第217讲:Spark Shuffle中HashShuffleWriter工作机制和源码详解
第217讲:Spark Shuffle中HashShuffleWriter工作机制和源码详解
家林大神视频笔记记录,欢迎转载。
1,获取shuffleManager
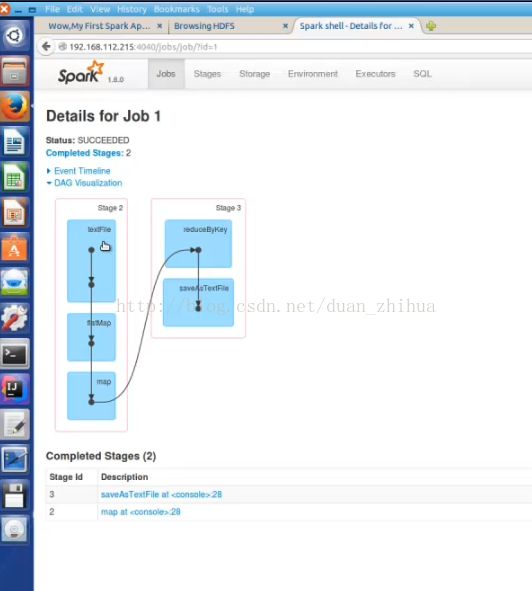
Spark Stage里面除了最后一个stage,前面都是map级别,图中Stage2里面的任务是ShuffleMapTask,而ShuffleMapTask的runTask方法要从SparkEnv里面找shuffleManager,获取shuffleManager。
override def runTask(context: TaskContext): MapStatus = {
// Deserialize the RDD using the broadcast variable.
val deserializeStartTime = System.currentTimeMillis()
val ser = SparkEnv.get.closureSerializer.newInstance()
val (rdd, dep) = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
_executorDeserializeTime = System.currentTimeMillis() - deserializeStartTime
metrics = Some(context.taskMetrics)
var writer: ShuffleWriter[Any, Any] = null
try {
val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
writer.stop(success = true).get
} 2,shuffleManager分成三种:HashShuffleManager, SortShuffleManager,tungsten-sort
// Let the user specify short names for shuffle managers
val shortShuffleMgrNames = Map(
"hash" -> "org.apache.spark.shuffle.hash.HashShuffleManager",
"sort" -> "org.apache.spark.shuffle.sort.SortShuffleManager",
"tungsten-sort" -> "org.apache.spark.shuffle.sort.SortShuffleManager")
val shuffleMgrName = conf.get("spark.shuffle.manager", "sort")
val shuffleMgrClass = shortShuffleMgrNames.getOrElse(shuffleMgrName.toLowerCase, shuffleMgrName)
val shuffleManager = instantiateClass[ShuffleManager](shuffleMgrClass)3,默认使用的是HashShuffleWriter,我们看一下HashShuffleWriter的 write方法
HashShuffleWriter的write方法将读入的rdd的Iterator作为任务的输出,输出到下一个stage读取。
先判断是否需聚合,如map端聚合,则进行combineValuesByKey,不聚合就返回records。然后for循环遍历,iter的格式类型是Iterator[Product2[K, Any]],第一个元素是key值,第二个元素是value;将key值的getPartition作为bucketId,然后将iter的每一个元素(key,value)写入到shuffle的文件中。
/** Write a bunch of records to this task's output */
override def write(records: Iterator[Product2[K, V]]): Unit = {
val iter = if (dep.aggregator.isDefined) {
if (dep.mapSideCombine) {
dep.aggregator.get.combineValuesByKey(records, context)
} else {
records
}
} else {
require(!dep.mapSideCombine, "Map-side combine without Aggregator specified!")
records
}
for (elem <- iter) {
val bucketId = dep.partitioner.getPartition(elem._1)
shuffle.writers(bucketId).write(elem._1, elem._2)
}
}
4,spark 1.6.0的DiskBlockObjectWriter 的write方法
/**
* Writes a key-value pair.
*/
def write(key: Any, value: Any) {
if (!initialized) {
open()
}
objOut.writeKey(key)
objOut.writeValue(value)
recordWritten()
}5,之前是FileShuffleBlockManager.scala,spark2.1.0是FileShuffleBlockResolver
forMapTask的用途:对于给定的map任务获得一个ShuffleWriterGroup,
当成功写入将进行注册。
/**
* Get a ShuffleWriterGroup for the given map task, which will register it as complete
* when the writers are closed successfully
*/
def forMapTask(shuffleId: Int, mapId: Int, numReducers: Int, serializer: Serializer,
writeMetrics: ShuffleWriteMetrics): ShuffleWriterGroup = {
new ShuffleWriterGroup {
shuffleStates.putIfAbsent(shuffleId, new ShuffleState(numReducers))
private val shuffleState = shuffleStates(shuffleId)
val openStartTime = System.nanoTime
val serializerInstance = serializer.newInstance()
val writers: Array[DiskBlockObjectWriter] = {
Array.tabulate[DiskBlockObjectWriter](numReducers) { bucketId =>
val blockId = ShuffleBlockId(shuffleId, mapId, bucketId)
val blockFile = blockManager.diskBlockManager.getFile(blockId)
val tmp = Utils.tempFileWith(blockFile)
blockManager.getDiskWriter(blockId, tmp, serializerInstance, bufferSize, writeMetrics)
}
}
// Creating the file to write to and creating a disk writer both involve interacting with
// the disk, so should be included in the shuffle write time.
writeMetrics.incShuffleWriteTime(System.nanoTime - openStartTime)
override def releaseWriters(success: Boolean) {
shuffleState.completedMapTasks.add(mapId)
}
}
}
6,HashShuffleWriter 通过 shuffleBlockResolver.forMapTask创建shuffle
private val shuffle: ShuffleWriterGroup = shuffleBlockResolver.forMapTask(dep.shuffleId, mapId, numOutputSplits, ser,
writeMetrics)/** A group of writers for a ShuffleMapTask, one writer per reducer. */
private[spark] trait ShuffleWriterGroup {
val writers: Array[DiskBlockObjectWriter]//数组里面是DiskBlockObjectWriter