大数据Spark “蘑菇云”行动第39课:Spark中的Broadcast和Accumulator机制解密
大数据Spark “蘑菇云”行动第39课:Spark中的Broadcast和Accumulator机制解密
RDD: 分布式私有数据结构;
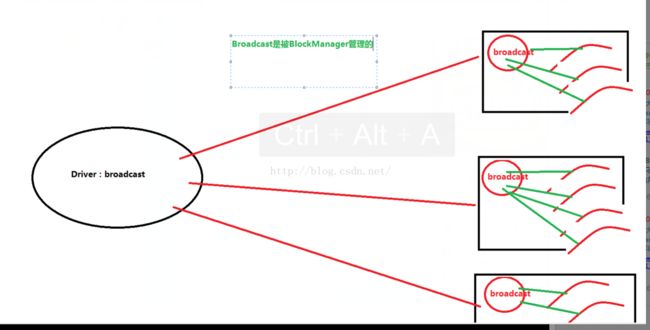
Broadcast:分布式全局只读数据结构;
Accumulator:分布式全局只写的数据结构;
在生产环境下,我们几乎一定会自定义Accumulator
1,自定义的时候可以让Accumulator非常复杂,基本上可以是任意类型的Java和Scala对象;
2,在自定义Accumulator的时候,我们可以实现一些“技术福利”,例如在Accumulator变化的时候可以把数据同步到MySQL中;
{{{
* scala> val accum = sc.accumulator(0)
* accum: org.apache.spark.Accumulator[Int] = 0
*
* scala> sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum += x)
* ...
* 10/09/29 18:41:08 INFO SparkContext: Tasks finished in 0.317106 s
*
* scala> accum.value
* res2: Int = 10
* }}}
* scala> val accum = sc.accumulator(0)
* accum: org.apache.spark.Accumulator[Int] = 0
*
* scala> sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum += x)
* ...
* 10/09/29 18:41:08 INFO SparkContext: Tasks finished in 0.317106 s
*
* scala> accum.value
* res2: Int = 10
* }}}
extends Accumulable[T, T](initialValue, param, name, countFailedValues)