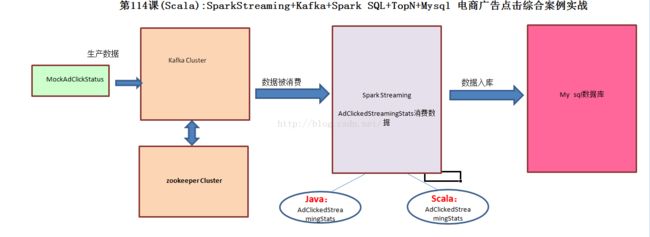
第114课(Scala版本)SparkStreaming+Kafka+Spark SQL+TopN+Mysql 电商广告点击综合案例实战
114课程 scala 版本开始了



114 scala 改写的很java ,请读者谅解
1. 114重写了scala代码
2. 在虚拟机master 下载 安装scalaide
3 导入spark kafka spark streaming的 jar包
4. 先改写第一个功能模块 黑名单识别
遇到的问题及解决:
1.找不到kafka的jar 重新加载了一次
2. 找不到类,改代码 setjar,将 spark kafka的包 全部加上
3.运行报序列化错误,114的scala代码中 和java的语法搞混了 ,scala直接返回true false就可以了,不用return;
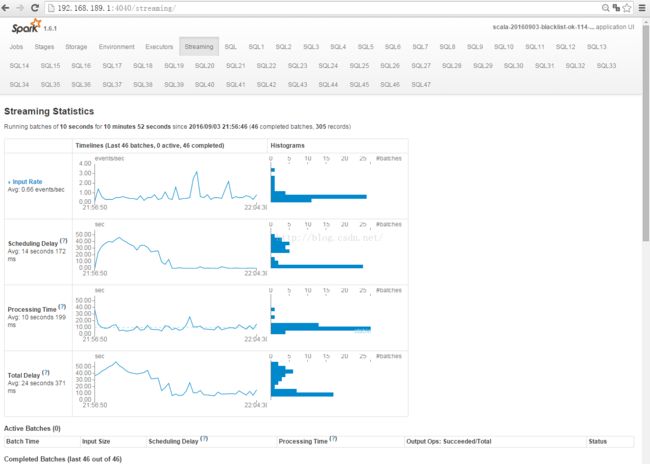
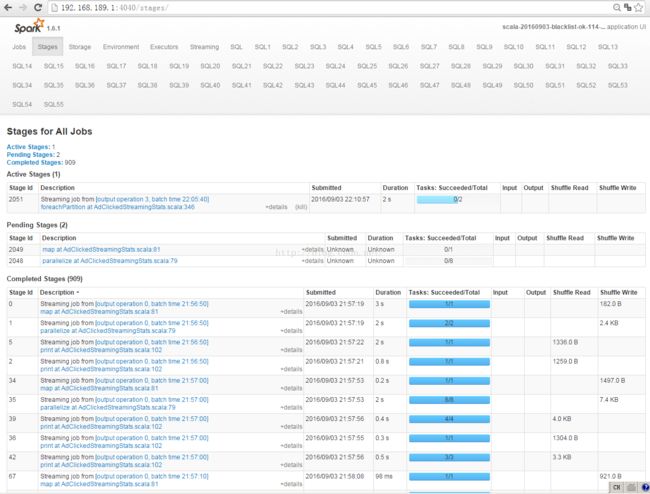
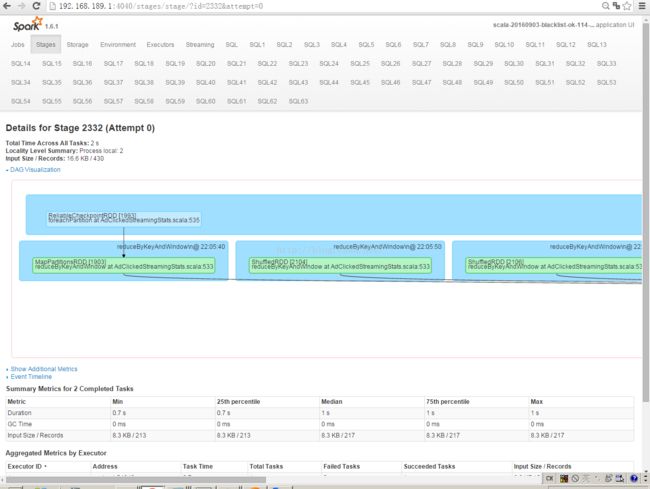
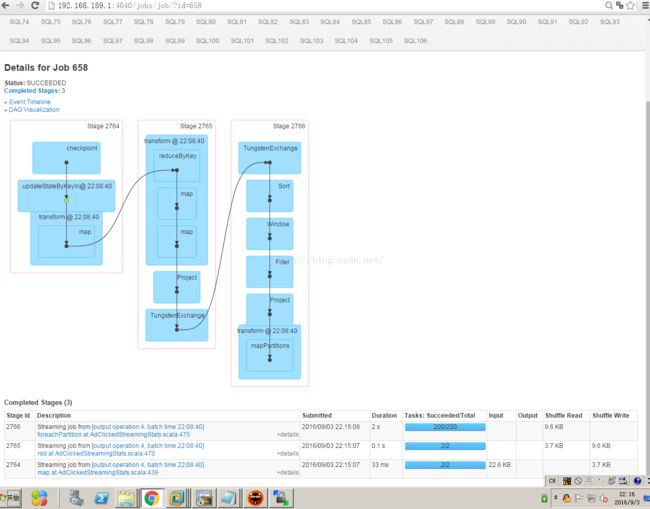
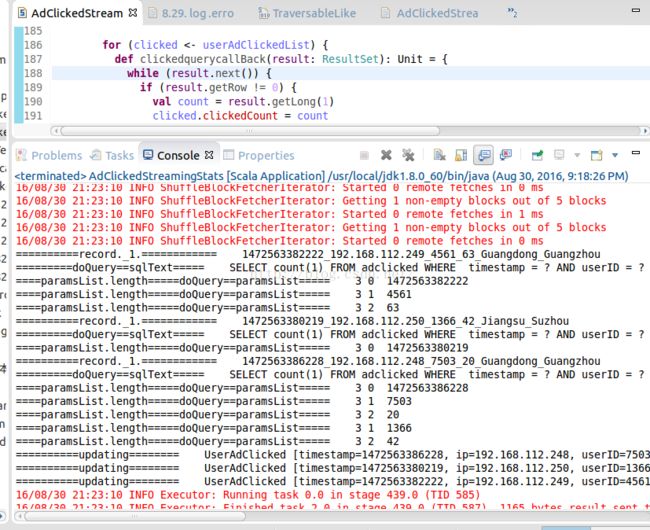
运行结果


root@master:/usr/local/spark-1.6.1-bin-hadoop2.6/sbin# service mysql stop
mysql stop/waiting
root@master:/usr/local/spark-1.6.1-bin-hadoop2.6/sbin# service mysql start
mysql start/running, process 12025
root@master:/usr/local/spark-1.6.1-bin-hadoop2.6/sbin# mysql -uroot -proot
ERROR 1040 (HY000): Too many connections
root@master:/usr/local/spark-1.6.1-bin-hadoop2.6/sbin# mysql -uroot -proot
ERROR 1040 (HY000): Too many connections
root@master:/usr/local/spark-1.6.1-bin-hadoop2.6/sbin# mysqladmin -uroot -proot processlist
mysqladmin: connect to server at 'localhost' failed
error: 'Too many connections'
root@master:/usr/local/spark-1.6.1-bin-hadoop2.6/sbin# mysqladmin -uroot -proot processlist
mysqladmin: connect to server at 'localhost' failed
error: 'Too many connections'
root@master:/usr/local/spark-1.6.1-bin-hadoop2.6/sbin# mysqladmin -uroot -proot processlist
mysqladmin: connect to server at 'localhost' failed
error: 'Too many connections'
root@master:/usr/local/spark-1.6.1-bin-hadoop2.6/sbin#
问题解决:
单例模式
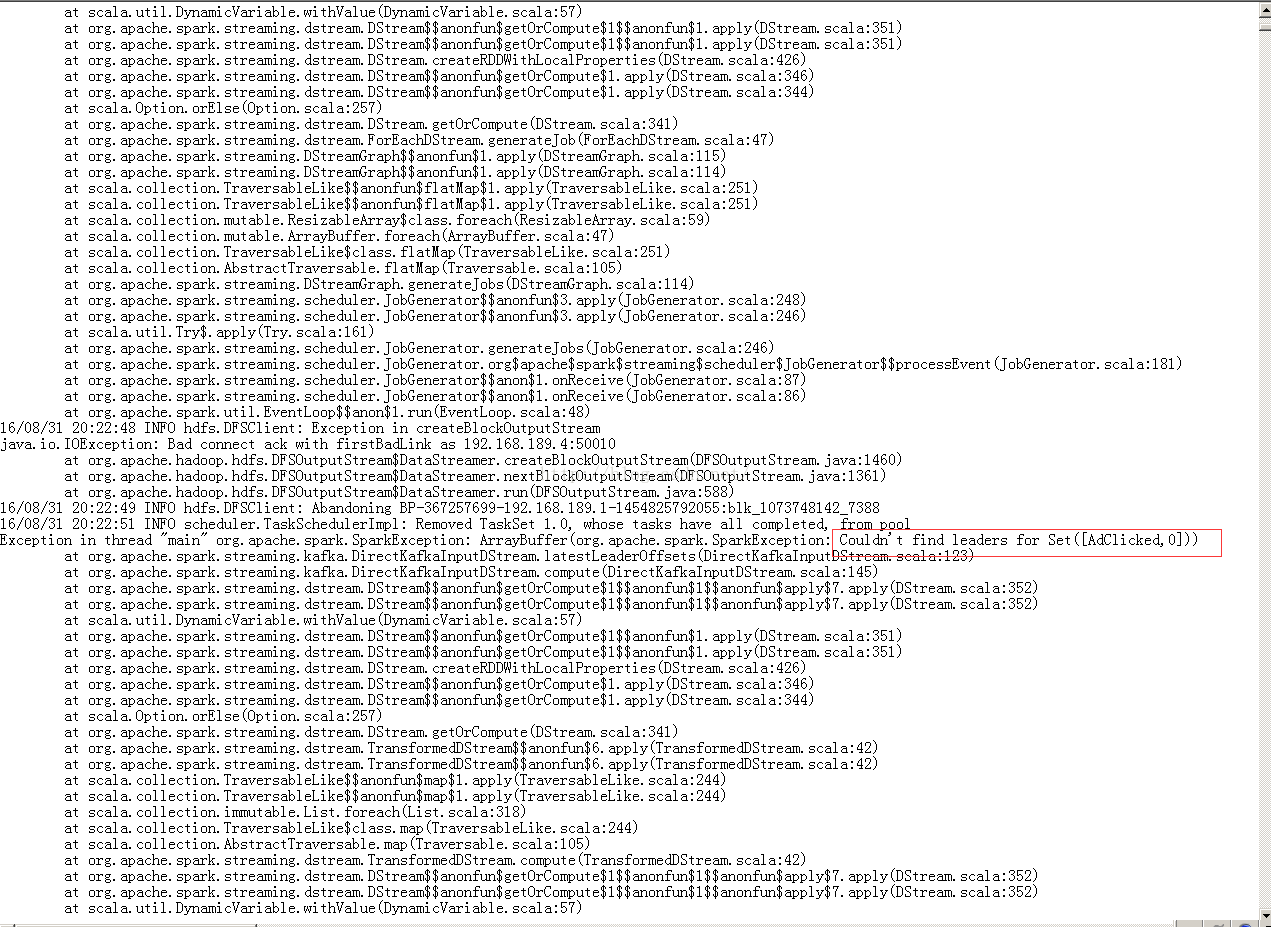
问题 kafka找不到leader
16/08/31 20:32:40 ERROR JobScheduler: Error generating jobs for time 1472646760000 ms
org.apache.spark.SparkException: ArrayBuffer(org.apache.spark.SparkException: Couldn't find leaders for Set([AdClicked,0]))
at org.apache.spark.streaming.kafka.DirectKafkaInputDStream.latestLeaderOffsets(DirectKafkaInputDStream.scala:123)
at org.apache.spark.streaming.kafka.DirectKafkaInputDStream.compute(DirectKafkaInputDStream.scala:145)
at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1$$anonfun$apply$7.apply(DStream.scala:352)
at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1$$anonfun$apply$7.apply(DStream.scala:352)
at scala.util.DynamicVariable.withValue(DynamicVariable.scala:57)
at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1.apply(DStream.scala:351)
问题解决 :kafka重启,重新建立topic
producer.send( new KeyedMessage("ScalaAdClicked",clickedAd));
/usr/local/kafka_2.10-0.8.2.1/bin/kafka-topics.sh --create --zookeeper master:2181,worker1:2181,worker2:2181 --replication-factor 1 --partitions 1 --topic ScalaAdClicked
/usr/local/kafka_2.10-0.8.2.1/bin/kafka-topics.sh --list --zookeeper master:2181,worker1:2181,worker2:2181
root@worker1:/usr/local/kafka_2.10-0.8.2.1/bin# kafka-topics.sh --delete --zookeeper master:2181,worker1:2181,worker2:2181 --topic ScalaAdClicked
Topic ScalaAdClicked is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
ScalaAdClicked
root@worker1:/usr/local/kafka_2.10-0.8.2.1/bin# kafka-topics.sh --create --zookeeper master:2181,worker1:2181,worker2:2181 --replication-factor 1 --partitions 1 --topic IMFScalaAdClicked
Created topic "IMFScalaAdClicked".
kill -9
root@worker1:/usr/local/setup_scripts# kafka-console-producer.sh --broker-list master:9092,worker1:9092,worker2:9092 --topic IMFScalaAdClicked
[2016-08-31 21:34:04,467] WARN Property topic is not valid (kafka.utils.VerifiableProperties)
dfg
dfg
gfh
fgj
ghj
ghk
fggfjghjgfjgjfg
root@worker2:~# /usr/local/kafka_2.10-0.8.2.1/bin/kafka-console-consumer.sh --zookeeper master:2181,worker1:2181,worker2:2181 --from-beginning --topic IMFScalaAdClicked
dfg
dfg
gfh
fgj
ghj
ghk
fggfjghjgfjgjfg
16/09/03 15:31:52 INFO metastore.ObjectStore: Setting MetaStore object pin classes with hive.metastore.cache.pinobjtypes="Table,StorageDescriptor,SerDeInfo,Partition,Database,Type,FieldSchema,Order"
16/09/03 15:31:52 INFO DataNucleus.Datastore: The class "org.apache.hadoop.hive.metastore.model.MFieldSchema" is tagged as "embedded-only" so does not have its own datastore table.
16/09/03 15:31:52 INFO DataNucleus.Datastore: The class "org.apache.hadoop.hive.metastore.model.MOrder" is tagged as "embedded-only" so does not have its own datastore table.
16/09/03 15:32:28 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on worker2:50202 (size: 2014.0 B, free: 517.4 MB)
16/09/03 15:32:29 INFO storage.BlockManagerInfo: Added broadcast_1_piece0 in memory on worker3:42333 (size: 1150.0 B, free: 517.4 MB)
16/09/03 15:32:30 WARN scheduler.TaskSetManager: Lost task 0.0 in stage 0.0 (TID 0, worker2): java.lang.ClassNotFoundException: com.dt.spark.streaming114.AdClickedStreamingStats$$anonfun$6$$anonfun$7
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at org.apache.spark.serializer.JavaDeserializationStream$$anon$1.resolveClass(JavaSerializer.scala:68)
at java.io.ObjectInputStream.readNonProxyDesc(ObjectInputStream.java:1613)
at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1518)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1774)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1351)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:2000)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1924)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1801)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1351)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:2000)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1924)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1801)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1351)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:2000)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1924)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1801)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1351)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:371)
at org.apache.spark.serializer.JavaDeserializationStream.readObject(JavaSerializer.scala:76)
at org.apache.spark.serializer.JavaSerializerInstance.deserialize(JavaSerializer.scala:115)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:64)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:41)
at org.apache.spark.scheduler.Task.run(Task.scala:89)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:214)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
java.lang.IndexOutOfBoundsException: 1
at scala.collection.mutable.ListBuffer.apply(ListBuffer.scala:120)
at com.dt.spark.streaming114.AdClickedStreamingStats$JDBCWrapper$$anonfun$doBatch$1$$anonfun$apply$2.apply$mcVI$sp(AdClickedStreamingStats.scala:607)
at scala.collection.immutable.Range.foreach$mVc$sp(Range.scala:141)
at com.dt.spark.streaming114.AdClickedStreamingStats$JDBCWrapper$$anonfun$doBatch$1.apply(AdClickedStreamingStats.scala:605)
at com.dt.spark.streaming114.AdClickedStreamingStats$JDBCWrapper$$anonfun$doBatch$1.apply(AdClickedStreamingStats.scala:604)
at scala.collection.immutable.List.foreach(List.scala:318)
at scala.collection.generic.TraversableForwarder$class.foreach(TraversableForwarder.scala:32)
at scala.collection.mutable.ListBuffer.foreach(ListBuffer.scala:45)
at com.dt.spark.streaming114.AdClickedStreamingStats$JDBCWrapper.doBatch(AdClickedStreamingStats.scala:604)
at com.dt.spark.streaming114.AdClickedStreamingStats$$anonfun$main$1$$anonfun$apply$5.apply(AdClickedStreamingStats.scala:229)
at com.dt.spark.streaming114.AdClickedStreamingStats$$anonfun$main$1$$anonfun$apply$5.apply(AdClickedStreamingStats.scala:159)
at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$33.apply(RDD.scala:920)
at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$33.apply(RDD.scala:920)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:1858)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:1858)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:66)
at org.apache.spark.scheduler.Task.run(Task.scala:89)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:214)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
java.lang.IndexOutOfBoundsException: 4
at scala.collection.mutable.ListBuffer.apply(ListBuffer.scala:120)
at com.dt.spark.streaming114.AdClickedStreamingStats$JDBCWrapper$$anonfun$doBatch$1$$anonfun$apply$2.apply$mcVI$sp(AdClickedStreamingStats.scala:607)
at scala.collection.immutable.Range.foreach$mVc$sp(Range.scala:141)
at com.dt.spark.streaming114.AdClickedStreamingStats$JDBCWrapper$$anonfun$doBatch$1.apply(AdClickedStreamingStats.scala:605)
at com.dt.spark.streaming114.AdClickedStreamingStats$JDBCWrapper$$anonfun$doBatch$1.apply(AdClickedStreamingStats.scala:604)
at scala.collection.immutable.List.foreach(List.scala:318)
at scala.collection.generic.TraversableForwarder$class.foreach(TraversableForwarder.scala:32)
at scala.collection.mutable.ListBuffer.foreach(ListBuffer.scala:45)
at com.dt.spark.streaming114.AdClickedStreamingStats$JDBCWrapper.doBatch(AdClickedStreamingStats.scala:604)
at com.dt.spark.streaming114.AdClickedStreamingStats$$anonfun$main$1$$anonfun$apply$5.apply(AdClickedStreamingStats.scala:229)
at com.dt.spark.streaming114.AdClickedStreamingStats$$anonfun$main$1$$anonfun$apply$5.apply(AdClickedStreamingStats.scala:159)
at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$33.apply(RDD.scala:920)
at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$33.apply(RDD.scala:920)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:1858)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:1858)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:66)
at org.apache.spark.scheduler.Task.run(Task.scala:89)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:214)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
16/08/27 21:04:00 INFO streaming.CheckpointWriter: Submitted checkpoint of time 1472303040000 ms writer queue
16/08/27 21:04:08 INFO streaming.CheckpointWriter: Deleting hdfs://master:9000/usr/local/IMF_testdata/IMFcheckpoint114/checkpoint-1471954880000
16/08/27 21:04:08 INFO streaming.CheckpointWriter: Checkpoint for time 1472303020000 ms saved to file 'hdfs://master:9000/usr/local/IMF_testdata/IMFcheckpoint114/checkpoint-1472303020000', took 4452 bytes and 14715 ms
16/08/27 21:04:08 INFO streaming.CheckpointWriter: Saving checkpoint for time 1472303030000 ms to file 'hdfs://master:9000/usr/local/IMF_testdata/IMFcheckpoint114/checkpoint-1472303030000'
com.mysql.jdbc.exceptions.jdbc4.MySQLNonTransientConnectionException: Data source rejected establishment of connection, message from server: "Too many connections"
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:422)
at com.mysql.jdbc.Util.handleNewInstance(Util.java:409)
at com.mysql.jdbc.Util.getInstance(Util.java:384)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:1015)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:989)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:984)
at com.mysql.jdbc.MysqlIO.doHandshake(MysqlIO.java:1104)
at com.mysql.jdbc.ConnectionImpl.connectOneTryOnly(ConnectionImpl.java:2312)
at com.mysql.jdbc.ConnectionImpl.createNewIO(ConnectionImpl.java:2122)
at com.mysql.jdbc.ConnectionImpl.(ConnectionImpl.java:774)
at com.mysql.jdbc.JDBC4Connection.(JDBC4Connection.java:49)
at sun.reflect.GeneratedConstructorAccessor17.newInstance(Unknown Source)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:422)
at com.mysql.jdbc.Util.handleNewInstance(Util.java:409)
at com.mysql.jdbc.ConnectionImpl.getInstance(ConnectionImpl.java:375)
at com.mysql.jdbc.NonRegisteringDriver.connect(NonRegisteringDriver.java:289)
at java.sql.DriverManager.getConnection(DriverManager.java:664)
at java.sql.DriverManager.getConnection(DriverManager.java:247)
at com.dt.spark.streaming114.AdClickedStreamingStats$JDBCWrapper$$anonfun$1.apply$mcVI$sp(AdClickedStreamingStats.scala:159)
at scala.collection.immutable.Range.foreach$mVc$sp(Range.scala:141)
at com.dt.spark.streaming114.AdClickedStreamingStats$JDBCWrapper.(AdClickedStreamingStats.scala:157)
at com.dt.spark.streaming114.AdClickedStreamingStats$$anonfun$2.apply(AdClickedStreamingStats.scala:53)
at com.dt.spark.streaming114.AdClickedStreamingStats$$anonfun$2.apply(AdClickedStreamingStats.scala:46)
at org.apache.spark.streaming.dstream.DStream$$anonfun$transform$1$$anonfun$apply$21.apply(DStream.scala:700)
at org.apache.spark.streaming.dstream.DStream$$anonfun$transform$1$$anonfun$apply$21.apply(DStream.scala:700)
at org.apache.spark.streaming.dstream.DStream$$anonfun$transform$2$$anonfun$5.apply(DStream.scala:714)
at org.apache.spark.streaming.dstream.DStream$$anonfun$transform$2$$anonfun$5.apply(DStream.scala:712)
at org.apache.spark.streaming.dstream.TransformedDStream.compute(TransformedDStream.scala:46)
at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1$$anonfun$apply$7.apply(DStream.scala:352)
16/08/29 20:55:14 INFO Executor: Finished task 4.0 in stage 39.0 (TID 51). 1165 bytes result sent to driver
16/08/29 20:55:14 INFO TaskSetManager: Finished task 4.0 in stage 39.0 (TID 51) in 489 ms on localhost (2/5)
java.lang.ArrayIndexOutOfBoundsException: 3
at scala.runtime.ScalaRunTime$.array_apply(ScalaRunTime.scala:71)
at com.dt.spark.streaming114.AdClickedStreamingStats$JDBCWrapper$$anonfun$doQuery$1.apply$mcVI$sp(AdClickedStreamingStats.scala:641)
at scala.collection.immutable.Range.foreach$mVc$sp(Range.scala:141)
at com.dt.spark.streaming114.AdClickedStreamingStats$JDBCWrapper.doQuery(AdClickedStreamingStats.scala:640)
at com.dt.spark.streaming114.AdClickedStreamingStats$$anonfun$main$1$$anonfun$apply$4$$anonfun$apply$5.apply(AdClickedStreamingStats.scala:196)
at com.dt.spark.streaming114.AdClickedStreamingStats$$anonfun$main$1$$anonfun$apply$4$$anonfun$apply$5.apply(AdClickedStreamingStats.scala:182)
at scala.collection.immutable.List.foreach(List.scala:318)
at scala.collection.generic.TraversableForwarder$class.foreach(TraversableForwarder.scala:32)
at scala.collection.mutable.ListBuffer.foreach(ListBuffer.scala:45)
at com.dt.spark.streaming114.AdClickedStreamingStats$$anonfun$main$1$$anonfun$apply$4.apply(AdClickedStreamingStats.scala:182)
at com.dt.spark.streaming114.AdClickedStreamingStats$$anonfun$main$1$$anonfun$apply$4.apply(AdClickedStreamingStats.scala:159)
at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$33.apply(RDD.scala:920)
at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$33.apply(RDD.scala:920)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:1858)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:1858)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:66)
at org.apache.spark.scheduler.Task.run(Task.scala:89)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:214)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
java.lang.ArrayIndexOutOfBoundsException: 3
at scala.runtime.ScalaRunTime$.array_apply(ScalaRunTime.scala:71)
16/09/03 20:13:27 INFO cluster.SparkDeploySchedulerBackend: Shutting down all executors
16/09/03 20:13:27 INFO cluster.SparkDeploySchedulerBackend: Asking each executor to shut down
16/09/03 20:13:28 ERROR scheduler.LiveListenerBus: SparkListenerBus has already stopped! Dropping event SparkListenerExecutorMetricsUpdate(1,WrappedArray())
16/09/03 20:13:28 INFO client.AppClient$ClientEndpoint: Executor updated: app-20160903201241-0004/7 is now FAILED (java.io.IOException: No space left on device)
16/09/03 20:13:28 INFO cluster.SparkDeploySchedulerBackend: Executor app-20160903201241-0004/7 removed: java.io.IOException: No space left on device
16/09/03 20:13:28 WARN netty.NettyRpcEndpointRef: Error sending message [message = RemoveExecutor(7,java.io.IOException: No space left on device)] in 1 attempts
org.apache.spark.SparkException: Could not find CoarseGrainedScheduler or it has been stopped.
at org.apache.spark.rpc.netty.Dispatcher.postMessage(Dispatcher.scala:161)
at org.apache.spark.rpc.netty.Dispatcher.postLocalMessage(Dispatcher.scala:126)
at org.apache.spark.rpc.netty.NettyRpcEnv.ask(NettyRpcEnv.scala:227)
at org.apache.spark.rpc.netty.NettyRpcEndpointRef.ask(NettyRpcEnv.scala:511)
at org.apache.spark.rpc.RpcEndpointRef.askWithRetry(RpcEndpointRef.scala:100)
at org.apache.spark.rpc.RpcEndpointRef.askWithRetry(RpcEndpointRef.scala:77)
at org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend.removeExecutor(CoarseGrainedSchedulerBackend.scala:359)
at org.apache.spark.scheduler.cluster.SparkDeploySchedulerBackend.executorRemoved(SparkDeploySchedulerBackend.scala:144)
at org.apache.spark.deploy.client.AppClient$ClientEndpoint$$anonfun$receive$1.applyOrElse(AppClient.scala:186)
at org.apache.spark.rpc.netty.Inbox$$anonfun$process$1.apply$mcV$sp(Inbox.scala:116)
at org.apache.spark.rpc.netty.Inbox.safelyCall(Inbox.scala:204)
at org.apache.spark.rpc.netty.Inbox.process(Inbox.scala:100)
at org.apache.spark.rpc.netty.Dispatcher$MessageLoop.run(Dispatcher.scala:215)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
16/09/03 20:13:12 INFO cluster.SparkDeploySchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.0
16/09/03 20:13:23 INFO utils.VerifiableProperties: Verifying properties
16/09/03 20:13:23 INFO utils.VerifiableProperties: Property group.id is overridden to
16/09/03 20:13:23 INFO utils.VerifiableProperties: Property zookeeper.connect is overridden to
16/09/03 20:13:24 INFO consumer.SimpleConsumer: Reconnect due to socket error: java.nio.channels.ClosedChannelException
Exception in thread "main" org.apache.spark.SparkException: org.apache.spark.SparkException: Couldn't find leaders for Set([IMFScalaAdClicked,0])
at org.apache.spark.streaming.kafka.KafkaCluster$$anonfun$checkErrors$1.apply(KafkaCluster.scala:366)
at org.apache.spark.streaming.kafka.KafkaCluster$$anonfun$checkErrors$1.apply(KafkaCluster.scala:366)
at scala.util.Either.fold(Either.scala:97)
at org.apache.spark.streaming.kafka.KafkaCluster$.checkErrors(KafkaCluster.scala:365)
at org.apache.spark.streaming.kafka.KafkaUtils$.getFromOffsets(KafkaUtils.scala:222)
at org.apache.spark.streaming.kafka.KafkaUtils$.createDirectStream(KafkaUtils.scala:484)
at com.dt.spark.streaming114.AdClickedStreamingStats$.main(AdClickedStreamingStats.scala:48)
at com.dt.spark.streaming114.AdClickedStreamingStats.main(AdClickedStreamingStats.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:731)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:181)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:206)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:121)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
mysql> select * from adprovincetopn limit 10 ;
+------------+------+----------+--------------+
| timestamp | adID | province | clickedCount |
+------------+------+----------+--------------+
| 2016-09-03 | 93 | Jiangsu | 5 |
| 2016-09-03 | 65 | Jiangsu | 4 |
| 2016-09-03 | 89 | Jiangsu | 4 |
| 2016-09-03 | 61 | Jiangsu | 4 |
| 2016-09-03 | 4 | Jiangsu | 3 |
| 2016-09-03 | 18 | Fujian | 5 |
| 2016-09-03 | 0 | Fujian | 4 |
| 2016-09-03 | 28 | Fujian | 4 |
| 2016-09-03 | 41 | Fujian | 4 |
| 2016-09-03 | 7 | Fujian | 4 |
+------------+------+----------+--------------+
10 rows in set (0.49 sec)
mysql> select * from adclickedtrend limit 10 ;
+---------------+---------------+---------------+------+--------------+
| date | hour | minute | adID | clickedCount |
+---------------+---------------+---------------+------+--------------+
| 1472875756481 | 1472875756481 | 1472875756481 | 81 | 1 |
| 1472875794559 | 1472875794559 | 1472875794559 | 71 | 1 |
| 1472875692339 | 1472875692339 | 1472875692339 | 46 | 1 |
| 1472875742455 | 1472875742455 | 1472875742455 | 2 | 1 |
| 1472875744457 | 1472875744457 | 1472875744457 | 5 | 1 |
| 1472875720391 | 1472875720391 | 1472875720391 | 82 | 1 |
| 1472875696344 | 1472875696344 | 1472875696344 | 47 | 1 |
| 1472875746465 | 1472875746465 | 1472875746465 | 7 | 1 |
| 1472875772517 | 1472875772517 | 1472875772517 | 18 | 1 |
| 1472875802576 | 1472875802576 | 1472875802576 | 84 | 1 |
+---------------+---------------+---------------+------+--------------+
10 rows in set (0.00 sec)
mysql> select * from adclickedcount limit 10 ;
+---------------+------+-----------+-----------+--------------+
| timestamp | adID | province | city | clickedCount |
+---------------+------+-----------+-----------+--------------+
| 1472868077139 | 25 | Jiangsu | WuXi | 1 |
| 1472868075138 | 34 | Zhejiang | Hangzhou | 1 |
| 1472868079140 | 4 | Guangdong | Shenzhen | 1 |
| 1472868113158 | 96 | Guangdong | DongGuan | 1 |
| 1472868109156 | 71 | Zhejiang | Wenzhou | 1 |
| 1472868089146 | 81 | Fujian | Fuzhou | 1 |
| 1472868121163 | 0 | Guangdong | Guangzhou | 1 |
| 1472868081141 | 63 | Fujian | Sanming | 1 |
| 1472868091147 | 55 | Fujian | Fuzhou | 1 |
| 1472868103153 | 87 | Fujian | Ximen | 1 |
+---------------+------+-----------+-----------+--------------+
10 rows in set (0.02 sec)
mysql> select * from adclicked limit 10 ;
+---------------+-----------------+--------+------+-----------+----------+--------------+
| timestamp | ip | userID | adID | province | city | clickedCount |
+---------------+-----------------+--------+------+-----------+----------+--------------+
| 1472867838979 | 192.168.112.254 | 6233 | 70 | Guangdong | Shenzhen | 0 |
| 1472867842981 | 192.168.112.248 | 657 | 96 | Jiangsu | Suzhou | 0 |
| 1472867846983 | 192.168.112.251 | 6864 | 64 | Jiangsu | WuXi | 0 |
| 1472867840980 | 192.168.112.239 | 1742 | 9 | Guangdong | Shenzhen | 0 |
| 1472867848984 | 192.168.112.252 | 333 | 47 | Fujian | Sanming | 0 |
| 1472867844982 | 192.168.112.254 | 7528 | 73 | Fujian | Fuzhou | 0 |
| 1472867852986 | 192.168.112.254 | 2162 | 70 | Jiangsu | Suzhou | 0 |
| 1472867854987 | 192.168.112.254 | 2976 | 29 | Jiangsu | Suzhou | 0 |
| 1472867858990 | 192.168.112.250 | 7361 | 57 | Zhejiang | Wenzhou | 0 |
| 1472867850985 | 192.168.112.251 | 4063 | 85 | Fujian | Sanming | 0 |
+---------------+-----------------+--------+------+-----------+----------+--------------+
10 rows in set (0.00 sec)
mysql> select * from blacklisttable limit 10 ;
+------+
| name |
+------+
| 7308 |
| 5984 |
| 4354 |
| 8894 |
| 4708 |
| 4430 |
| 6663 |
| 6424 |
| 1303 |
| 7128 |
+------+
10 rows in set (0.00 sec)