第97课: 使用Spark Streaming+Spark SQL+mysql 实现在线动态计算出特定时间窗口下的不同种类商品中的热门商品排名(详细内幕版本)
第97课: 使用Spark Streaming+Spark SQL+mysql 实现在线动态计算出特定时间窗口下的不同种类商品中的热门商品排名.
/* 王家林老师授课http://weibo.com/ilovepains 每天晚上20:00YY频道现场授课频道68917580*/
使用Spark Streaming+Spark SQL+Mysql来在线动态计算电商中不同类别中最热门的商品排名,例如手机这个类别下面最热门的三种手机、电视这个类别
下最热门的三种电视,该实例在实际生产环境下具有非常重大的意义;
Spark Streaming+Spark SQL+mysql 知易行难,也是知难行易
1, java.lang.NullPointerException 空指针问题解决
- foreachRDD、foreachPartition 增加isEmpty的判断
- 单元测试,单独把数据库连接入库的代码运行,硬编码方式插入记录,验证数据库连接正常。
- 看foreachRDD、foreachPartition的源代码,加深对foreachRDD、foreachPartition理解。
- nc -lk 9999 输入数据格式的规范,避免输入数据格式出错。
- 打印日志排查 reseltDataFram.show() resultRowRDD.take(10).foreach(println)
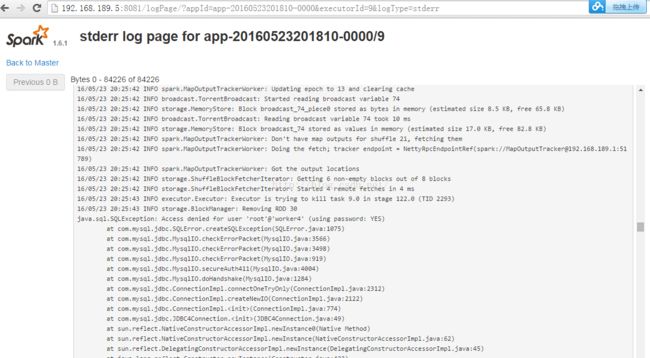
2,java.sql.SQLException: Access denied for user 'root'@'worker6' 权限问题解决
在mysq中 开通远程登录的权限:
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root' WITH GRANT OPTION;
FLUSH PRIVILEGES;
3,虚拟机磁盘空间问题解决。
windows+vmvare虚拟机,huawei服务器设备只有300G,安装了1个master,8个worker虚拟机设备,每台虚拟机设备分配20g的空间 ,实际运行时候每台虚拟机约10g左右,但运行spark streamin的时,虚拟机会不断的占用物理机硬盘资源,导致 磁盘资源不够 ,虚拟机本身运行就提示报错了,实验无法进行。因此,扩容了一个 1T的移动硬盘,将虚拟机全部复制到移动硬盘上 运行 ,运行速度稍微曼一点,流处理实验得以继续!
4,spark日志的打印调试
driver上console中实时查看流处理的日志;
但task是Executor 在运行,因此一部分日志在driver上不会显示 ,此时需要登录到Executor stderr log 查看日志 ,就能全面掌握spark streaming的运行情况,解决问题。
Spark Streaming+Spark SQL+Mysql来在线动态计算电商中不同类别中最热门的商品排名
综合案例实施步骤
启动hadoop dfs
root@master:/usr/local/hadoop-2.6.0/sbin# start-dfs.sh
Starting namenodes on [master]
master: starting namenode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-root-namenode-master.out
worker1: starting datanode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-root-datanode-worker1.out
worker3: starting datanode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-root-datanode-worker3.out
worker2: starting datanode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-root-datanode-worker2.out
worker6: starting datanode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-root-datanode-worker6.out
worker7: starting datanode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-root-datanode-worker7.out
worker4: starting datanode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-root-datanode-worker4.out
worker5: starting datanode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-root-datanode-worker5.out
worker8: starting datanode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-root-datanode-worker8.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-root-secondarynamenode-master.out
启动spark
root@master:/usr/local/spark-1.6.1-bin-hadoop2.6/sbin# start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark-1.6.1-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.master.Master-1-master.out
worker6: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-1.6.1-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-worker6.out
worker1: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-1.6.1-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-worker1.out
worker5: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-1.6.1-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-worker5.out
worker3: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-1.6.1-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-worker3.out
worker2: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-1.6.1-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-worker2.out
worker7: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-1.6.1-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-worker7.out
worker8: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-1.6.1-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-worker8.out
worker4: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-1.6.1-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-worker4.out
root@master:/usr/local/spark-1.6.1-bin-hadoop2.6/sbin# jps
2916 NameNode
3253 SecondaryNameNode
3688 Jps
3630 Master
启动hive的元数据服务
root@master:~# hive --service metastore &
[1] 4917
root@master:~# SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/hadoop-2.6.0/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/spark-1.6.1-bin-hadoop2.6/lib/spark-assembly-1.6.1-hadoop2.6.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Starting Hive Metastore Server
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/hadoop-2.6.0/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/spark-1.6.1-bin-hadoop2.6/lib/spark-assembly-1.6.1-hadoop2.6.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
加上mysql的jar包
root@master:/usr/local/spark-1.6.1-bin-hadoop2.6/lib# cd /usr/local
root@master:/usr/local# ls
apache-flume-1.6.0-bin games IMF_testdata lib setup_tools zookeeper-3.4.6
apache-hive-1.2.1 hadoop-2.6.0 include man share
bin idea-IC-145.597.3 jdk1.8.0_60 sbin spark-1.6.0-bin-hadoop2.6
etc IMFIdeaIDE kafka_2.10-0.8.2.1 scala-2.10.4 spark-1.6.1-bin-hadoop2.6
flume IMF_IDEA_WorkSpace kafka_2.10-0.9.0.1 setup_scripts src
root@master:/usr/local# cd setup_tools
root@master:/usr/local/setup_tools# ls
apache-hive-1.2.1-bin.tar.gz mysql-connector-java-5.1.13-bin.jar spark-1.6.1-bin-hadoop2.6.tgz
apache-hive-1.2.1-src.tar.gz mysql-connector-java-5.1.36.zip spark-streaming_2.10-1.6.0.jar
commons-lang3-3.3.2.jar scala-2.10.4.tgz spark-streaming-flume-sink_2.10-1.6.1.jar
hadoop-2.6.0.tar.gz scala-library-2.10.4.jar spark-streaming-kafka_2.10-1.6.0.jar
jdk-8u60-linux-x64.tar.gz slf4j-1.7.21 SparkStreamingOnKafkaDirected161.jar
kafka_2.10-0.8.2.1.tgz slf4j-1.7.21.zip StreamingKafkajars
kafka_2.10-0.9.0.1.tgz spark-1.6.0-bin-hadoop2.6.tgz zookeeper-3.4.6.tar.gz
root@master:/usr/local/setup_tools# cp mysql-connector-java-5.1.13-bin.jar /usr/local/spark-1.6.1-bin-hadoop2.6/lib/
root@master:/usr/local/setup_tools# cd /usr/local/spark-1.6.1-bin-hadoop2.6/lib
root@master:/usr/local/spark-1.6.1-bin-hadoop2.6/lib# ls
datanucleus-api-jdo-3.2.6.jar mysql-connector-java-5.1.13-bin.jar spark-examples-1.6.1-hadoop2.6.0.jar
datanucleus-core-3.2.10.jar spark-1.6.1-yarn-shuffle.jar spark-streaming_2.10-1.6.1.jar
datanucleus-rdbms-3.2.9.jar spark-assembly-1.6.1-hadoop2.6.0.jar spark-streaming-kafka_2.10-1.6.1.jar
root@master:/usr/local/spark-1.6.1-bin-hadoop2.6/lib#
启动mysql及授权
root@master:~# mysql -uroot -proot
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 1
Server version: 5.5.47-0ubuntu0.14.04.1 (Ubuntu)
Copyright (c) 2000, 2015, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root' WITH GRANT OPTION;
Query OK, 0 rows affected (0.09 sec)
mysql> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.03 sec)
mysql> exit
重启mysql
Bye
root@master:~# service mysql -restart
Usage: /etc/init.d/mysql start|stop|restart|reload|force-reload|status
root@master:~# /etc/init.d/mysql restart
* Stopping MySQL database server mysqld
...done.
* Starting MySQL database server mysqld
...done.
* Checking for tables which need an upgrade, are corrupt or were
not closed cleanly.
root@master:~# mysql -uroot -proot
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 80
Server version: 5.5.47-0ubuntu0.14.04.1 (Ubuntu)
Copyright (c) 2000, 2015, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| hive |
| mysql |
| performance_schema |
| spark |
| sparkstreaming |
+--------------------+
6 rows in set (0.07 sec)
mysql> use sparkstreaming;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show tables;
+--------------------------+
| Tables_in_sparkstreaming |
+--------------------------+
| categorytop3 |
+--------------------------+
1 row in set (0.00 sec)
准备IMFOnlineTheTop3ItemForEachCategory2DB.sh
root@master:/usr/local/setup_scripts# cat IMFOnlineTheTop3ItemForEachCategory2DB.sh
/usr/local/spark-1.6.1-bin-hadoop2.6/bin/spark-submit --files /usr/local/apache-hive-1.2.1/conf/hive-site.xml --class com.dt.spark.sparkstreaming.OnlineTheTop3ItemForEachCategory2DB --master spark://192.168.189.1:7077 --jars /usr/local/spark-1.6.1-bin-hadoop2.6/lib/mysql-connector-java-5.1.13-bin.jar,/usr/local/spark-1.6.1-bin-hadoop2.6/lib/spark-streaming_2.10-1.6.1.jar,/usr/local/spark-1.6.1-bin-hadoop2.6/lib/spark-assembly-1.6.1-hadoop2.6.0.jar /usr/local/IMF_testdata/OnlineTheTop3ItemForEachCategory2DB.jar
root@master:/usr/local/setup_scripts#
运行 IMFOnlineTheTop3ItemForEachCategory2DB.sh
root@master:/usr/local/setup_scripts# IMFOnlineTheTop3ItemForEachCategory2DB.sh
16/05/24 19:43:50 INFO spark.SparkContext: Running Spark version 1.6.1
16/05/24 19:43:54 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/05/24 19:43:56 INFO spark.SecurityManager: Changing view acls to: root
16/05/24 19:43:56 INFO spark.SecurityManager: Changing modify acls to: root
16/05/24 19:43:56 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root)
16/05/24 19:44:03 INFO util.Utils: Successfully started service 'sparkDriver' on port 45343.
16/05/24 19:44:10 INFO slf4j.Slf4jLogger: Slf4jLogger started
16/05/24 19:44:11 INFO Remoting: Starting remoting
16/05/24 19:44:13 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://[email protected]:40031]
16/05/24 19:44:14 INFO util.Utils: Successfully started service 'sparkDriverActorSystem' on port 40031.
16/05/24 19:44:14 INFO spark.SparkEnv: Registering MapOutputTracker
16/05/24 19:44:15 INFO spark.SparkEnv: Registering BlockManagerMaster
16/05/24 19:44:15 INFO storage.DiskBlockManager: Created local directory at /tmp/blockmgr-0338e0f4-6fdb-4139-9b63-ddf8915b959e
16/05/24 19:44:15 INFO storage.MemoryStore: MemoryStore started with capacity 511.1 MB
16/05/24 19:44:16 INFO spark.SparkEnv: Registering OutputCommitCoordinator
16/05/24 19:44:19 INFO server.Server: jetty-8.y.z-SNAPSHOT
16/05/24 19:44:19 INFO server.AbstractConnector: Started [email protected]:4040
16/05/24 19:44:19 INFO util.Utils: Successfully started service 'SparkUI' on port 4040.
16/05/24 19:44:19 INFO ui.SparkUI: Started SparkUI at http://192.168.189.1:4040
16/05/24 19:44:19 INFO spark.HttpFileServer: HTTP File server directory is /tmp/spark-88fc0bc3-0348-47c7-92a8-1c611097d54c/httpd-f3e303c0-2170-4a35-90b9-eb9ade234a8c
16/05/24 19:44:19 INFO spark.HttpServer: Starting HTTP Server
16/05/24 19:44:19 INFO server.Server: jetty-8.y.z-SNAPSHOT
16/05/24 19:44:19 INFO server.AbstractConnector: Started [email protected]:37513
16/05/24 19:44:19 INFO util.Utils: Successfully started service 'HTTP file server' on port 37513.
16/05/24 19:44:20 INFO spark.SparkContext: Added JAR file:/usr/local/spark-1.6.1-bin-hadoop2.6/lib/mysql-connector-java-5.1.13-bin.jar at http://192.168.189.1:37513/jars/mysql-connector-java-5.1.13-bin.jar with timestamp 1464090260313
16/05/24 19:44:20 INFO spark.SparkContext: Added JAR file:/usr/local/spark-1.6.1-bin-hadoop2.6/lib/spark-streaming_2.10-1.6.1.jar at http://192.168.189.1:37513/jars/spark-streaming_2.10-1.6.1.jar with timestamp 1464090260516
16/05/24 19:44:47 INFO spark.SparkContext: Added JAR file:/usr/local/spark-1.6.1-bin-hadoop2.6/lib/spark-assembly-1.6.1-hadoop2.6.0.jar at http://192.168.189.1:37513/jars/spark-assembly-1.6.1-hadoop2.6.0.jar with timestamp 1464090287728
16/05/24 19:44:47 INFO spark.SparkContext: Added JAR file:/usr/local/IMF_testdata/OnlineTheTop3ItemForEachCategory2DB.jar at http://192.168.189.1:37513/jars/OnlineTheTop3ItemForEachCategory2DB.jar with timestamp 1464090287774
16/05/24 19:44:51 INFO util.Utils: Copying /usr/local/apache-hive-1.2.1/conf/hive-site.xml to /tmp/spark-88fc0bc3-0348-47c7-92a8-1c611097d54c/userFiles-46d0a8e8-1c2f-4d9b-9f36-6a6cb666b7ea/hive-site.xml
16/05/24 19:44:52 INFO spark.SparkContext: Added file file:/usr/local/apache-hive-1.2.1/conf/hive-site.xml at http://192.168.189.1:37513/files/hive-site.xml with timestamp 1464090291387
16/05/24 19:44:53 INFO client.AppClient$ClientEndpoint: Connecting to master spark://master:7077...
16/05/24 19:44:55 INFO cluster.SparkDeploySchedulerBackend: Connected to Spark cluster with app ID app-20160524194455-0000
16/05/24 19:44:55 INFO util.Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 45943.
16/05/24 19:44:55 INFO netty.NettyBlockTransferService: Server created on 45943
16/05/24 19:44:55 INFO storage.BlockManagerMaster: Trying to register BlockManager
16/05/24 19:44:55 INFO storage.BlockManagerMasterEndpoint: Registering block manager 192.168.189.1:45943 with 511.1 MB RAM, BlockManagerId(driver, 192.168.189.1, 45943)
16/05/24 19:44:55 INFO storage.BlockManagerMaster: Registered BlockManager
16/05/24 19:44:56 INFO client.AppClient$ClientEndpoint: Executor added: app-20160524194455-0000/0 on worker-20160524192017-192.168.189.5-50261 (192.168.189.5:50261) with 1 cores
16/05/24 19:44:56 INFO cluster.SparkDeploySchedulerBackend: Granted executor ID app-20160524194455-0000/0 on hostPort 192.168.189.5:50261 with 1 cores, 1024.0 MB RAM
16/05/24 19:44:56 INFO client.AppClient$ClientEndpoint: Executor added: app-20160524194455-0000/1 on worker-20160524192003-192.168.189.3-41671 (192.168.189.3:41671) with 1 cores
16/05/24 19:44:56 INFO cluster.SparkDeploySchedulerBackend: Granted executor ID app-20160524194455-0000/1 on hostPort 192.168.189.3:41671 with 1 cores, 1024.0 MB RAM
16/05/24 19:44:56 INFO client.AppClient$ClientEndpoint: Executor added: app-20160524194455-0000/2 on worker-20160524192004-192.168.189.6-60895 (192.168.189.6:60895) with 1 cores
16/05/24 19:44:56 INFO cluster.SparkDeploySchedulerBackend: Granted executor ID app-20160524194455-0000/2 on hostPort 192.168.189.6:60895 with 1 cores, 1024.0 MB RAM
16/05/24 19:44:56 INFO client.AppClient$ClientEndpoint: Executor added: app-20160524194455-0000/3 on worker-20160524192004-192.168.189.2-36469 (192.168.189.2:36469) with 1 cores
16/05/24 19:44:56 INFO cluster.SparkDeploySchedulerBackend: Granted executor ID app-20160524194455-0000/3 on hostPort 192.168.189.2:36469 with 1 cores, 1024.0 MB RAM
16/05/24 19:44:56 INFO client.AppClient$ClientEndpoint: Executor added: app-20160524194455-0000/4 on worker-20160524192006-192.168.189.4-33516 (192.168.189.4:33516) with 1 cores
16/05/24 19:44:56 INFO cluster.SparkDeploySchedulerBackend: Granted executor ID app-20160524194455-0000/4 on hostPort 192.168.189.4:33516 with 1 cores, 1024.0 MB RAM
16/05/24 19:44:56 INFO client.AppClient$ClientEndpoint: Executor added: app-20160524194455-0000/5 on worker-20160524192008-192.168.189.9-39335 (192.168.189.9:39335) with 1 cores
16/05/24 19:44:56 INFO cluster.SparkDeploySchedulerBackend: Granted executor ID app-20160524194455-0000/5 on hostPort 192.168.189.9:39335 with 1 cores, 1024.0 MB RAM
16/05/24 19:44:56 INFO client.AppClient$ClientEndpoint: Executor added: app-20160524194455-0000/6 on worker-20160524192004-192.168.189.7-54284 (192.168.189.7:54284) with 1 cores
16/05/24 19:44:56 INFO cluster.SparkDeploySchedulerBackend: Granted executor ID app-20160524194455-0000/6 on hostPort 192.168.189.7:54284 with 1 cores, 1024.0 MB RAM
16/05/24 19:44:56 INFO client.AppClient$ClientEndpoint: Executor added: app-20160524194455-0000/7 on worker-20160524192004-192.168.189.8-57247 (192.168.189.8:57247) with 1 cores
16/05/24 19:44:56 INFO cluster.SparkDeploySchedulerBackend: Granted executor ID app-20160524194455-0000/7 on hostPort 192.168.189.8:57247 with 1 cores, 1024.0 MB RAM
16/05/24 19:45:06 INFO client.AppClient$ClientEndpoint: Executor updated: app-20160524194455-0000/1 is now RUNNING
16/05/24 19:45:06 INFO client.AppClient$ClientEndpoint: Executor updated: app-20160524194455-0000/7 is now RUNNING
16/05/24 19:45:06 INFO client.AppClient$ClientEndpoint: Executor updated: app-20160524194455-0000/5 is now RUNNING
16/05/24 19:45:06 INFO client.AppClient$ClientEndpoint: Executor updated: app-20160524194455-0000/3 is now RUNNING
16/05/24 19:45:06 INFO client.AppClient$ClientEndpoint: Executor updated: app-20160524194455-0000/0 is now RUNNING
16/05/24 19:45:06 INFO client.AppClient$ClientEndpoint: Executor updated: app-20160524194455-0000/6 is now RUNNING
16/05/24 19:45:06 INFO client.AppClient$ClientEndpoint: Executor updated: app-20160524194455-0000/4 is now RUNNING
16/05/24 19:45:06 INFO client.AppClient$ClientEndpoint: Executor updated: app-20160524194455-0000/2 is now RUNNING
16/05/24 19:45:50 INFO client.AppClient$ClientEndpoint: Executor updated: app-20160524194455-0000/5 is now EXITED (Command exited with code 1)
16/05/24 19:45:50 INFO cluster.SparkDeploySchedulerBackend: Executor app-20160524194455-0000/5 removed: Command exited with code 1
16/05/24 19:45:50 INFO cluster.SparkDeploySchedulerBackend: Asked to remove non-existent executor 5
16/05/24 19:45:50 INFO client.AppClient$ClientEndpoint: Executor added: app-20160524194455-0000/8 on worker-20160524192008-192.168.189.9-39335 (192.168.189.9:39335) with 1 cores
16/05/24 19:45:50 INFO cluster.SparkDeploySchedulerBackend: Granted executor ID app-20160524194455-0000/8 on hostPort 192.168.189.9:39335 with 1 cores, 1024.0 MB RAM
16/05/24 19:45:50 INFO client.AppClient$ClientEndpoint: Executor updated: app-20160524194455-0000/3 is now EXITED (Command exited with code 1)
16/05/24 19:45:50 INFO cluster.SparkDeploySchedulerBackend: Executor app-20160524194455-0000/3 removed: Command exited with code 1
16/05/24 19:45:50 INFO cluster.SparkDeploySchedulerBackend: Asked to remove non-existent executor 3
16/05/24 19:45:50 INFO client.AppClient$ClientEndpoint: Executor added: app-20160524194455-0000/9 on worker-20160524192004-192.168.189.2-36469 (192.168.189.2:36469) with 1 cores
16/05/24 19:45:50 INFO cluster.SparkDeploySchedulerBackend: Granted executor ID app-20160524194455-0000/9 on hostPort 192.168.189.2:36469 with 1 cores, 1024.0 MB RAM
16/05/24 19:45:50 INFO client.AppClient$ClientEndpoint: Executor updated: app-20160524194455-0000/7 is now EXITED (Command exited with code 1)
16/05/24 19:45:50 INFO cluster.SparkDeploySchedulerBackend: Executor app-20160524194455-0000/7 removed: Command exited with code 1
16/05/24 19:45:50 INFO cluster.SparkDeploySchedulerBackend: Asked to remove non-existent executor 7
.......
.......
16/05/24 19:57:16 INFO scheduler.TaskSetManager: Starting task 197.0 in stage 304.0 (TID 5764, worker2, partition 198,NODE_LOCAL, 2363 bytes)
16/05/24 19:57:16 INFO scheduler.TaskSetManager: Finished task 196.0 in stage 304.0 (TID 5763) in 46 ms on worker2 (197/199)
16/05/24 19:57:16 INFO scheduler.TaskSetManager: Starting task 198.0 in stage 304.0 (TID 5765, worker2, partition 199,NODE_LOCAL, 2363 bytes)
16/05/24 19:57:16 INFO scheduler.TaskSetManager: Finished task 197.0 in stage 304.0 (TID 5764) in 8 ms on worker2 (198/199)
16/05/24 19:57:16 INFO scheduler.TaskSetManager: Finished task 198.0 in stage 304.0 (TID 5765) in 5 ms on worker2 (199/199)
16/05/24 19:57:16 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 304.0, whose tasks have all completed, from pool
16/05/24 19:57:16 INFO scheduler.DAGScheduler: ResultStage 304 (show at OnlineTheTop3ItemForEachCategory2DB.scala:92) finished in 2.666 s
16/05/24 19:57:16 INFO scheduler.DAGScheduler: Job 118 finished: show at OnlineTheTop3ItemForEachCategory2DB.scala:92, took 2.677215 s
输入流处理的数据
root@master:~# nc -lk 9999
mike,huawei,androidphone
jim,xiaomi,androidphone
jaker,apple,applephone
lili,samsung,androidphone
zhangsan,samsung,androidpad
lisi,samsung,androidpad
peter,samsung,androidpad
jack,apple,applephone
hehe,apple,applephone
lina,apple,applephone
liuxiang,apple,appleppad
liuxiang,meizu,androidphone
liuxiang,huawei,androidpad
liuxiang,leshi,androidphone
liuxiang,leshi,androidpad
liuxiang,xiaomi,androidpad
mike,huawei,androidphone
jim,xiaomi,androidphone
jaker,apple,applephone
运行的结果
16/05/24 20:14:30 INFO scheduler.TaskSetManager: Finished task 196.0 in stage 196.0 (TID 3519) in 10 ms on worker2 (197/199)
16/05/24 20:14:30 INFO scheduler.TaskSetManager: Starting task 198.0 in stage 196.0 (TID 3521, worker2, partition 199,NODE_LOCAL, 2363 bytes)
16/05/24 20:14:30 INFO scheduler.TaskSetManager: Finished task 197.0 in stage 196.0 (TID 3520) in 12 ms on worker2 (198/199)
16/05/24 20:14:30 INFO scheduler.TaskSetManager: Finished task 198.0 in stage 196.0 (TID 3521) in 10 ms on worker2 (199/199)
16/05/24 20:14:30 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 196.0, whose tasks have all completed, from pool
16/05/24 20:14:30 INFO scheduler.DAGScheduler: ResultStage 196 (show at OnlineTheTop3ItemForEachCategory2DB.scala:92) finished in 1.892 s
16/05/24 20:14:30 INFO scheduler.DAGScheduler: Job 75 finished: show at OnlineTheTop3ItemForEachCategory2DB.scala:92, took 1.915228 s
+------------+-------+-----------+
| category| item|click_count|
+------------+-------+-----------+
|androidphone| xiaomi| 4|
|androidphone|samsung| 4|
|androidphone| huawei| 4|
| appleppad| apple| 3|
| applephone| apple| 13|
| androidpad|samsung| 9|
| androidpad| xiaomi| 4|
| androidpad| huawei| 3|
+------------+-------+-----------+
=====================resultRowRDD20160523!!!!!===============
16/05/24 20:14:30 INFO spark.SparkContext: Starting job: take at OnlineTheTop3ItemForEachCategory2DB.scala:97
16/05/24 20:14:30 INFO scheduler.DAGScheduler: Registering RDD 259 (rdd at OnlineTheTop3ItemForEachCategory2DB.scala:94)
16/05/24 20:14:30 INFO scheduler.DAGScheduler: Got job 76 (take at OnlineTheTop3ItemForEachCategory2DB.scala:97) with 1 output partitions
16/05/24 20:14:30 INFO scheduler.DAGScheduler: Final stage: ResultStage 198 (take at OnlineTheTop3ItemForEachCategory2DB.scala:97)
16/05/24 20:14:30 INFO scheduler.DAGScheduler: Parents of final stage: List(ShuffleMapStage 197)
16/05/24 20:14:30 INFO scheduler.DAGScheduler: Missing parents: List(ShuffleMapStage 197)
16/05/24 20:14:30 INFO scheduler.DAGScheduler: Submitting ShuffleMapStage 197 (MapPartitionsRDD[259] at rdd at OnlineTheTop3ItemForEachCategory2DB.scala:94), which has no missing parents
16/05/24 20:14:30 INFO storage.MemoryStore: Block broadcast_113 stored as values in memory (estimated size 10.2 KB, free 2020.8 KB)
16/05/24 20:14:30 INFO storage.MemoryStore: Block broadcast_113_piece0 stored as bytes in memory (estimated size 5.2 KB, free 2026.0 KB)
16/05/24 20:14:30 INFO storage.BlockManagerInfo: Added broadcast_113_piece0 in memory on 192.168.189.1:50976 (size: 5.2 KB, free: 510.9 MB)
16/05/24 20:14:30 INFO spark.SparkContext: Created broadcast 113 from broadcast at DAGScheduler.scala:1006
16/05/24 20:14:30 INFO scheduler.DAGScheduler: Submitting 8 missing tasks from ShuffleMapStage 197 (MapPartitionsRDD[259] at rdd at OnlineTheTop3ItemForEachCategory2DB.scala:94)
16/05/24 20:14:30 INFO scheduler.TaskSchedulerImpl: Adding task set 197.0 with 8 tasks
mysql中验证
mysql> select * from categorytop3 ;
+-----------------+------------+--------------+
| category | item | client_count |
+-----------------+------------+--------------+
| androidphone | samsung | 16 |
| androidphone | samsung | 106 |
| androidphone | samsung | 100 |
| androidphone | samsung | 100 |
| androidphone | samsung | 100 |
| androidphone | samsung | 100 |
| androidphone | samsung | 100 |
| IMFandroidphone | IMFsamsung | 100 |
.......
| androidphone | leshi | 0 |
| androidpad | xiaomi | 0 |
| applephone | apple | 0 |
| androidphone | huawei | 4 |
| androidphone | samsung | 4 |
| androidphone | xiaomi | 4 |
| androidphone | xiaomi | 14 |
| androidphone | leshi | 14 |
| androidphone | meizu | 14 |
| androidphone | meizu | 22 |
| androidphone | huawei | 22 |
| androidphone | samsung | 22 |
| androidphone | meizu | 25 |
| androidphone | leshi | 25 |
| androidphone | huawei | 24 |
| androidphone | samsung | 14 |
| androidphone | meizu | 14 |
| androidphone | xiaomi | 14 |
+-----------------+------------+--------------+
83 rows in set (0.00 sec)OnlineTheTop3ItemForEachCategory2DB .scala
/**
* 使用Spark Streaming+Spark SQL来在线动态计算电商中不同类别中最热门的商品排名,例如手机这个类别下面最热门的三种手机、电视这个类别
* 下最热门的三种电视,该实例在实际生产环境下具有非常重大的意义;
*
* @author DT大数据梦工厂
* 新浪微博:http://weibo.com/ilovepains/
*
*
* 实现技术:Spark Streaming+Spark SQL,之所以Spark Streaming能够使用ML、sql、graphx等功能是因为有foreachRDD和Transform
* 等接口,这些接口中其实是基于RDD进行操作,所以以RDD为基石,就可以直接使用Spark其它所有的功能,就像直接调用API一样简单。
* 假设说这里的数据的格式:user item category,例如Rocky Samsung Android
*/
object OnlineTheTop3ItemForEachCategory2DB {
def main(args: Array[String]){
/**
* 第1步:创建Spark的配置对象SparkConf,设置Spark程序的运行时的配置信息,
* 例如说通过setMaster来设置程序要链接的Spark集群的Master的URL,如果设置
* 为local,则代表Spark程序在本地运行,特别适合于机器配置条件非常差(例如
* 只有1G的内存)的初学者 *
*/
val conf = new SparkConf() //创建SparkConf对象
conf.setAppName("OnlineTheTop3ItemForEachCategory2DB") //设置应用程序的名称,在程序运行的监控界面可以看到名称
// conf.setMaster("spark://Master:7077") //此时,程序在Spark集群
conf.setMaster("local[6]")
//设置batchDuration时间间隔来控制Job生成的频率并且创建Spark Streaming执行的入口
val ssc = new StreamingContext(conf, Seconds(5))
ssc.checkpoint("/root/Documents/SparkApps/checkpoint")
val userClickLogsDStream = ssc.socketTextStream("Master", 9999)
val formattedUserClickLogsDStream = userClickLogsDStream.map(clickLog =>
(clickLog.split(" ")(2) + "_" + clickLog.split(" ")(1), 1))
// val categoryUserClickLogsDStream = formattedUserClickLogsDStream.reduceByKeyAndWindow((v1:Int, v2: Int) => v1 + v2,
// (v1:Int, v2: Int) => v1 - v2, Seconds(60), Seconds(20))
val categoryUserClickLogsDStream = formattedUserClickLogsDStream.reduceByKeyAndWindow(_+_,
_-_, Seconds(60), Seconds(20))
categoryUserClickLogsDStream.foreachRDD { rdd => {
if (rdd.isEmpty()) {
println("No data inputted!!!")
} else {
val categoryItemRow = rdd.map(reducedItem => {
.......
Row(category, item, click_count)
})
val structType = StructType(Array(
StructField("category", StringType, true),
StructField("item", StringType, true),
StructField("click_count", IntegerType, true)
))
val hiveContext = new HiveContext(rdd.context)
val categoryItemDF = hiveContext.createDataFrame(categoryItemRow, structType)
categoryItemDF.registerTempTable("categoryItemTable")
val reseltDataFram = hiveContext.sql("SELECT category,item,click_count FROM .......)
reseltDataFram.show()
val resultRowRDD = reseltDataFram.rdd
resultRowRDD.foreachPartition { partitionOfRecords => {
if (partitionOfRecords.isEmpty){
println("This RDD is not null but partition is null")
} else {
// ConnectionPool is a static, lazily initialized pool of connections
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => {
val sql = "insert into categorytop3.........)"
val stmt = connection.createStatement();
stmt.executeUpdate(sql);
})
ConnectionPool.returnConnection(connection) // return to the pool for future reuse
}
}
}
}
}
}
/**
* 在StreamingContext调用start方法的内部其实是会启动JobScheduler的Start方法,进行消息循环,在JobScheduler
* 的start内部会构造JobGenerator和ReceiverTacker,并且调用JobGenerator和ReceiverTacker的start方法:
* 1,JobGenerator启动后会不断的根据batchDuration生成一个个的Job
* 2,ReceiverTracker启动后首先在Spark Cluster中启动Receiver(其实是在Executor中先启动ReceiverSupervisor),在Receiver收到
* 数据后会通过ReceiverSupervisor存储到Executor并且把数据的Metadata信息发送给Driver中的ReceiverTracker,在ReceiverTracker
* 内部会通过ReceivedBlockTracker来管理接受到的元数据信息
* 每个BatchInterval会产生一个具体的Job,其实这里的Job不是Spark Core中所指的Job,它只是基于DStreamGraph而生成的RDD
* 的DAG而已,从Java角度讲,相当于Runnable接口实例,此时要想运行Job需要提交给JobScheduler,在JobScheduler中通过线程池的方式找到一个
* 单独的线程来提交Job到集群运行(其实是在线程中基于RDD的Action触发真正的作业的运行),为什么使用线程池呢?
* 1,作业不断生成,所以为了提升效率,我们需要线程池;这和在Executor中通过线程池执行Task有异曲同工之妙;
* 2,有可能设置了Job的FAIR公平调度的方式,这个时候也需要多线程的支持;
*
*/
ssc.start()
ssc.awaitTermination()
}
}ConnectionPool .java
public class ConnectionPool {
private static LinkedList connectionQueue;
static {
try {
Class.forName("com.mysql.jdbc.Driver");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
public synchronized static Connection getConnection() {
try {
if(connectionQueue == null) {
connectionQueue = new LinkedList();
for(int i = 0; i < 5; i++) {
Connection conn = DriverManager.getConnection(.......);
connectionQueue.push(conn);
}
}
} catch (Exception e) {
e.printStackTrace();
}
return connectionQueue.poll();
}
public static void returnConnection(Connection conn) {
connectionQueue.push(conn);
}
}运行截图



王家林老师 :DT大数据梦工厂创始人和首席专家。
联系邮箱:[email protected] 电话:18610086859 QQ:1740415547
微信号:18610086859 微博:http://weibo.com/ilovepains/
每天晚上20:00YY频道现场授课频道68917580
IMF Spark源代码版本定制班学员 :
上海-段智华 QQ:1036179833 mail:[email protected] 微信 18918561505