ciml/tree/master/labs/lab1-DTs-and-overfitting http://ciml.info/dl/v0_99/ciml-v0_99-ch01.pdf http://scikit-learn.org/stable/auto_examples/tree/plot_tree_regression.html
Copyright (c) 2017 LittleHann All rights reserved