Spark 大数据中文分词统计 (一) 开发环境搭建
几年前搞BI项目时就听说过大数据技术,当时也买了书,可惜没有认真去学。几年5月份
开始,报名参加王家林老师的大数据蘑菇云行动,才算真正开始学习Spark,学习大数据技术。
网上很多Spark的例子都是经典的WordCount example,可惜都是拿那个英文的readme
文件,分行分词统计,对于中文其实并不适用。所以便想着写一个能处理中文的WordCount,
对一些国学经典如唐诗三百首,宋词三百首等等,统计分析下,也算学以致用。经过半月努力,
总算基本实现了功能:
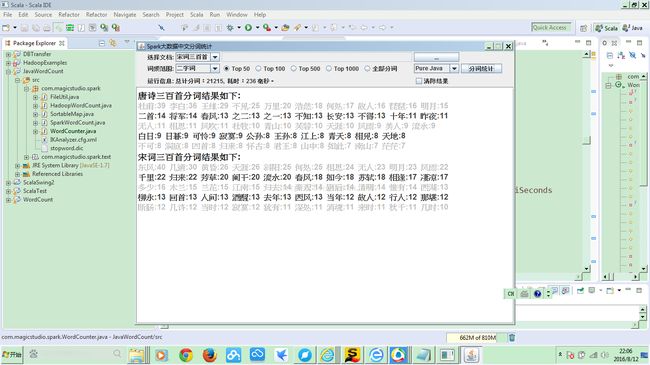
在此总结下,希望能和学习大数据或Spark的各位同学分享。
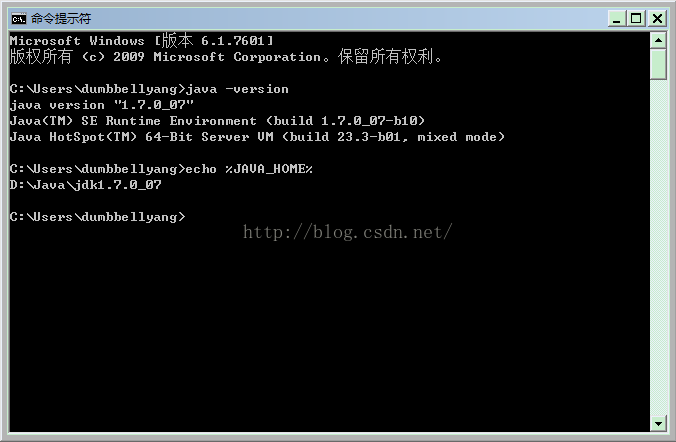
第一步当然是安装JDK 1.6以上版本,并设定JAVA_HOME环境变量。
因为Scala语言和Java语言都是基于JVM同根所生,而且Spark可以使用Java语言或Scala语言
开发,所以安装JDK是必须的。如下是我本地的安装及设定:
第二步安装Scala语言包及设定SCALA_HOME环境变量:
去Scala官网:http://www.scala-lang.org/ 下载安装相应的Scala语言版本。以下是我本地的安装及设定:

第三步下载安装Apache Spark的安装包并设定相应的环境变量:
下载地址:http://spark.apache.org/downloads.html 选择相应的Spark和hadoop版本,并要注意和Scala版本的对应关系。
下载后解压安装,并设定环境变量。我本地的设定如下:

启动Spark Shell,会显示Spark的版本是1.6.0.
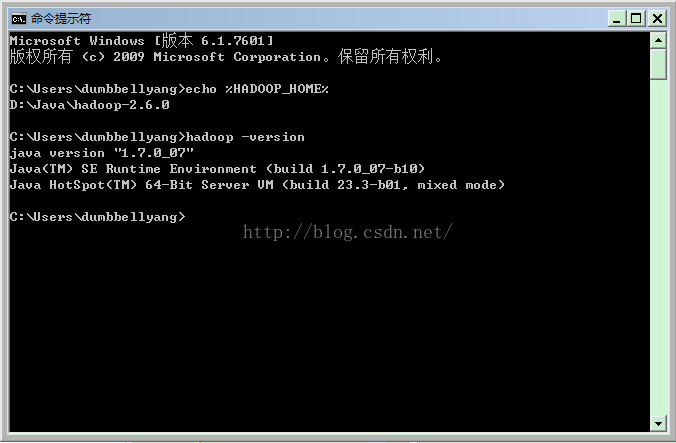
第四步,下载安装hadoop的安装编译包,需要注意32位和64位的差别已经hadoop的版本。
https://github.com/sdravida/hadoop2.6_Win_x64/tree/master/bin 这是hadoop 2.6版本 64位 windows
的安装包,其他版本请上网搜下。我本地的设定如下:
Spark的开发环境,可以有以下三种选择:
1. Scala-IDE 网址为 http://scala-ide.org/ 这是基于Scala官方基于Eclipse预装了Scala语
言各种组件的开发环境,下载后解压就可以直接使用来开发Scala项目,加入Spark的Library,
就可以开发Spark应用了。
Scala IDE打开后的界面如下:
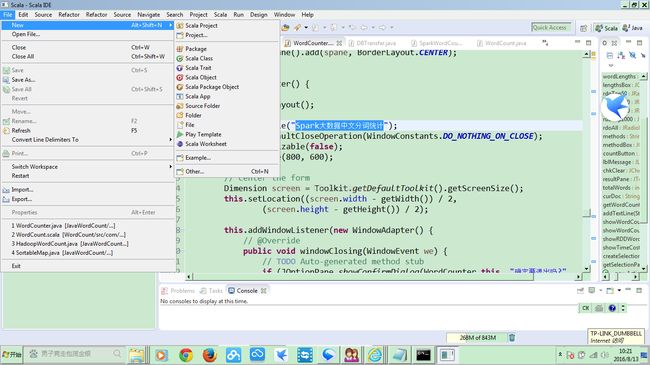
可以选择Scala项目,加入Scala class或trait进行Scala语言的开发。
当然Scala IDE还是可以开发Java应用的,因为本来Scala和Java就是基于JVM同根所生,并且可以相互调用的。
开发Java应用,选择New 弹出菜单最下面的Other:

这里,就可以选择建立其他类型的Java项目了。
2. 第二种开发环境的选择是Intellij IEDA 网址是 https://www.jetbrains.com/idea/
我们下载community 免费版就可以了。
据说Intellij IDEA是开发Java语言以及Scala语言最好的IDE,界面相当professional and cool:

下拉Configure,选择Pugins:

可以给Intellij IDEA安装各种开发插件,也包括Scala语言开发的插件:
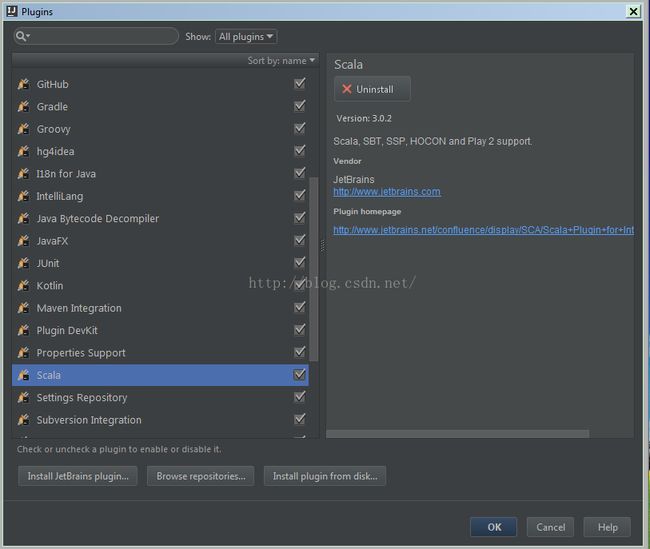
因为我已经安装过Scala语言包了,所以这里显示Uninstall,否则应该显示安装链接,直接点击就可以在线安装。安装完毕后,关闭窗口返回。
然后选择Create New Project:

可以看到,有Java Project,Scala Project甚至于Android 等等其他类型Project可供选择。
当然,要能创建其他类型 Project,必须先安装其必须的插件。
3. 第三种开发环境的选择是Eclipse + Scala插件,
自己下载Eclipse,解压打开后,在Help菜单中选择Install New Software,安装对应Eclipse版本的Scala开发插件:
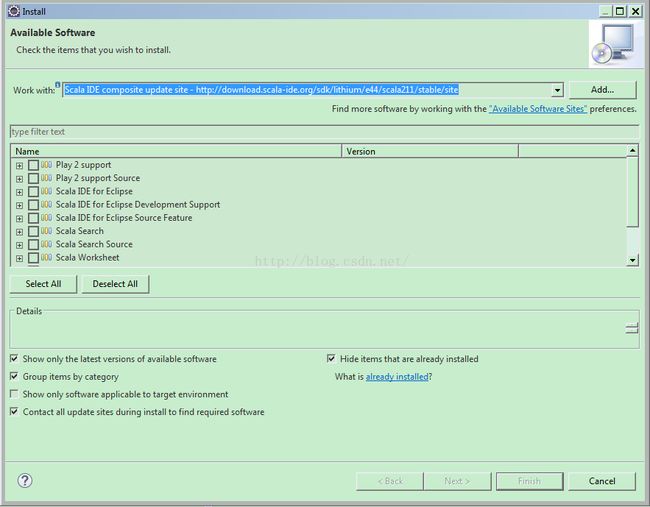
安装完毕后,重新进入Eclipse,就可以选择创建Scala Project,进行Scala语言的开发了:

这里有一点要注意,就是必须用新的从Eclipse官网下载到的Eclipse版本,才能连接到Scala 官网去安装Scala插件。
如果使用其他的定制过的Eclipse,例如Android Studio的Eclipse,是无法安装Scala插件的。
以上三种开发IDE的选择,第一种最为简单,所以我选择了第一种。
到这里,Windows 7下的Spark开发环境的搭建,就算完成了。
下一篇,我会先用Java开发Spark中文分词统计程序。