索引(三)查询性能优化
索引(三)查询性能优化
高性能MYSQL需要设计最优的库表结构,建立最好的索引,合理的设计查询。查询优化,索引优化,库表结构优化三辆
大车需要起头并进,才能达到最好的性能。
查询的生命周期
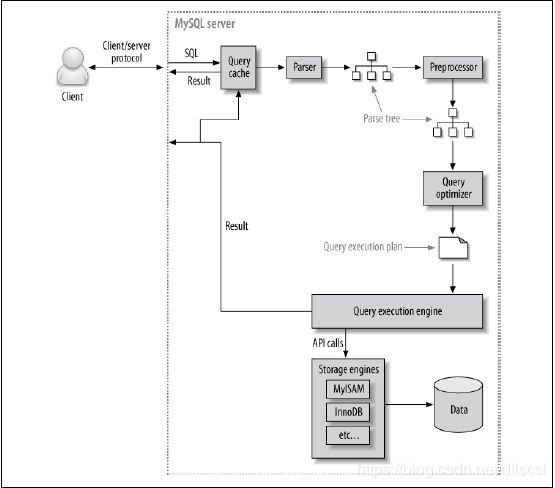
MySQL查询的生命周期:
-
客户端发送一条查询给服务器
-
服务器先检查查询缓存,如果命中了缓存,则立刻返回存储在缓存中的结果,否则进入下一阶段。
-
服务器进行SQL解析,预处理,再由优化器生成对应的执行计划,
-
mysql根据优化器生成的执行计划,调用存储引擎的API来执行查询。
-
将结果返回给客户端。
了解查询的生命周期,清楚查询的时间消耗情况对于优化查询有很大的意义
优化数据访问
查询性能低下的最基本原因是访问的数据太多,可以按照下面两个步骤分析:
- 是否检索大量超过需要的数据
- MySQL服务器层是否在分析大量超过需要的数据行
1.是否向数据库请求了不需要的数据
带来的问题:对Mysql服务器增加额外的负担,增加网络开销,消耗应用程序服务器的CPU和内存资源
- 查询不需要的记录:ADD LIMIT
- 多表关联时返回全部列:JOIN NO SELECT *
- 总是取出全部列:NO SELECT *
- 重复查询相同的数据:缓存
2.MySQL是否在扫描额外的记录
衡量查询开销的三个指标:
- 响应时间
- 扫描的行数
- 返回的行数
查询优化
执行计划EXPLAIN
mysql> EXPLAIN SELECT * FROM coupon_remind;
+----+-------------+---------------+------+---------------+------------+---------+---------+---------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------------+------+---------------+------------+---------+---------+---------+-------+
| 1 | SIMPLE | coupon_remind | ALL | NULL | NULL | NULL | NULL |623753 | NULL |
+----+-------------+---------------+------+---------------+------------+---------+---------+---------+-------+
| id | 查询类型 |查询对象 |访问类型|可能使用的索引 实际使用的索引 索引长度 索引对应的列 检索行数 额外信息
+----+-------------+---------------+------+---------------+------------+---------+---------+---------+-------+
1 row in set (0.03 sec)
- id:就是每个查询的标识,当这一行显示的事其他行union的结果时,id为null,同时在table列会显示
,M和N就是对应的查询id - select_type:查询类型,具体如下
- SIMPLE:没有使用union或子查询的
- PRIMARY:最外层的查询
- UNION:union语句里的第二个或之后的查询对象的查询
- DEPENDENT UNION:在select里的union查询的第二个或之后的查询对象的查询
- UNION RESULT:union的结果
- SUBQUERY:where子查询里第一个查询对象的查询
- DEPENDENT SUBQUERY:在select里的子查询的第一个查询对象的查询
- DERIVED:在from后面的查询结果的查询
- table:查询对象,具体如下
- 具体表或对应别名
:M和N对应查询的id,即M union N后的结果
- type:访问类型,表示MySQL在表中找到所需行的方式:
- system:该表只有1行(同系统表),是const的特殊类型
- const:开始查询时使用索引只匹配出1条记录
- eq_ref:a表和b表关联时,使用的索引时主键或者非空唯一索引,每次关联都是一一对应的。eq_ref是除了system和const这两种关联类型外最好的,在=运算符时出现
- ref:关联时索引只用了最左前缀或者不是主键和唯一索引
- fulltext:在使用了FULLTEXT index时出现
- ref_or_null:和ref类似,只不过在where子句中加了索引列为null的判断
- index_merge:标识了本次关联MYSQL优化器做了index merge,在key列会列出用到的索引,key_len则是使用到的索引部分的长度和
- unique_subquery:在where的子查询中,如果in子查询返回结果是主键时,会用unique_subquery替换eq_ref
- index_subquery:类似unique_subquery,in子查询里非唯一索引
- range:查询结果会返回一个范围。在索引列通过 =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, or IN()运算符和常量连接时使用。ref列会返回null。
- index:跟ALL相同,当索引树被遍历时为index,通常比ALL高效,因为只遍历索引,会比table的数据小,此时Extra列的值为Using Index。或者从索引树开始做全表扫描,join类型也是index,只不过此时Extra列不出现Using Index
- ALL:针对关联列都做了全表扫描。除非该表是const的,否则性能很差,需要建索引。
常用的类型有: ALL, index, range, ref, eq_ref, const, system, NULL(从左到右,性能从差到好)
- possible_keys:指出MySQL能使用哪个索引在表中找到记录,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询使用
- Key:key列显示MySQL实际决定使用的键(索引),如果没有选择索引,键是NULL
- key_len:表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度(key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的)
- ref:表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
- rows: 表示MySQL根据表统计信息及索引选用情况,估算的找到所需的记录所需要读取的行数,理论上行数越少,查询性能越好
- Extra:额外信息,具体解释参考 EXPLAIN介绍
慢查询优化实战
业务介绍
红包过期前两天短信提醒,技术方案上面让数据中心凌晨采集两天后过期的数据回流到红包提醒表内,当天下午4点跑定时任务用LIMIT分页加载数据发送短信提醒。每条处理好的记录都会更新状态,峰值回流的数据大概一天有2w条左右。
目前业务处理花费时间:
以2019年1月7号为例子,共处理12800记录,所有业务处理花费4分58秒。最后一次扫表数据查询耗时不过5ms
表结构和查询语句
表结构:
CREATE TABLE `coupon_remind` (
`id` bigint(20) NOT NULL COMMENT '主键ID',
`customer_register_id` varchar(32) NOT NULL DEFAULT '' COMMENT '会员id',
`mobile` varchar(32) NOT NULL DEFAULT '' COMMENT '手机号码',
`open_id` varchar(32) NOT NULL DEFAULT '' COMMENT '公众号openId',
`coupon_id_list` varchar(512) NOT NULL DEFAULT '' COMMENT '红包id集合用;分割',
`content` varchar(200) NOT NULL DEFAULT '' COMMENT '推送内容',
`status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '状态(1未处理,2处理成功)',
`remind_type` tinyint(4) NOT NULL DEFAULT '0' COMMENT '类型(1红包到期提醒)',
`expire_date` bigint(20) NOT NULL DEFAULT '0' COMMENT '过期时间戳',
`curr_date` varchar(32) NOT NULL DEFAULT '0' COMMENT '统计日期,某一天,20180605',
`is_valid` tinyint(2) NOT NULL DEFAULT '0' COMMENT '是否有效',
`last_ver` int(11) NOT NULL DEFAULT '0' COMMENT '版本号',
`create_time` bigint(20) NOT NULL DEFAULT '0' COMMENT '创建时间毫秒',
`op_time` bigint(20) NOT NULL DEFAULT '0' COMMENT '修改时间毫秒',
PRIMARY KEY (`id`),
KEY `index_customer_register_id` (`customer_register_id`) USING BTREE,
KEY `index_curr_date` (`curr_date`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='红包提醒'
查询SQL:
SELECT
id,
customer_register_id,
mobile,
open_id,
coupon_id_list,
content,
status,
remind_type,
expire_date,
curr_date,
is_valid,
last_ver,
create_time,
op_time
FROM
presell_market.coupon_remind
WHERE
curr_date = '20181113' AND status = 1 AND is_valid = 1 LIMIT 100;
上述业务场景单表处理数据10w以下的时候基本上不会有问题,我们模拟下业务超超超级高峰情况下面,查询是否有影响。
模拟数据:20181113存在624805条status = 1 AND is_valid = 1的记录。
index on curr_date
模拟下实际过程中完整的业务流程,查询性能怎么样
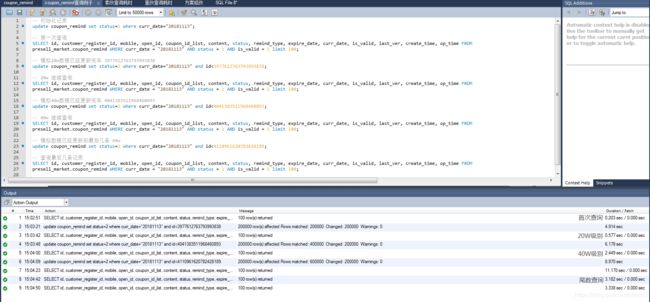
可以看出来,越往后面的查询性能瓶颈越大,耗时越高
我们对比下首次查询和尾数查询的执行计划,看下有什么区别
首次查询

尾数查询

通过上述模拟数据我们可以分析,超过10w级别的数据量,查询的性能已经比较差了,尾数业务数据处理则会越来越慢
分析下原因,为什么最后一次查询跟第一次查询性能相差百倍,结合业务场景,随着一批一批数据处理,status状态被更新成2,到最后一些数据的时候,前置已经处理完的数据还是被MySQL服务器计算,筛选到status=1的数据,然后选取100条返回。因此优化的方式在于如何减少查询扫描的数据行数?
我们假设,如果建立curr_date和status的联合索引,可不可以解决这个问题?
完整业务查询(索改)
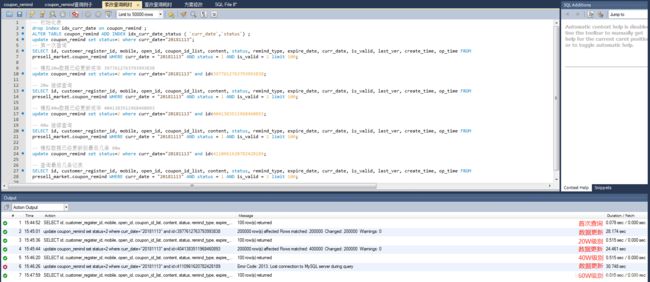
尾数查询执行计划(索改)

通过跟之前的查询执行过程对比,查询的性能大大提升,但是!!
这个并不是最佳的优化手段,更新操作的耗时变得更长,业务流程中会涉及到status字段更新,索引字段的更新操作,会引起索引重建,存储空间也会相应增大,得不偿失。
我们再对比下两个索引,
SHOW INDEX FROM coupon_remind;
这个命令可以查看这张表创建了哪些索引,命令输出结果列如下:
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment |
- Table:表的名称
- Non_unique :如果索引不能包括重复词,则为0。如果可以,则为1
- Key_name :索引的名称
- Seq_in_index :索引中的列序列号,从1开始
- Column_name :列名称
- Collation :列以什么方式存储在索引中。在MySQL中,有值‘A’(升序)或NULL(无分类)
- Cardinality:索引中唯一值的数目的估计值,在实际应用中,Cardinality/n_rows_in_table 应尽可能地接近1
- Sub_part:如果列只是被部分地编入索引,则为被编入索引的字符的数目。如果整列被编入索引,则为NULL。
- Packed:指示关键字如何被压缩。如果没有被压缩,则为NULL。
- Null:如果列含有NULL,则含有YES。如果没有,则该列含有NO。
- Index_type:索引类型(BTREE, FULLTEXT, HASH, RTREE)。
- Comment:说明
首先看下,index on (‘curr_date’)的索引属性:

对比下,index on (‘curr_date’, ‘status’):

两者的Cardinality都很小。
修改索引来优化查询这个方法不可行,那么调整下思路,能不能修改查询语句来减少扫描的数据?
如果我们可以记录上次查询的位置,下一次查询,从这个位置开始,就可以避免扫描计算多余的数据了。所以查询SQL可以调整成这样
SELECT
id,
customer_register_id,
mobile,
open_id,
coupon_id_list,
content,
status,
remind_type,
expire_date,
curr_date,
is_valid,
last_ver,
create_time,
op_time
FROM
presell_market.coupon_remind
WHERE
id > #{beginId} AND curr_date = '20181113' AND status = 1 AND is_valid = 1 LIMIT 100;
我们来模拟下效果,完整的一次业务查询:
改造前
改造后
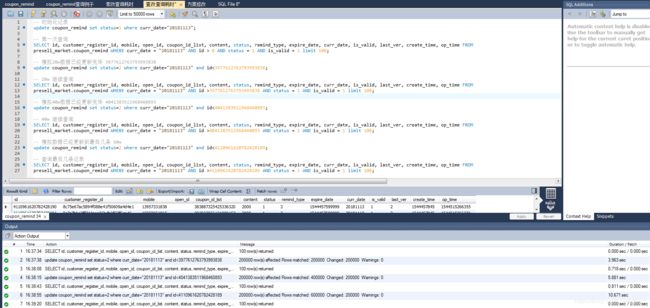
跟最初的查询对比,查询性能提升了很多,让我们看下查改之后的第一次执行计划:
改造前
改造后

再看下最后一次查询的执行计划:
改造前

改造后

通过上面两个执行计划可以发现当没有id>xxx这个查询条件的时候,检索的rows要多很多。
修改查询语句之后的完整业务执行流程时间,尾页查询比20w,40w量级的时候耗时更短,通过执行计划可以发现两者的key不同,rows不同,如果我们将语句调整成这样,是否可以让查询变成主键索引,是否可以减少所有查询的RT?
尝试之后发现并没有多少变化
综上所述,通过标记上一次扫描的位置,减少数据的扫描量,可以很好的优化性能,无论是翻到多后面,性能都会很好。
总结
对于索引原理的理解可以帮助我们更好的建立合适的索引。结合实际的业务和执行分析,评估数据的量级,不要想当然的去建立索引。业务上线之后及时去跟进线上慢查询的情况,具体问题具体分析,具体优化。
参考文档
MySQL官方文档