3.SparkSQL学习
sparkSQL的发展历程。
- MapR的Drill
- Cloudera的Impala
- Shark
Spark SQL简介
Spark SQL是Spark的五大核心模块之一,用于在Spark平台之上处理结构化数据,利用Spark SQL可以构建大数据平台上的数据仓库,它具有如下特点:
(1)能够无缝地将SQL语句集成到Spark应用程序当中
(2)统一的数据访问方式 (多数据源) Hive, Avro, Parquet, ORC, JSON, and JDBC
(3)和Hive的兼容性很好
(4)可采用JDBC or ODBC连接
sparkSQL框架的架构
般情况下分为两个部分:a、把数据读入到sparkSQL中,sparkSQL进行数据处理或者算法实现,然后再把处理后的数据输出到相应的输出源中, 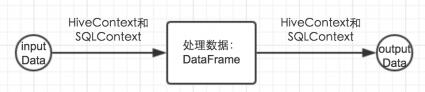
2.0开始没有了HiveContext和SQLContext变成了:SparkSession
DataFrame与RDD区别:
RDD以record为单位,spark优化时无法洞悉record内部的细节,无法深度优化,限制sparkSQL性能的提升;DataFrame包含了每个record的metadata元数据信息,DataFrame的优化可以对列内部优化。

获取、保存:内建和其它数据源的方式不同:例如
sqlContext.read().load("users.parquest")
sqlContext.read().format("json").load("student.json")
除了一个基本的 SQLContext,你也能够创建一个 HiveContext,它支持基本 SQLContext 所支持功能的一个超集。它的额外功能包括用更完整的 HiveQL 分析器写查询去访问 HiveUDFs 的能力、 从 Hive 表读取数据的能力。用 HiveContext 你不需要一个已经存在的 Hive 开启,SQLContext 可用的数据源对 HiveContext 也可用
SQLContext HiveContext原理:http://9269309.blog.51cto.com/9259309/1845525
dataFrame 的创建和操作方法
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// dataframe的创建,从json中创建的
val df = sqlContext.read.json("people.json")
// Show 方法显示 DataFrame的内容
df.show()
// 以树状的形式打印模式
df.printSchema()
// root
// |-- age: long (nullable = true)
// |-- name: string (nullable = true)
// Select 方法显示固定的列名
df.select(df("name"), df("age") + 1).show()
//过滤
df.filter(df("age") > 21).show()
//以age分组时候显示做对应age 的个数
df.groupBy("age").count().show() RDD和DATAFrame的转化
- 使用反射获取RDD内的Schema
- 当已知类的Schema的时候,使用这种基于反射的方法会让代码更加简洁而且效果也很好。
- 通过编程接口指定Schema
- 通过Spark SQL的接口创建RDD的Schema,这种方式会让代码比较冗长。
- 这种方法的好处是,在运行时才知道数据的列以及列的类型的情况下,可以动态生成Schema
1.反射方式
java版
//利用反射方式,RDD=>DataFrame 第一个参数:RDD,第二个参数是JavaBean,记得序列化,Person类
DataFrame personDF = sqlContext.createDataFrame(personRDD, Person.class);
//将personDF注册为一个临时表(persons)
personDF.registerTempTable("persons");
DataFrame bigDatas = sqlContext.sql("select * from persons where age >= 6");
//DataFrame => RDD
JavaRDD bigDataRDD = bigDatas.toJavaRDD();
JavaRDD result = bigDataRDD.map(new Function(){
private static final long serialVersionUID = 1L;
@Override
public Person call(Row row) throws Exception {
Person p = new Person();
//返回具体每条记录,如果用get**(index)返回的是字典顺序,可能不对应
p.setId(row.getAs(id));
p.setName(row.getAs(name));
return p;
}
});
scala版:
SparkSQL支持RDD到DataFrame的自动转换,实现方法是通过Case类定义表的Schema,Spark会通过反射机制读取case class的参数名并将其配置成表的列名
//导入该语句后,RDD将会被隐式转换成DataFrame
import sqlContext.implicits._
//定义一个类为Person的Case Class作为Schema
case class Person(name: String, age: Int)
//读取文件并将数据Map成Person实例,然后转换为DataFrame,采用toDF()方法
val people = sc.textFile("people.txt").map(_.split(",")).map(p => Person(p(0), p(1).trim.toInt)).toDF()
//将实例为people的DataFrame注册成表
people.registerTempTable("people")
//采用SQLContext中的sql方法执行SQL语句
val teenagers = sqlContext.sql("SELECT name, age FROM people WHERE age >= 13 AND age <= 19")
//输出返回结果
teenagers.map(t => "Name: " + t(0)).collect().foreach(println)2.动态转换
java版
JavaRDD lines = sc.textFile("persions.txt");
JavaRDD rows = lines.map(new Function(){
private static final long serialVersionUID = 1L;
@Override
public Row call(String line) throws Exception {
String[] lineSplited = line.split(",");
return RowFactory.create(Integer.valueOf(lineSplited[0]),lineSplited[0]);
}
});
List fields = new ArrayList<>();
fields.add(DataTypes.createStructField("id",DataTypes.IntegerType,true));
fields.add(DataTypes.createStructField("name",DataTypes.StringType,true));
StructType schema = DataTypes.createStructType(fields);
DataFrame personDF = sqlContext.createDataFrame(rows,schema);
scala版
某些情况下我们可能并不能提前确定对应列的个数,因而case class无法进行定义,此时可通过传入一个字符串来设置Schema信息
// 创建RDD
val people = sc.textFile("/data/people.txt")
//Schema字符串
val schemaString = "name age"
//利用schemaString动态生成Schema
val schema = StructType(schemaString.split(" ").map(fieldName => StructField(fieldName, StringType, true)))
// 将people RDD转换成Rows
val rowRDD = people.map(_.split(",")).map(p => Row(p(0), p(1).trim))
// 创建DataFrame
val peopleDataFrame = sqlContext.createDataFrame(rowRDD, schema)
//注册成表
peopleDataFrame.registerTempTable("people")
//执行SQL语句.
val results = sqlContext.sql("SELECT name FROM people")
//打印输出
results.map(t => "Name: " + t(0)).collect().foreach(println)Spark Sql 数据源
1.外部文件
1.1、parquet
scala:
val df = sqlContext.load("people.parquet")
df.select("name", "age").save("namesAndAges.parquet")
java:
DataFrame peopleDF = sqlContext.read().load("people.parquet")
peopleDF.select("name", "age").write().save("namesAndAges.parquet");1.2、json
- jsonFile :从一个 JSON 目录中加载数据,JSON 文件中每一行为一个 JSON 对象。
- jsonRDD :从一个 RDD 中加载数据,RDD 的每一个元素为一个 JSON 对象的字符串。
scala:
val people = sqlContext.jsonFile("people.json")
people.registerTempTable("people")
val teenagers = sqlContext.sql("SELECT name FROM people WHERE age >= 13 ")
---------------------------------------------------------------------------------------
val anotherPeopleRDD = sc.parallelize("{\"name\":\"Yin\",\"address\":\"china\"}",
"{\"name\":\"Yin\",\"address\":\"USA\"}")
val anotherPeople = sqlContext.jsonRDD(anotherPeopleRDD)
java:
DataFrame peopleDF = sqlContext.read().json("people.json");
-------------------------------------------------------------
List lists = new ArrayList<>();
list.add("{\"name\":\"Yin\",\"address\":\"china\"}");
list.add("{\"name\":\"Yin\",\"address\":\"china\"}");
JavaRDD jsonRDD = sc.parallelize(lists);
DataFrame peopleDF = sqlContext.read().json("people.json");
2.jdbc数据源
Scala:
val jdbcDF = sqlContext.load("jdbc", Map(
"url" -> "jdbc:mysql://ip:port/DB",
"dbtable" -> "table",
"user" -> "root",
"password" -> "root"))
Java:
Map options = new HashMap();
options.put("url", "jdbc:mysql://ip:port/DB");
options.put("dbtable", "table");
options.put("user", "root");
options.put("password", "root");
DataFrame jdbcDF = sqlContext.read().format("jdbc").options(options).load(); 3.Hive数据源
// sc is an existing SparkContext.
Scala:
val sqlContext = new HiveContext(sc)
val DF = sqlContext.sql("select * from test")
Java:
HiveContext sqlContext = new HiveContext(sc.sc());
DataFrame DF = sqlContext.sql("select * from test")