1.spark简介
1.什么是Spark
并行计算框架
基于内存计算
高容错
基于DAG
2.Spark生态体系图
MapReduce属于Hadoop生态体系之一,Spark则属于BDAS生态体系之一
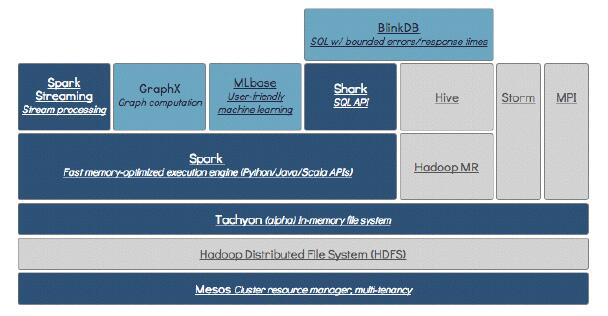
3.Spark VS MapReduce
为什么Spark比MapReduce快:
a.磁盘IO开销:Spark中间计算结果都是基于内存,节省开销;
b.排序:Spark避免MapReduc中不必要的排序;
c.DAG:Spark内核会在需要计算发生的时刻绘制一张关于计算路径的有向无环图,也就是DAG。
MapReduce:

spark:

4.Spark支持的API
Scala、Python、Java、R;对于Scala和Python有Shell的支持。
5、运行模式
Local (用于测试、开发)Standlone (独立集群模式)
Spark on Yarn (Spark在Yarn上)
Spark on Mesos (Spark在Mesos)
6.Spark运行
Spark运行时,类似于MapReduce,他有主节点master和从节点Worker,其中Driver的调度类似于MapReduce的MrAppMaster,而Worker从文件系统加载数据并产生RDD文件,spark所有操作均基于RDD。
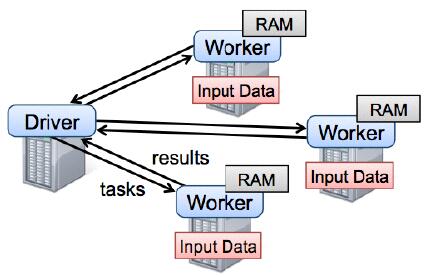
7.RDD
Resilient Distributed Dataset (RDD)弹性分布数据集
RDD是Spark的最基本抽象,是对分布式内存的抽象使用,实现了以操作本地集合的方式来操作分布式数据集的抽象实现。RDD是Spark最核心的东西,它表示已被分区,不可变的并能够被并行操作的数据集合,不同的数据集格式对应不同的RDD实现。RDD必须是可序列化的。RDD可以cache到内存中,每次对RDD数据集的操作之后的结果,都可以存放到内存中,下一个操作可以直接从内存中输入,省去了MapReduce大量的磁盘IO操作。这对于迭代运算比较常见的机器学习算法, 交互式数据挖掘来说,效率提升比较大。
操作主要分成2大类:
- 转换是一种操作(例如映射、过滤、联接、联合等等),它在一个RDD上执行操作,然后创建一个新的RDD来保存结果。
- 行动是一种操作(例如归并、计数、第一等等),它在一个RDD上执行某种计算,然后将结果返回。
RDD支持两种操作类型:
a.Transformation:延迟执行,一个RDD通过该操作产生的新的RDD时不会立即执行,只有等到Action操作才会真正执行。
b.Action:提交Spark作业,当Action时,Transformation类型的操作才会真正执行计算操作,然后产生最终结果输出。
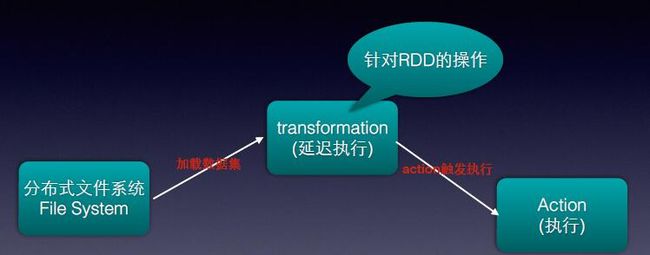


它是在集群节点上的不可变的、已分区的集合对象。
通过并行转换的方式来创建如(map, filter, join, etc)。
失败自动重建。
可以控制存储级别(内存、磁盘等)来进行重用。
必须是可序列化的。
是静态类型的
在RDD的内部实现中每个RDD都可以使用5个方面的特性来表示:
a.分区列表(数据块列表)
b.计算每个分片的函数(根据父RDD计算出此RDD)
c.对父RDD的依赖列表
d.对key-value RDD的Partitioner【可选】
e.每个数据分片的预定义地址列表(如HDFS上的数据块的地址)【可选】
8.缓冲策略
当前RDD默认是存储于内存,但当内存不足时,RDD会spill到disk。
RDD在需要进行分区把数据分布于集群中时会根据每条记录Key进行分区(如Hash 分区),以此保证两个数据集在Join时能高效。
Spark通过useDisk、useMemory、useOffHeap、deserialized、replication5个参数组成12种缓存策略。
useDisk:使用磁盘缓存(boolean )
useMemory:使用内存缓存(boolean)
deserialized:反序列化(序列化是为了网络将对象进行传输,boolean:true反序列化\false序列化)
replication:副本数量(int)
通过StorageLevel类的构造传参的方式进行控制,结构如下:
private var _useDisk: Boolean,
private var _useMemory: Boolean,
private var _useOffHeap: Boolean,
private var _deserialized: Boolean,
private var _replication:Int = 19.容错Lineage
每个RDD都会记录自己所依赖的父RDD,一旦出现某个RDD的某些partition丢失,可以通过并行计算迅速恢复
策略:
a.重新计算
b.checkpoint:某一RDD节点保存起来。
c.cache缓冲(容错,复用都可)
窄依赖:每个partition最多只能给一个RDD使用,由于没有多重依赖,所以在一个节点上可以一次性将partition处理完,且一旦数据发生丢失或者损坏可以迅速从上一个RDD恢复
宽依赖:每个partition可以给多个RDD使用,由于多重依赖,只有等到所有到达节点的数据处理完毕才能进行下一步处理,一旦发生数据丢失或者损坏,则完蛋了,所以在这发生之前必须将上一次所有节点的数据进行物化(存储到磁盘上)处理,这样达到恢复。shuffle就是一个宽依赖
宽、窄依赖示例图:(空心表示:RDD,实心蓝色:partitioned )
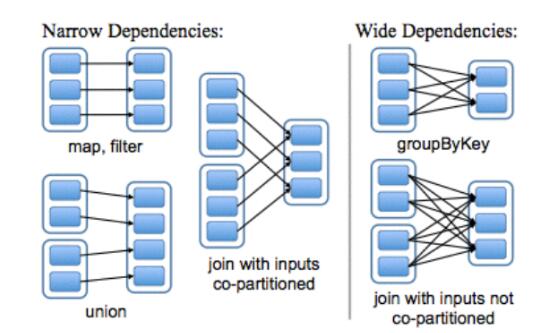
Spark根据算子判断是宽依赖还是窄依赖,主要作用是用于任务的切割
当程序运行Action会产生一个job任务,job任务是一个DAG,因为分布式的运行所有会将任务进行切分为多个Stage,Stage就是根据宽依赖进行切分的。窄依赖不切分(DAG优化)
窄依赖例如:c->d->f 计算过程是都会在c的内存块儿就行计算,不会出现中间结果d再写入另一个地方再读。

计算过程中,例如c->d->f 会分为一个pipeline,一个pipeline就是一个task任务,task任务就是spark计算的最小单元。job-->Stage-->task
上图的优化过程
a.DAG自己本身的优化
b.代码自身的优化,加入一个B的过程,起到缓存作用,变成一个3*3和一个4*3的过程。因为时间计算是宽依赖为主,窄依赖可忽略,加入B后,B->G是一个窄依赖的过程,当出现问题时,如果stage1出问题只需重新计算3*3,如果是stage2出问题只需计算4*3,如果没有B,就无法判断是哪的问题,会全部执行是一个7*3的过程。
10、提交的方式
spark-submit(官方推荐)sbt run
java -jar
提交时可以指定各种参数
./bin/spark-submit
-- class
--master
--deploy-mode
--conf =
... # other options
[application-arguments] http://www.tuicool.com/articles/eq2meyf
https://my.oschina.net/u/2306127/blog/470505
http://blog.csdn.net/lmh12506/article/details/48131883